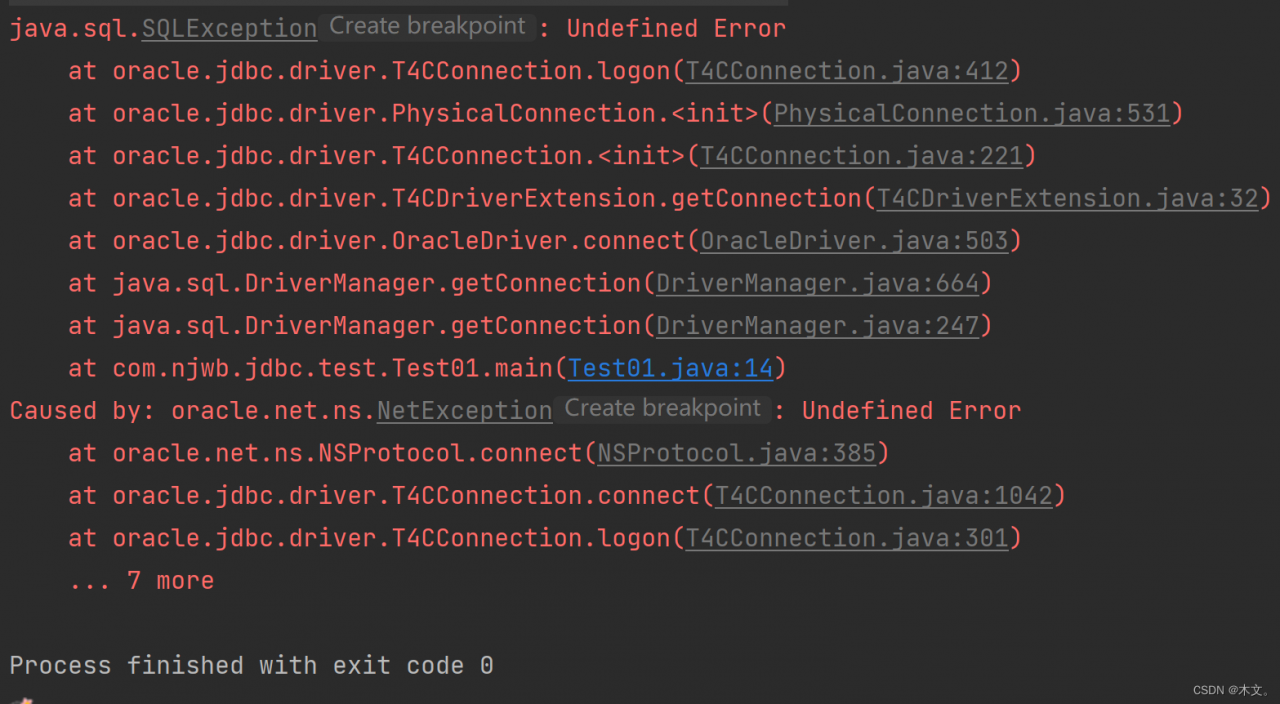
The error is reported as follows:
java.sql.SQLException: ERROR 726 (43M10): Inconsistent namespace mapping properties. Cannot initiate connection as SYSTEM:CATALOG is found but client does not have phoenix.schema.isNamespaceMappingEnabled enabled
at org.apache.phoenix.exception.SQLExceptionCode$Factory$1.newException(SQLExceptionCode.java:494)
at org.apache.phoenix.exception.SQLExceptionInfo.buildException(SQLExceptionInfo.java:150)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.ensureTableCreated(ConnectionQueryServicesImpl.java:1113)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.createTable(ConnectionQueryServicesImpl.java:1501)
at org.apache.phoenix.schema.MetaDataClient.createTableInternal(MetaDataClient.java:2721)
at org.apache.phoenix.schema.MetaDataClient.createTable(MetaDataClient.java:1114)
at org.apache.phoenix.compile.CreateTableCompiler$1.execute(CreateTableCompiler.java:192)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:408)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:391)
at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:390)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:378)
at org.apache.phoenix.jdbc.PhoenixStatement.executeUpdate(PhoenixStatement.java:1806)
at org.apache.phoenix.query.ConnectionQueryServicesImpl$12.call(ConnectionQueryServicesImpl.java:2569)
at org.apache.phoenix.query.ConnectionQueryServicesImpl$12.call(ConnectionQueryServicesImpl.java:2532)
at org.apache.phoenix.util.PhoenixContextExecutor.call(PhoenixContextExecutor.java:76)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.init(ConnectionQueryServicesImpl.java:2532)
at org.apache.phoenix.jdbc.PhoenixDriver.getConnectionQueryServices(PhoenixDriver.java:255)
at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver.createConnection(PhoenixEmbeddedDriver.java:150)
at org.apache.phoenix.jdbc.PhoenixDriver.connect(PhoenixDriver.java:221)
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1596)
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1662)
at com.alibaba.druid.pool.DruidDataSource.init(DruidDataSource.java:929)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1311)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1307)
