I originally installed Anaconda3, with python3.7 and Jupyter-notebook, and installed tf2.0 environment.
Later I created a new virtual environment tf_1 based on tf2.0 environment and installed tf.14, so that
tf1.0 and tf2.0 versions can be switched flexibly on Jupyter-notebook.
If you log in to notebook directly with cmd, see the following:
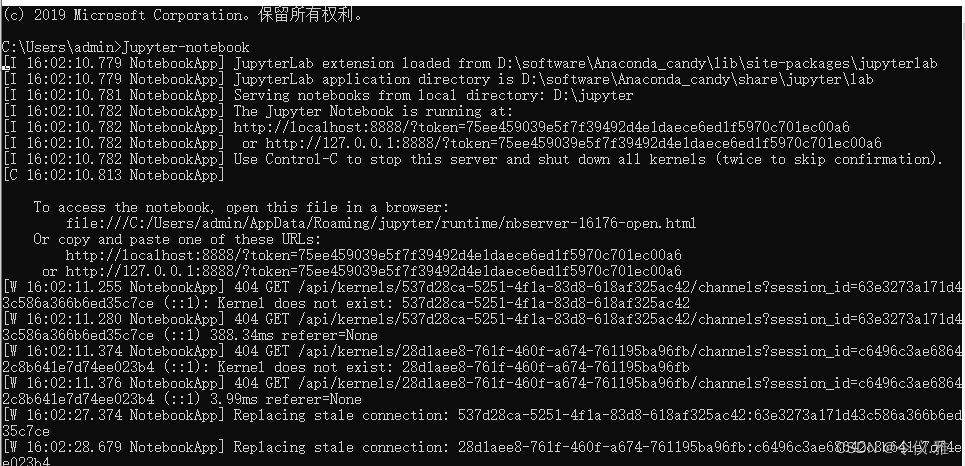
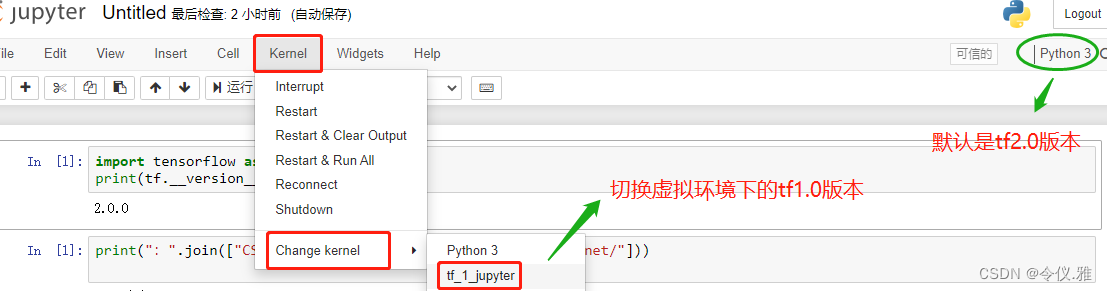
At this point, I directly create a new python3, which means that the default tf2.0 environment is Ok, as shown below:
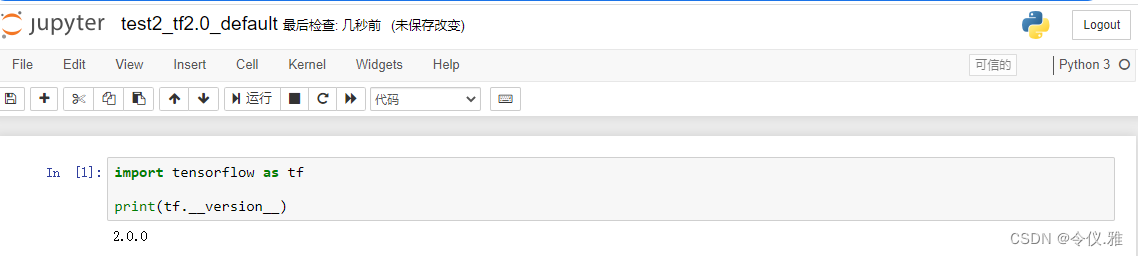
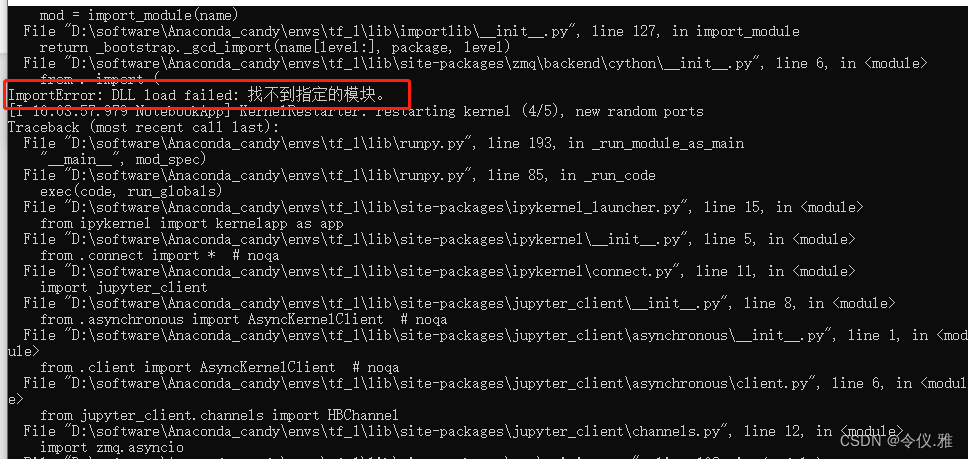
But I new a tf_1_jjupyter is reported the following error, also open a tf2.0 version of the notebook file in the change kenerl will also report the same error.
