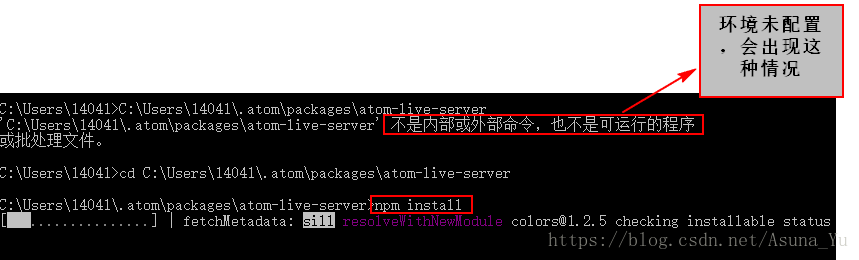
BCDBoot is a command-line tool used to configure the boot files on a PC or device to run the Windows operating system. You can use the tool in the following scenarios:
Add boot files to a PC after applying a new Windows image. In a typical image-based Windows deployment, use BCDBoot to set up the firmware and system partition to boot to your image. To learn more, see Capture and Apply Windows, System, and Recovery Partitions. Set up the PC to boot to a virtual hard disk (VHD) file that includes a Windows image. To learn more, see Boot to VHD (Native Boot): Add a Virtual Hard Disk to the Boot Menu. Repair the system partition. If the system partition has been corrupted, you can use BCDBoot to recreate the system partition files by using new copies of these files from the Windows partition. Set up or repair the boot menu on a dual-boot PC. If you’ve installed more than one copy of Windows on a PC, you can use BCDBoot to add or repair the boot menu. File Locations
| In Windows and Windows Preinstallation Environment (WinPE) | %WINDIR%\System32\BCDBoot.exe |
| In the Windows Assessment and Deployment Kit (Windows ADK): | C:\Program Files (x86)\Windows Kits\10\Assessment and Deployment Kit\Deployment Tools\amd64\BCDBoot\BCDBoot.exe |
Supported operating systems BCDBoot can copy boot environment files from images of Windows 10, Windows 8.1, Windows 8, Windows 7, Windows Vista, Windows Server 2016 Technical Preview, Windows Server 2012 R2, Windows Server 2012, Windows Server 2008 R2, or Windows Server 2008. How It Works To configure the system partition, BCDBoot copies a small set of boot-environment files from the installed Windows image to the system partition. BCDBoot can create a Boot Configuration Data (BCD) store on the system partition using the latest version of the Windows files:
BCDBoot creates a new BCD store and initialize the BCD boot-environment files on the system partition, including the Windows Boot Manager, using the %WINDIR%\System32\Config\BCD-Template file. New in Windows 10: During an upgrade, BCDBoot preserves any other existing boot entries, such as debugsettings, when creating the new store. Use the /c option to ignore the old settings and start fresh with a new BCD store. If there is already a boot entry for this Windows partition, by default, BCDBoot erases the old boot entry and its values. Use the /m option to retain the values from an existing boot entry when you update the system files. By default, BCDBoot moves the boot entry for the selected Windows partition to the top of the Windows Boot Manager boot order. Use the /d option to preserve the existing boot order. On UEFI PCs, BCDBoot can update the firmware entries in the device’s NVRAM:
BCDBoot adds a firmware entry in the NVRAM to point to the Windows Boot Manager. By default, this entry is placed as the first item in the boot list. Use the /p option to preserve the existing UEFI boot order. Use /addlast to add it to the bottom of the boot order list. Command-Line Options The following command-line options are available for BCDBoot.exe. BCDBOOT <source> [/l <locale>] [/s <volume-letter> [/f <firmware type>]] [/v] [/m [{OS Loader GUID}]] [/addlast or /p] [/d] [/c]
| Option | Description |
|---|---|
| <source> | Required. Specifies the location of the Windows directory to use as the source for copying boot-environment files. The following example initializes the system partition by using BCD files from the C:\Windows folder: Copy
|
| /l <locale> | Optional. Specifies the locale. The default is US English (en-us). The following example sets the default BCD locale to Japanese: Copy
|
| /s <volume letter> | Optional. Specifies the volume letter of the system partition. This option should not be used in typical deployment scenarios. Use this setting to specify a system partition when you are configuring a drive that will be booted on another computer, such as a USB flash drive or a secondary hard drive. UEFI: BCDBoot copies the boot files to either the EFI system partition, or the partition specified by the /s option. BCDBoot creates the BCD store in the same partition. By default, BCDBoot creates a Windows Boot Manager entry in the NVRAM on the firmware to identify the boot files on the system partition. If the /s option is used, then this entry is not created. Instead, BCDBoot relies on the default firmware settings to identify the boot files on the system partition. By the UEFI 2.3.1 spec, the default firmware settings should open the file: \efi\boot\bootx64. efi in the EFI System Partition (ESP). BIOS:
