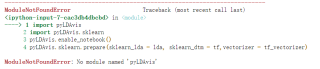
When using tensorflow.keras, this error is often reported during model training:
tensorflow/core/kernels/data/generator_dataset_op.cc:107] Error occurred when finalizing GeneratorDataset iterator: Failed precondition: Python interpreter state is not initialized. The process may be terminated.
[[{{node PyFunc}}]]
tensorflow/core/kernels/data/generator_dataset_op.cc:107] Error occurred when finalizing GeneratorDataset iterator: Failed precondition: Python interpreter state is not initialized. The process may be terminated.
[[{{node PyFunc}}]]
According to my own experience, there are several reasons for this errory:
1. The input image_size and input_shape does not match or is not defined when the model is built. Note that the input_shape must be defined when defining the first layer of the convolutional layer, e.g.
model = keras.models.Sequential([
# Input image [None,224,224,3]
# Convolution layer 1: 32 5*5*3 filters, step size set to 1, fill set to same
# Output [None,32,32,3]
keras.layers.Conv2D(32, kernel_size=5, strides=1, padding='same', data_format='channels_last',
activation='relu', input_shape=(224, 224, 3)),
2. There is also train_generator and validate_generator related parameters must be consistent, such as batch_size, target_size, class_mode, etc.
3. The configuration limit itself, try to change the batch_size to a smaller size, or even to 1
4. The last program did not finish completely, finish all python programs to see.

 you can find that the key values in the model are more modules
you can find that the key values in the model are more modules