The specific error is shown in the figure below:
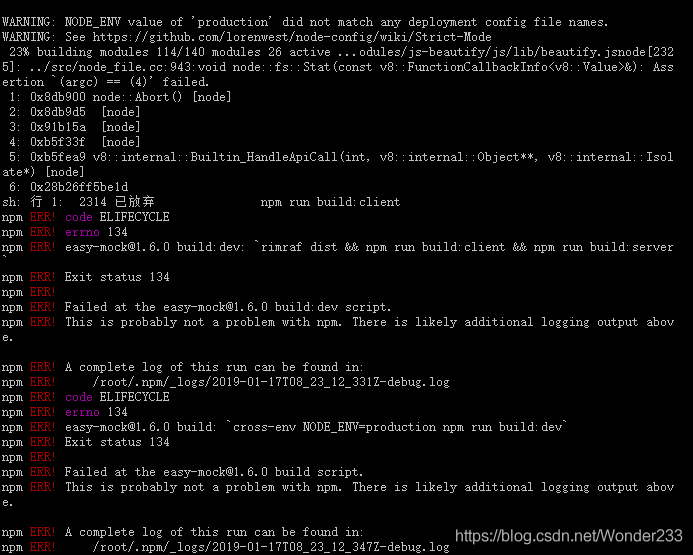
node_ Module installation problem, we need to re install
rm -rf node_modules
rm package-lock.json
npm cache clear --force
npm install
Finally, NPM run build is completed.
The specific error is shown in the figure below:
node_ Module installation problem, we need to re install
rm -rf node_modules
rm package-lock.json
npm cache clear --force
npm install
Finally, NPM run build is completed.
After the sentinel mode is configured in the local redis, use spring to integrate redis and report an error
Caused by: redis.clients.jedis . exceptions.JedisConnectionException : java.net.SocketException : Connection reset by peer: socketwrite error
Solution: in redis slave sentinel.conf Add to profile
![]()
Error report screenshot
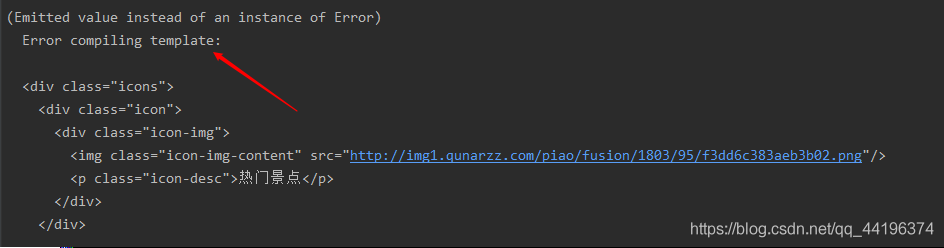
reason: the label is not written correctly, the label is missing or there are too many labels, such as the corresponding label is not closed.
Solution: find unclosed or redundant tags, and then complete or delete them.
The reason for my error report is that I wrote a missing closed label div to fill in it
The reason is that after using the virtual machine, the host only network created automatically by VirtualBox makes the detection of inode multi network cards fail, and inode can access the Internet normally after it is disabled in the network
After that, after the host only network is enabled, the virtual device will automatically create a new host only network when the genymotion is opened. After the virtual device is started, an error will be reported. When the virtual box is used to start, the error cannot be & lt; device name & gt; Create a new task, set IP to 196.168.56.1 according to the online instructions, the problem still can not be solved, and report an error VirtualBox error in super3hardenedwinrespawn, uninstall the current version of VBox, and reload the latest version
1. Error description
Today, when I compiled the app with Android studio and installed APK, I reported an error as follows:
The APK file build\outputs\apk\OYP_2.3.4_I2Base_6476_official_debug.apk does not exist on disk.