The following example copies BCD files from the C:\Windows folder to a system partition on a secondary hard drive that will be booted on another computer. The system partition on the secondary drive was assigned the volume letter S: Copy The following example creates boot entries on a USB flash drive with the volume letter S, including boot files to support either a UEFI-based or a BIOS-based computer: Copy |
| /f <firmware type> | Optional. Specifies the firmware type. Valid values include UEFI, BIOS, and ALL.On BIOS/MBR-based systems, the default value is BIOS. This option creates the \Boot directory on the system partition and copies all required boot-environment files to this directory. On UEFI/GPT-based systems, the default value is UEFI. This option creates the \Efi\Microsoft\Boot directory and copies all required boot-environment files to this directory. When you specify the ALL value, BCDBoot creates both the \Boot and the \Efi\Microsoft\Boot directories, and copies all required boot-environment files for BIOS and UEFI to these directories. If you specify the /f option, you must also specify the /s option to identify the volume letter of the system partition. The following example copies BCD files that support booting on either a UEFI-based or a BIOS-based computer from the C:\Windows folder to a USB flash drive that was assigned the volume letter S: Copy
|
| /v | Optional. Enables verbose mode. Example: Copy
|
| /m [{OS Loader GUID}] | Optional. Merges the values from an existing boot entry into a new boot entry. By default, this option merges only global objects. If you specify an OS Loader GUID, this option merges the loader object in the system template to produce a bootable entry. The following example merges the operating-system loader in the current BCD store that the specified GUID identifies in the new BCD store: Copy
|
| /addlast | Optional. Specifies that the Windows Boot Manager firmware entry should be added last. The default behavior is to add it first. Cannot be used with /p. Copy
|
| /p | Optional. Specifies that the existing Windows Boot Manager firmware entry position should be preserved in the UEFI boot order. If entry does not exist, a new entry is added in the first position. Cannot be used with /addlast. By default, during an upgrade BCDBoot moves the Windows Boot Manager to be the first entry in the UEFI boot order. Copy
|
| /d | Optional. Preserves the existing default operating system entry in the {bootmgr} object in Windows Boot Manager. Copy
|
| /c | Optional. Specifies that any existing BCD elements should not be migrated. New for Windows 10: By default, during an upgrade, BCD elements such as debugsettings or flightsigning are preserved. Copy
|
Repair the system partition If the system partition has been corrupted, you can use BCDBoot to recreate the system partition files by using new copies of these files from the Windows partition.
- Boot your PC to a command line. For example, boot to the Windows installation disk and press Shift+F10, or boot to Windows PE (WinPE: Create USB Bootable drive). Use Diskpart to determine which drive letter contains your Windows partition and system partition (
diskpart, list vol, exit). Optional: Format your system partition: format (drive letter of your system partition) /q Add a boot entry for your Windows partition: bcdboot D:\Windows Reboot the PC. Windows should appear. Set up or repair the boot menu on a dual-boot PC When setting up a PC to boot more than one operating system, you may sometimes lose the ability to boot into one of the operating systems. The BCDBoot option allows you to quickly add boot options for a Windows-based operating system. To set up a dual-boot PC:
- Install a separate hard drive or prepare a separate partition for each operating system. Install the operating systems. For example, if your PC has Windows 7, install Windows 10 onto the other hard drive or partition. Reboot the PC. The boot menus should appear with both operating systems listed. If both operating systems aren’t listed:
- Open a command line, either as an administrator from inside Windows, or by booting to a command line using the Windows installation media and pressing Shift+F10, or by booting to Windows PE (WinPE: Create USB Bootable drive). Add boot options for a Windows operating system. Copy
bcdboot D:\Windows
Reboot the PC. Now, the boot menu will show both menu options.