The error is reported as follows.
ImportError: DLL load failed: The specified module could not be found
II. Solution
Solve the Jupyter notebook startup error or running code error
1. ImportError: DLL load failed : The specified module could not be found
Solution.
cmd-windows console-enter conda activate virtual environment name
For example, the name of the virtual environment here is tf_1
If you don’t remember, you can find it in the Anaconda installation directory
D:\software\Anaconda_candy\envs\tf_1
2. solve python.exe can not find the entrance can not locate the program input point
After entering the virtual environment if it still reports an error as follows.
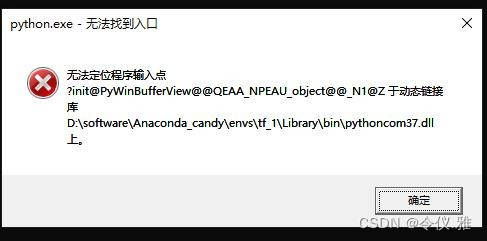
This error pops up when I enter jupyter notebook, but I can enter jupyter notebook to debug the code normally when I cross it out. Initially, I think there is a problem with the dll file. After reading some online solutions, the following is the solution:
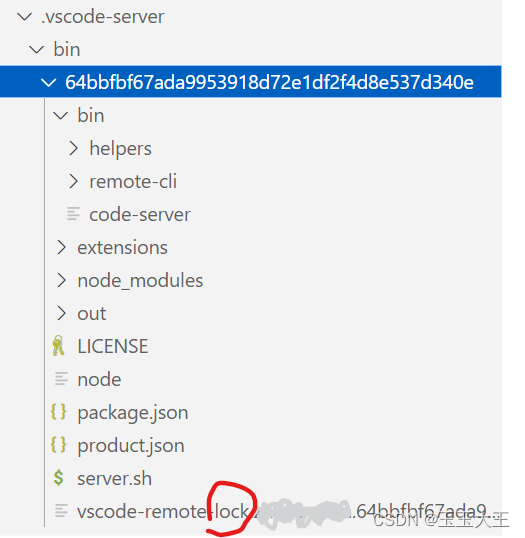
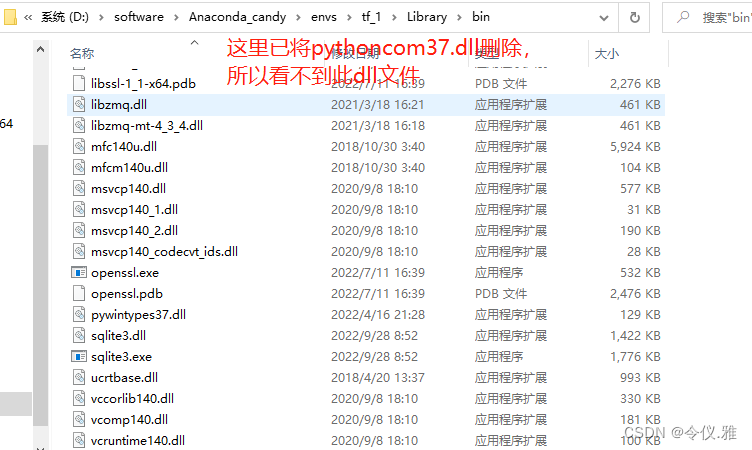
Solution: pythoncom37.dll is a file of pywin32 located in the path Anaconda3\envs\your virtual environment\Lib\site-packages\pywin32_system32, the location of my file here is shown below.

And there is a file with the same name ythoncom37.dll in D:\python\Anaconda3\envs\tf_1\Library\binp.
After deleting this file, there will be no pop-up error!
After deleting the pythoncom37.dl file according to the file path in the pop-up box, the error is still reported as follows.
[premise conda activate tf_1 under virtual environment
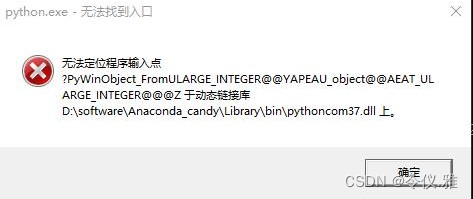
We follow the file path given in the pop-up box to find pythoncom37.dl and delete it again, and that’s the end of it.
The above solution has been successfully solved as follows.
Switching kernel in the file will also not report errors
Select tf2.0 and virtual environment tf1.0 in the drop-down box by creating a new, and you can switch versions freely, or switch environments in the current file, as shown below: