petalinux-build Error: ERROR: Task (/opt/pkg/petalinux/components/yocto/source/aarch64/layers/meta-xilinx-tools/recipes-bsp/fsbl/fsbl_git.bb:do_compile) failed with exit code ‘1’
as below:
co@nvdla:~/petaproj/nvdla$ petalinux-build
[INFO] building project
[INFO] sourcing bitbake
[INFO] generating user layers
INFO: bitbake petalinux-user-image
Loading cache: 100% |############################################| Time: 0:00:00
Loaded 3811 entries from dependency cache.
Parsing recipes: 100% |##########################################| Time: 0:00:03
Parsing of 2777 .bb files complete (2775 cached, 2 parsed). 3812 targets, 150 skipped, 0 masked, 0 errors.
NOTE: Resolving any missing task queue dependencies
Initialising tasks: 100% |#######################################| Time: 0:00:02
Checking sstate mirror object availability: 100% |###############| Time: 0:00:11
Sstate summary: Wanted 174 Found 9 Missed 330 Current 757 (5% match, 82% complete)
NOTE: Executing SetScene Tasks
NOTE: Executing RunQueue Tasks
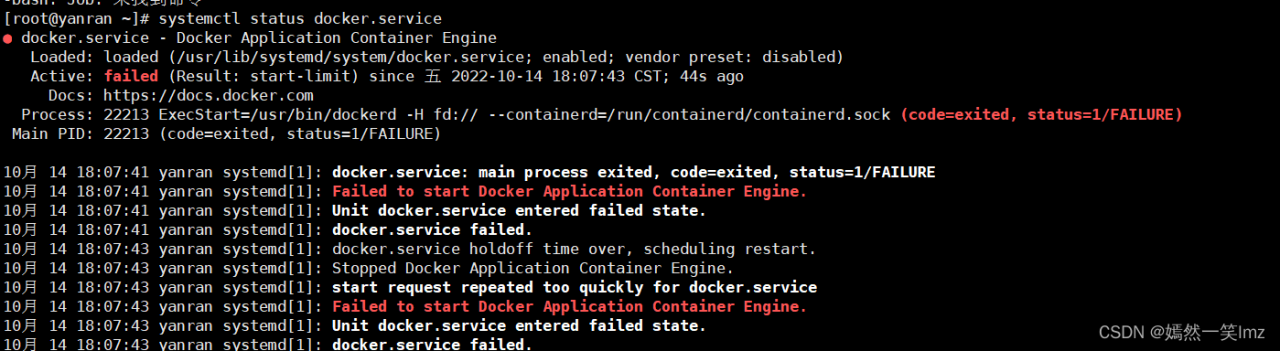
ERROR: fsbl-2019.1+gitAUTOINC+26c14d9861-r0 do_compile: Function failed: do_compile (log file is located at /home/co/petaproj/nvdla/build/tmp/work/plnx_zynqmp-xilinx-linux/fsbl/2019.1+gitAUTOINC+26c14d9861-r0/temp/log.do_compile.899)
ERROR: Logfile of failure stored in: /home/co/petaproj/nvdla/build/tmp/work/plnx_zynqmp-xilinx-linux/fsbl/2019.1+gitAUTOINC+26c14d9861-r0/temp/log.do_compile.899
Log data follows:
| DEBUG: Executing shell function do_compile
| aarch64-none-elf-gcc -MMD -MP -Wall -fmessage-length=0 -DARMA53_64 -Os -flto -ffat-lto-objects -Wall -fmessage-length=0 -DARMA53_64 -Os -flto -ffat-lto-objects -c xfsbl_board.c -o xfsbl_board.o -Izynqmp_fsbl_bsp/psu_cortexa53_0/include -I.
| In file included from xfsbl_board.c:54:
| xfsbl_board.h:64:10: fatal error: xiicps.h: No such file or directory
| #include "xiicps.h"
| ^~~~~~~~~~
| compilation terminated.
| make: *** [Makefile:34: xfsbl_board.o] Error 1
| WARNING: /home/co/petaproj/nvdla/build/tmp/work/plnx_zynqmp-xilinx-linux/fsbl/2019.1+gitAUTOINC+26c14d9861-r0/temp/run.do_compile.899:1 exit 2 from 'make'
| ERROR: Function failed: do_compile (log file is located at /home/co/petaproj/nvdla/build/tmp/work/plnx_zynqmp-xilinx-linux/fsbl/2019.1+gitAUTOINC+26c14d9861-r0/temp/log.do_compile.899)
ERROR: Task (/opt/pkg/petalinux/components/yocto/source/aarch64/layers/meta-xilinx-tools/recipes-bsp/fsbl/fsbl_git.bb:do_compile) failed with exit code '1'
NOTE: Tasks Summary: Attempted 2926 tasks of which 2910 didn't need to be rerun and 1 failed.
Summary: 1 task failed:
/opt/pkg/petalinux/components/yocto/source/aarch64/layers/meta-xilinx-tools/recipes-bsp/fsbl/fsbl_git.bb:do_compile
Summary: There was 1 ERROR message shown, returning a non-zero exit code.
ERROR: Failed to build project
Solution:
1) File Directory <petalinux_proj>/project-spec/meta-user/recipes-bsp/fsbl/fsbl_%.bbappend
Check whether there is fsbl_% Bbappend or not, create it if not:
vim <plnx-proj-root>/project-spec/meta-user/recipes-bsp/fsbl/fsbl_%.bbappend
2) Add the following
do_compile_prepend(){
install -m 0644 ${TOPDIR}/../project-spec/hw-description/psu_init.c ${B}/fsbl/psu_init.c
install -m 0644 ${TOPDIR}/../project-spec/hw-description/psu_init.h ${B}/fsbl/psu_init.h
}
3) Clean up and rebuild the fsbl file
$ petalinux-build -c fsbl -x cleanall
$ petalinux-build -c fsbl
Problem-solving!