Error while Installing APK1 2
As shown in the figure below,

2. Solutions
1. Try build – & gt; clean project recompilation or invalid
2. Try to restart Android studio is invalid
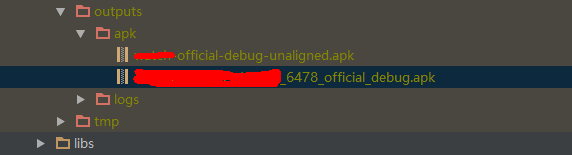
Then I went to the build/outputs/APK directory and found that the APK file was compiled, but the file name was:
oyp_ 2.3.4_ I2Base_ 6478_ official_ debug.apk
as shown in the figure below:
So the reason is that the compiled APK file of Android studio is
OYP_ 2.3.4_ I2Base_ 6478_ official_ debug.apk
And it’s going to install the APK file name
OYP_ 2.3.4_ I2Base_ 6476_ official_ debug.apk
as a result, an error will be reported. Google looked up the error and found it in http://stackoverflow.com There is a solution to this error on the website, and the link is as follows:
the http://stackoverflow.com/questions/34039834/the-apk-file-does-not-exist-on-disk
Solution:
as shown in the figure below:
Step 1: click the gradle button in the Android studio sidebar, as shown below
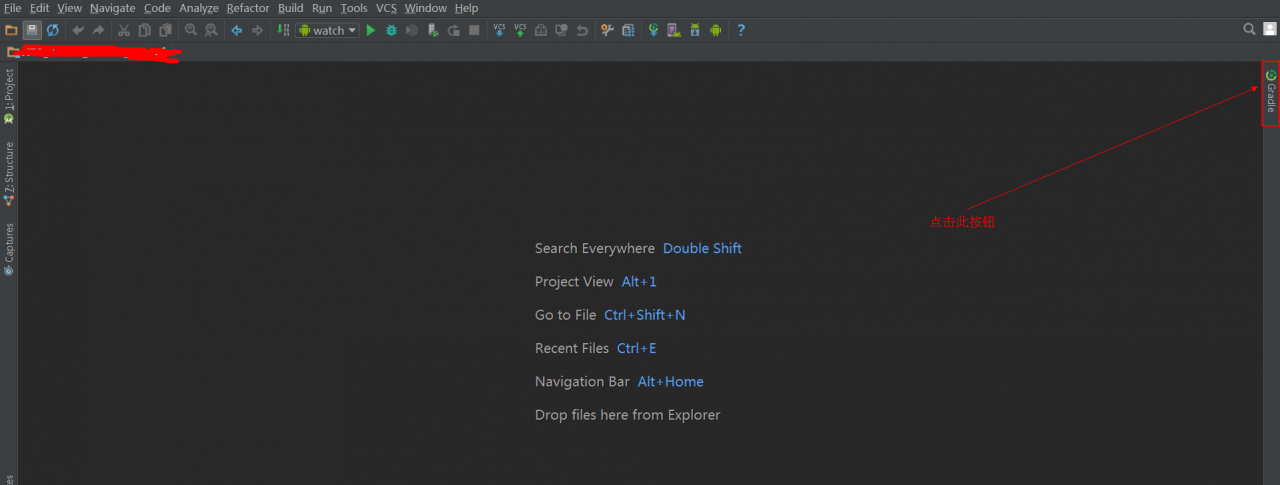
Step 2: refresh the gradle configuration
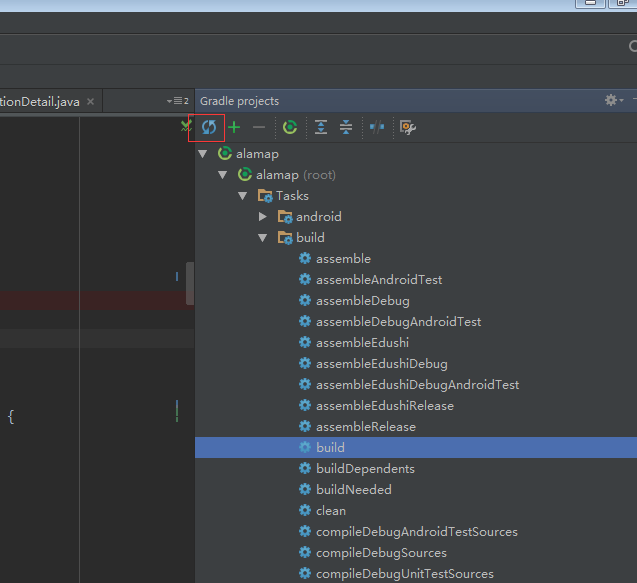
The third step: recompile, no more error.
Error:
1. The error prompt for SSL certificate rejection is different between Firefox and chrome
(1) Chrome error: websocket connection failed: error in connection establishment: Net:: err_ CERT_ AUTHORITY_ INVALID
(2) an error is reported in Firefox: it is unable to create a wss://www.wss.com/ Connection to the server.
2. Although the error prompts for SSL certificate rejection are different between Firefox and chrome, the solution steps are exactly the same.
code:
1 var ws = new WebSocket("wss://www.wss.com");
Cause of the problem:
Because the certificate is self signed, the CA of the certificate must not exist in the root storage area of the operating system. Naturally, the operating system will not recognize you, and the natural browser will not recognize you, that is, the self signed certificate is not trusted.
Solution:
1. Open a new tab page in Firefox or chrome.
2. Visit your websocket server domain name: https://www.wss.com (change the WSS request to an HTTPS request with the same domain name and port number).
3. You will find the browser alarm: “your connection is not private connection…”.
Don’t panic, look down and click “advanced”.
5. Continue to click “continue to” www.wss.com (unsafe) “.
6. The page will prompt “400 bad request…”, don’t worry. This is due to using HTTP protocol to access WSS service. Don’t worry. You can solve the prompt error here.
Reprinted from: http://www.blogdaren.com/post-2456.html?from=singlemessage
Reproduced in: https://www.cnblogs.com/XuYuFan/p/10917909.html
Premise:
There are no errors in the data source URL configured by grafana.
