hive on spark reports an error
executing the hive command is an error
[42000][3] Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
[Reason]
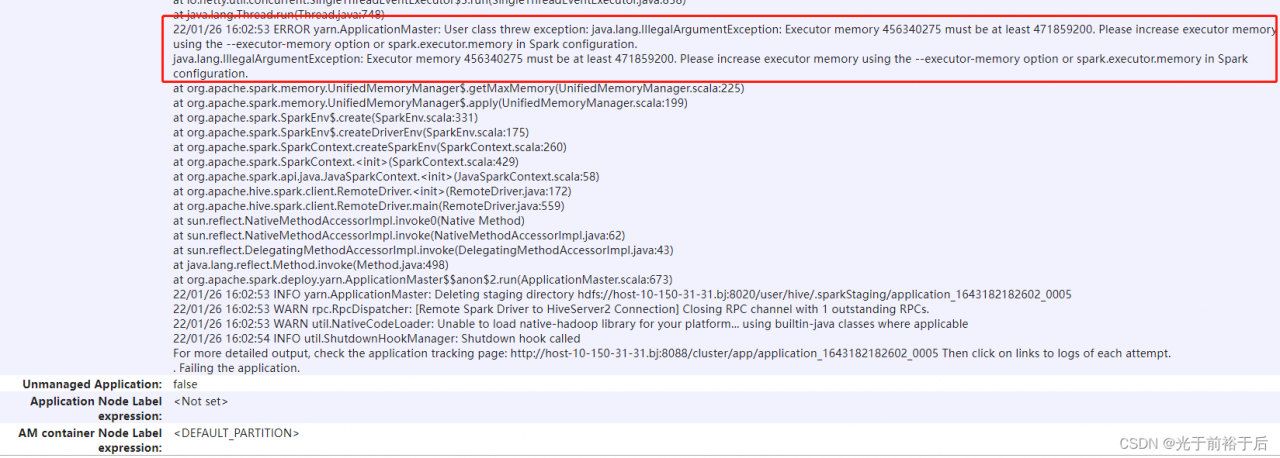
View running tasks on yarn, Query error results from error log
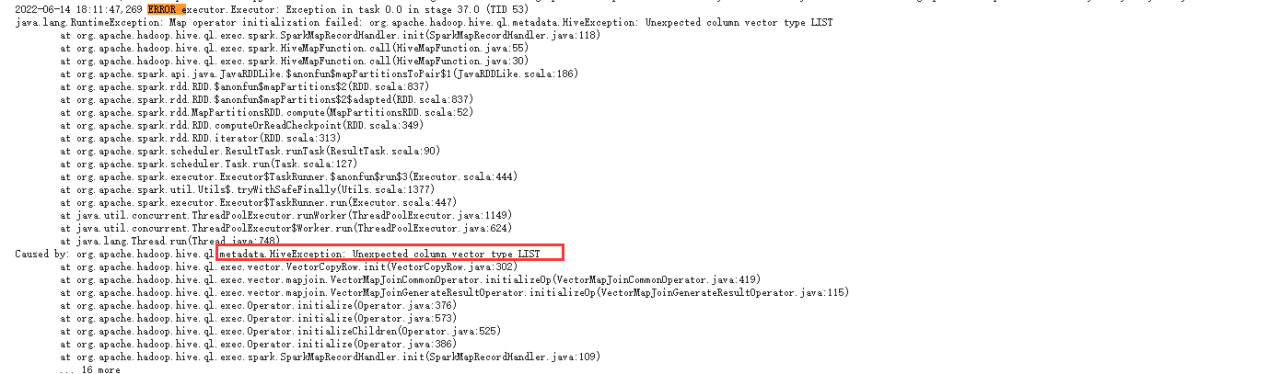
Map operator initialization failed: org.apache.hadoop.hive.ql.metadata.HiveException: Unexpected column vector type LIST
List type error
List corresponds to array in hive, array corresponds to list in Java
[Solution]
Temporarily change the execution engine to MR
set hive.execution.engine=mr;
There are many bugs in hive on spark, When an unknown error occurs, First try to replace the underlying execution engine with MR, to execute the sql statement.
[Subsequent modification]
1. View the current execution engine of hive:
set hive.execution.engine;
2. Manually set hive’s current execution engine to Spark
set hive.execution.engine=spark;
3. Manually set hive’s current execution engine to MR
set hive.execution.engine=mr;