- check whether there is a file with the same name
onnxruntime in the current path. If so, modify the file name, uninstall both the CPU version of onnxruntime and the GPU version of onnxruntime GPU, and reinstall the required
onnxruntime in the current path. If so, modify the file name, uninstall both the CPU version of onnxruntime and the GPU version of onnxruntime GPU, and reinstall the required
This error message appears when quartus is integrating
find the corresponding code:
![]()
from the sensitive list, the register in the always block is asynchronously reset, so during synthesis, the reset end of the register must only be connected with the reset signal, but the code is connected with the synchronization signal other than the reset signal
modification method:
1. Change to synchronization
always@(posedge clk) begin
if(!rst_n || first_tu_flag) begin
...
end
2. Standard writing
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
...
end
else if(first_tu_flag) begin
...
end
As we all know, most of our products are compiled in go language. In the case of concurrency, read-only is thread safe, and read-write is thread unsafe.
Recently, in the easynvr site of a project, we checked the log and found the error message: fatal error: concurrent map read and map write. The error message shows that there are concurrent map reads and writes, that is, two concurrent functions are used to read and write the map continuously, resulting in race problems.
Find the code and find that concurrent read/write is used in the code:
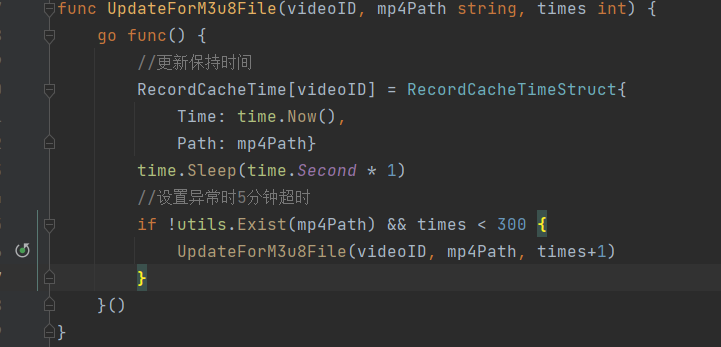
The code needs to be modified here. Below, we replace the built-in map type with the concurrency safe sync.map.
Write reference codes concurrently as follows:
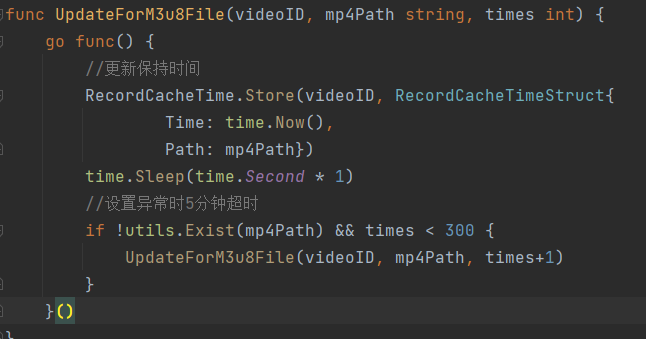
The concurrent read reference code is as follows:
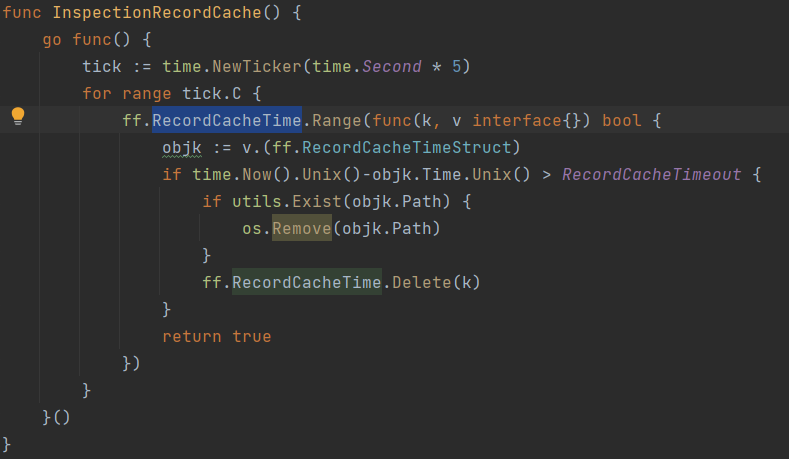
Add: for concurrency problems that are not easy to find, you can use the – race parameter for concurrency detection:
func main() {
a := 1
go func() {
a = 2
}()
a = 3
fmt.Println(a)
time.Sleep(time.Second * 1)
}Use docker to install nexecloud, link MariaDB, and an error is reported
Error message
General error: 4047 InnoDB refuses to write tables with ROW_ FORMAT=COMPRESSED or KEY_ BLOCK_ SIZE.