Phenomenon:
1) After upgrading grafana, it is found that the original configured open face data source is invalid, and HTTP error not found is always prompted.
2) After installing the new version of grafana, we found that ZABBIX data source configuration always reported an error, could not connect to given URL.
handle:
1) Re install the version under grafana 5.4.
2) Check the configuration of ZABBIX user name and password.
The specific reasons and how to configure them above grafana 5.4 have not been studied yet.
Reproduced in: https://www.cnblogs.com/whych/p/10793709.html
QT creator version 5.6.0 add Icon error: – 1: error: [debug/myapp]_ Res.o] error 1, temporary solution:
Project – build environment – clear system environment variables. Previously, it was selected, but now it is not selected. Then it can be compiled. The guess is related to file permissions. Please give us some advice?
During learning, when writing Python code, the following error was reported: “keyerror” [‘year ‘] not in index “.
Problem description
When learning data visualization, the pandas package is called, and the code runs with an error. The error prompt is as follows
KeyError: "['year'] not in index"
Key error: ‘[‘year’] is not in index ‘
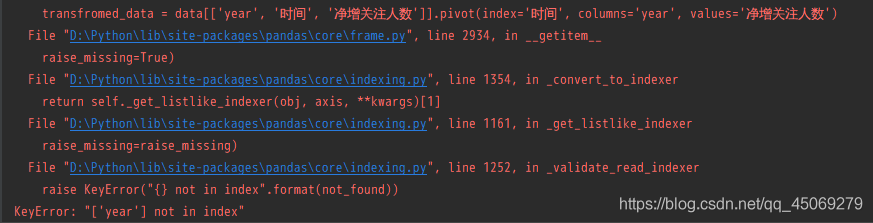
problem analysis
Check the code and find that the front and the back are inconsistent, and there are some problems when you write your own code
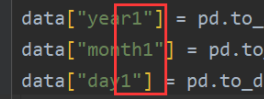

Solution
delete “1” and solve the problem
OK, keep learning.
Operating environment
System: Windows 10
jdk:1.7
Development tool: Eclipse 4.6
Springboot version: 1.5.3
version
Build tool: Maven
0
Problems and their background
At the beginning of learning to build a spring boot project, the problems encountered.
After creating a new Maven project, add the pom.xml The file reported an error when adding the parent node (the content is as follows).
<parent>
<groupId> org.springframework.boot< ;/groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.2.RELEASE</version>
</parent>
The error information is as follows:
Error parsing lifecycle processing instructions
terms of settlement
According to the search results, two ideas are found
1. It is said that there is a problem with this version of eclipse, and the Maven plug-in needs to be updated.
2. It is said that there is a dependency conflict. You can clear the Maven warehouse and update it again.
The first method was tried, but it didn’t solve the problem. So we tried the second method to clear all the dependencies under. M2/repository/in the user’s home directory. Then, in eclipse, right-click the project — & gt; Maven — & gt; update project. After waiting for the update to complete, the error disappears automatically.
Error picture information:
The reason for the error is that the resource package has a Chinese path

Hive SQL syntax is different from the frequently used MySQL syntax. SQL written according to the habit of writing MySQL often reports errors, and it is difficult to see the cause of the problem. Therefore, this paper records the phenomenon of the problem and the solution
If you don’t find any problem with the alias: select from error ‘> select from error = 4200* From a) treror: error while compiling statement: failed: semanticexception [error 10025]: expression not in group by key ID (state = 42000, code = 10025)
cause: fields in the select statement but not in the group by statement will cause the error
solution: change the select id, name from a group by name to select collect_ Set (ID), name from a group by NameError: error while compiling statement: failed: semanticexception [error 10004]: Line 1:13 invalid table alias or column reference ‘ID’:
cause: the corresponding field in the subquery statement has changed, such as using a function or renaming
solution: select id, name from (select collect)_ Set (ID), name from a group by name) t “is changed to” select id, name from (select collect)_ Set (ID) id, name from a group by name) t or select t.id, name from (select collect)_ Set (ID), name from a group by name) tproblem: unable to query data after hive multiple SQL unions
cause: the data after union is saved in HDFS to multiple new directories under the table directory
solution: add configuration (which can be directly input on the CLI command line) set mapred.input.dir .recursive=true;
Or use a select statement to package multiple union statements and then execute hsql on tez to report an error. Out of memory
needs to adjust the size of the container
set hive.tez.container .size=4096;
set hive.tez.java . opts = – xmx3072m; hive does not query subdirectories recursively by default, so when creating a table, if there are subdirectories in the specified directory, it will report ERROR:not a file
You can perform the following four configurations in hive cli to enable recursive access to subdirectories in the callback. Instead of recursive query, all the data under the directory will be loaded in. Therefore, when the subdirectories are very deep or there are many subdirectories, the speed will be very slow.
set hive.input.dir .recursive=true;
set hive.mapred.supports .subdirectories=true;
set hive.supports.subdirectories=true ;
set mapred.input.dir .recursive=true;