Error:couldn‘t connect to server 127.0.0.1:27017, connection attempt failed: SocketException: …
Problem Examples
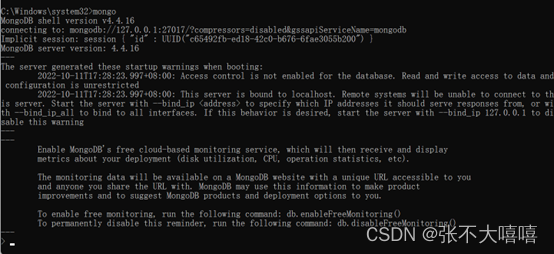
Do you encounter the following problems when entering mongo at the terminal?
couldn’t connect to server 127.0.0.1:27017, connection attempt failed: SocketException: Error connecting to 127.0.0.1:27017 :: caused by :: ���� Ŀ ����������� ܾ ���� ���� ӡ �

Problem analysis
In fact, this problem is not complicated, just because your mongodb is not started. Just start it.
Problem-solving
Enter the bin directory of mongodb (enter the bin directory of mongodb you installed)

Input command (port number can be specified)
mongod –logpath “E:\professional_software\mongodb\data\log\mongodb.log” –dbpath “E:\professional_software\mongodb\data\db” –logappend
or
mongod –logpath “E:\professional_software\mongodb\data\log\mongodb.log” –dbpath “E:\professional_software\mongodb\data\db” –logappend –port 8888

In this way, the startup is successful and the next step is ready. Open another command prompt and enter mongo.