at com.atguigu.app.func.MyBroadcastFunction.CheckAndCreate(MyBroadcastFunction.java:72)
at com.atguigu.app.func.MyBroadcastFunction.processBroadcastElement(MyBroadcastFunction.java:65)
at com.atguigu.app.func.MyBroadcastFunction.processBroadcastElement(MyBroadcastFunction.java:19)
at org.apache.flink.streaming.api.operators.co.CoBroadcastWithNonKeyedOperator.processElement2(CoBroadcastWithNonKeyedOperator.java:118)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessorFactory.processRecord2(StreamTwoInputProcessorFactory.java:221)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessorFactory.lambda$create$1(StreamTwoInputProcessorFactory.java:190)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessorFactory$StreamTaskNetworkOutput.emitRecord(StreamTwoInputProcessorFactory.java:291)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66)
at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessor.processInput(StreamTwoInputProcessor.java:98)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:419)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:661)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:623)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:776)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563)
at java.lang.Thread.run(Thread.java:748)Prerequisites: The following configuration is available in the hbase-site.xml file, which must not be deleted later, and the resource folder of the API, hbase, and phoenix are already configured
<! -- Note: In order to enable the mapping of hbase's namespace and phoenix's schema, you need to add this configuration file to your application, and also on linux services, you need to add the above two configurations to the hbase-site.xml configuration files of hbase and phoenix, and use xsync for synchronization ( This is explained in the documentation in section 1).-->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>Reason: The hbase-site.xml file in resource is not read, manually copy it to target\generated-sources folder.
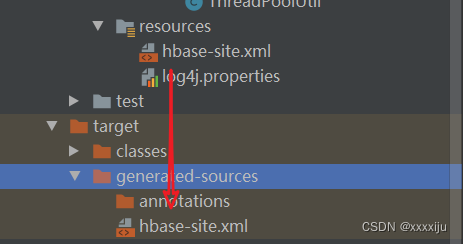
Problem-solving! 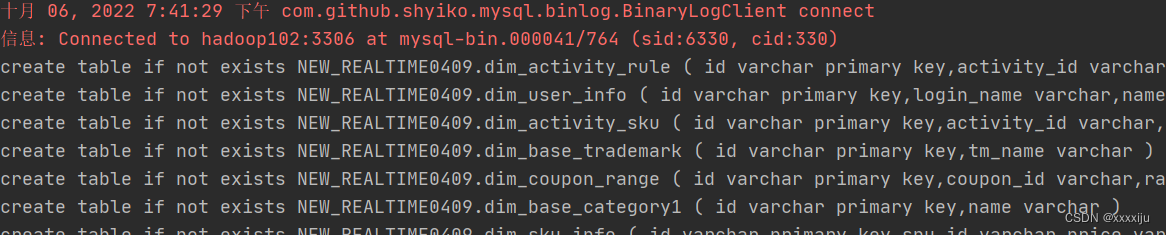
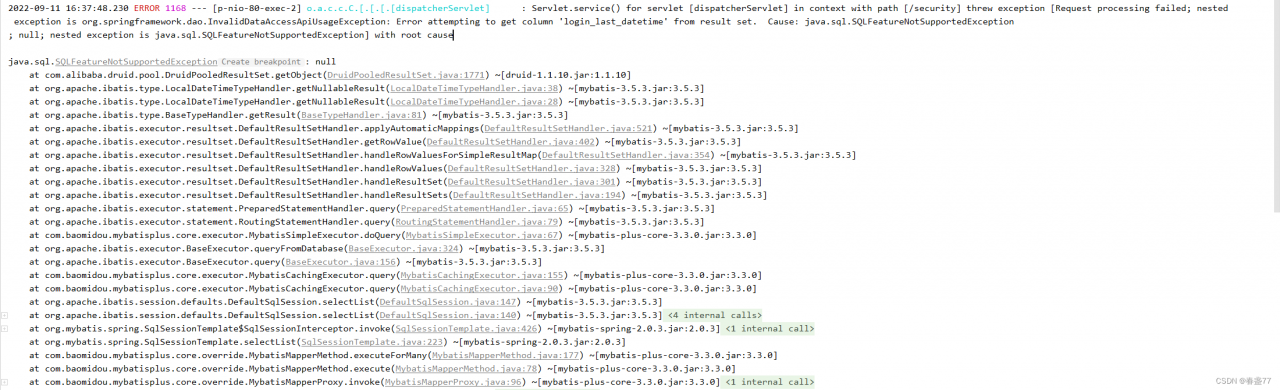 Error Cause
Error Cause