Troubleshooting For information about repairing the boot files on a PC with Windows XP and a more recent version of Windows such as Windows 7, see the Microsoft Knowledge Base Article 2277998. Related topics Capture and Apply Windows, System, and Recovery Partitions Configure BIOS/MBR-Based Hard Drive Partitions Configure UEFI/GPT-Based Hard Drive Partitions BCDedit Bootsect Command-Line Options Diskpart Command line syntax
 is a data box that doesn’t mean anything, but what you would expect, is the distribution of scores by sex.
is a data box that doesn’t mean anything, but what you would expect, is the distribution of scores by sex.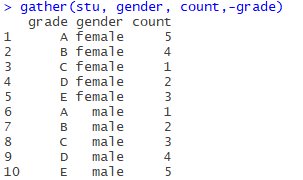
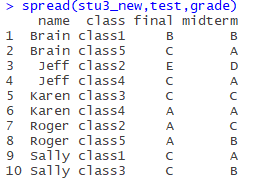
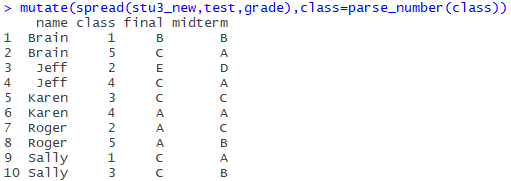
 is similar to stU above, with 1 and 2 after sex denoting classes
is similar to stU above, with 1 and 2 after sex denoting classes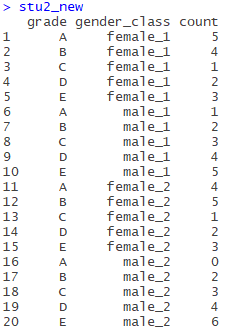
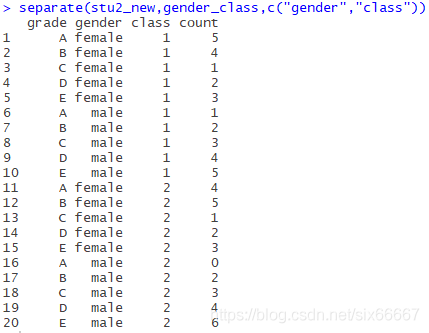
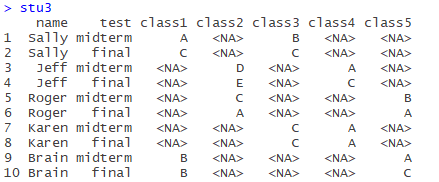
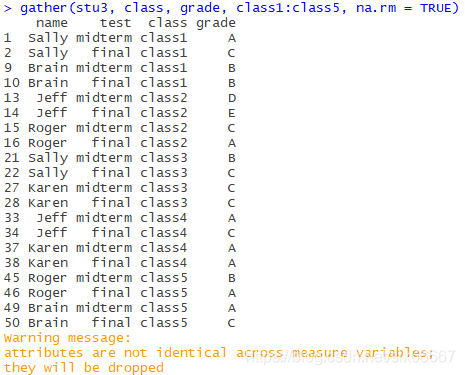
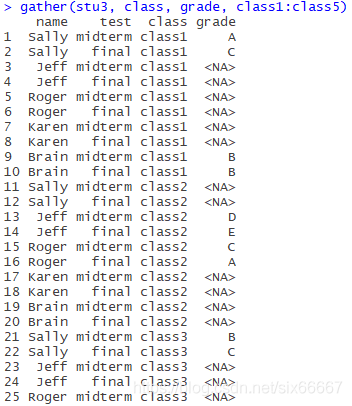 (Incomplete)
(Incomplete)