resolvent
Run maraidb in docker and add
-- skip InnoDB read only compressed
to execute normally
Online learning code, error reporting
SyntaxError: unexpected EOF while parsing
If you encounter this problem, first check whether the parentheses are written less
View source code
res = sorted(res.iteritems(), key=lambda x : x[1])
The code is the version of python2. X. res.iteritems () has been dropped under python3. X, so it is modified to
res = sorted(res.items(), key=lambda x : x[1])
Solve the problem of error loading MySQL DB module encountered during Django project
Python version 3.9 was used when creating the Django project. The MySQL database was successfully introduced in the process of doing the project, but later the python version was reduced to 3.7, so this error was reported when re running the system
Problem causes and solutions:
the package used by Django to connect to MySQL in Python 3 is pymysql, so the first step is to install pymysql:
pip install pymysql
Installation does not mean that it is OK. It also needs to be installed in the project__ init__. Add the following code to the. Py file:
import pymysql
pymysql.install_as_MySQLdb()
reason:
Because VNC is used to remotely control the lower computer, rviz is a graphics plug-in developed based on OpenGL. Theoretical screen parameters (the tis’ screen) need to be used. Using VNC will lead to incorrect screen parameter values, resulting in rviz errors.
resolvent:
1) Connect the display in the lower computer, and then turn on rviz on the PC enabled with VNC to temporarily solve the problem.
2) Use SSH instead of VNC to control the lower computer remotely. Pay attention to closing the VNC process running in the background, otherwise the core dump problem will occur when running rviz. In addition, due to the impact of network speed, there may be a stuck problem.
Java: compilation failed: internal java compiler error when idea compiles the project
java: compilation failed: internal java compiler error
There are basically two root causes, one is the JDK version problem and the other is the stack shortage problem. This time, I am caused by the stack shortage;
1. JDK version problem
Check whether the JDK version is normal. Check both the idea configuration and the project configuration. If it does not meet the requirements, change to the JDK version of your own machine. My JDK is 1.8, so it is all changed to 1.8;
① JDK configuration in idea
File -> Setting -> Build,Execution,Deployment -> Compiler -> Java Compiler
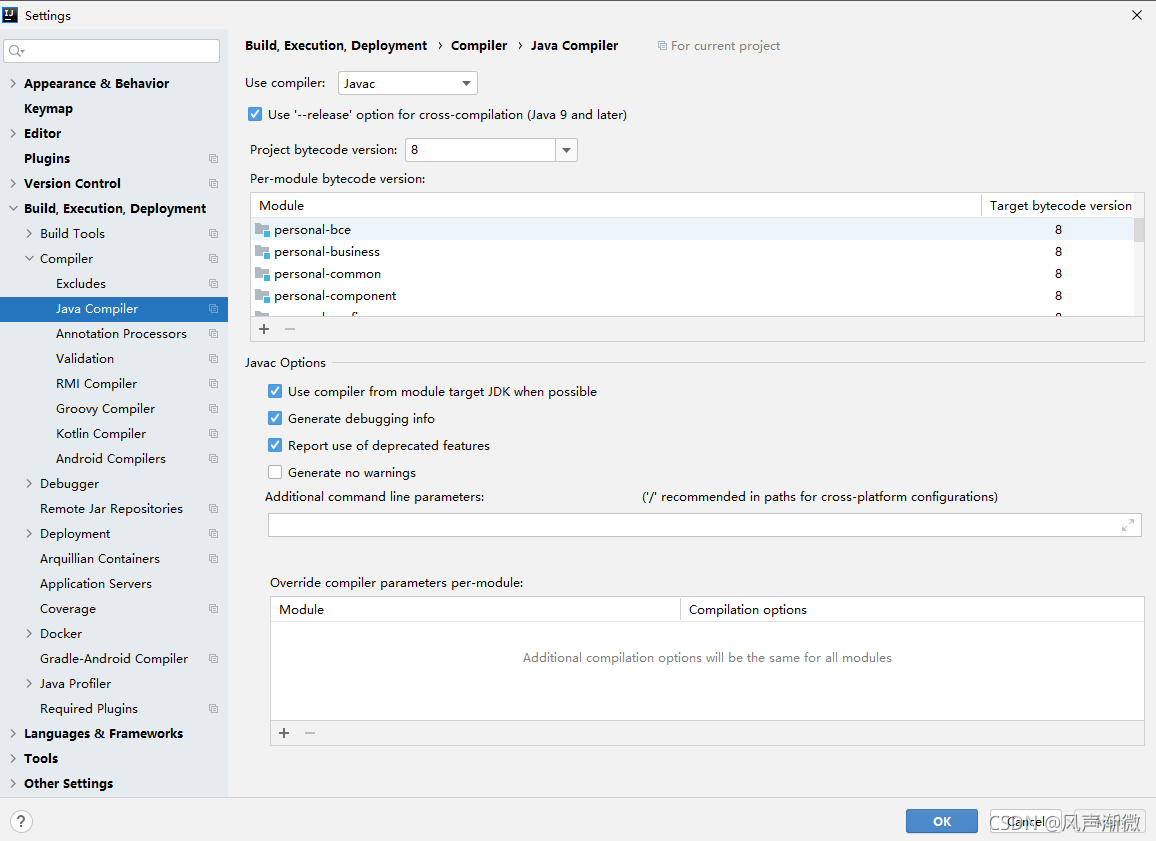
② JDK configuration for project
File -> Project Structure-> Project Settings -> Project
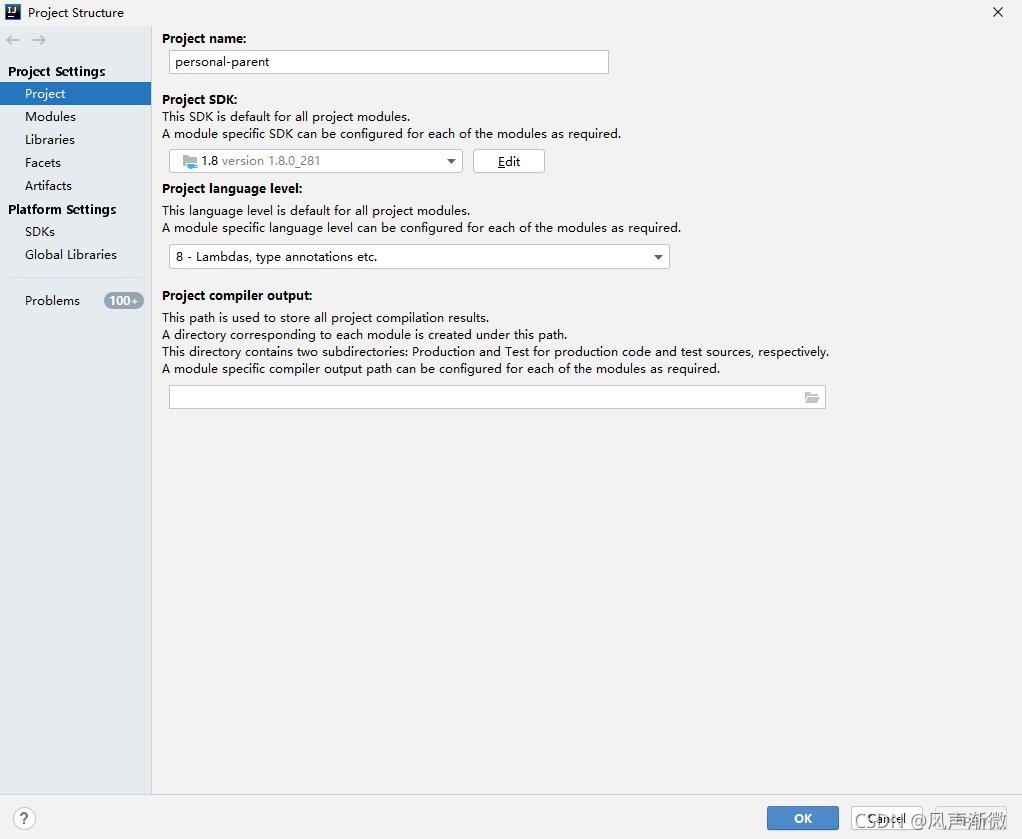
③ JDK configuration of project
File -> Project Structure-> Project Settings -> Modules -> Project name
note that if there are multiple projects, each one should be changed
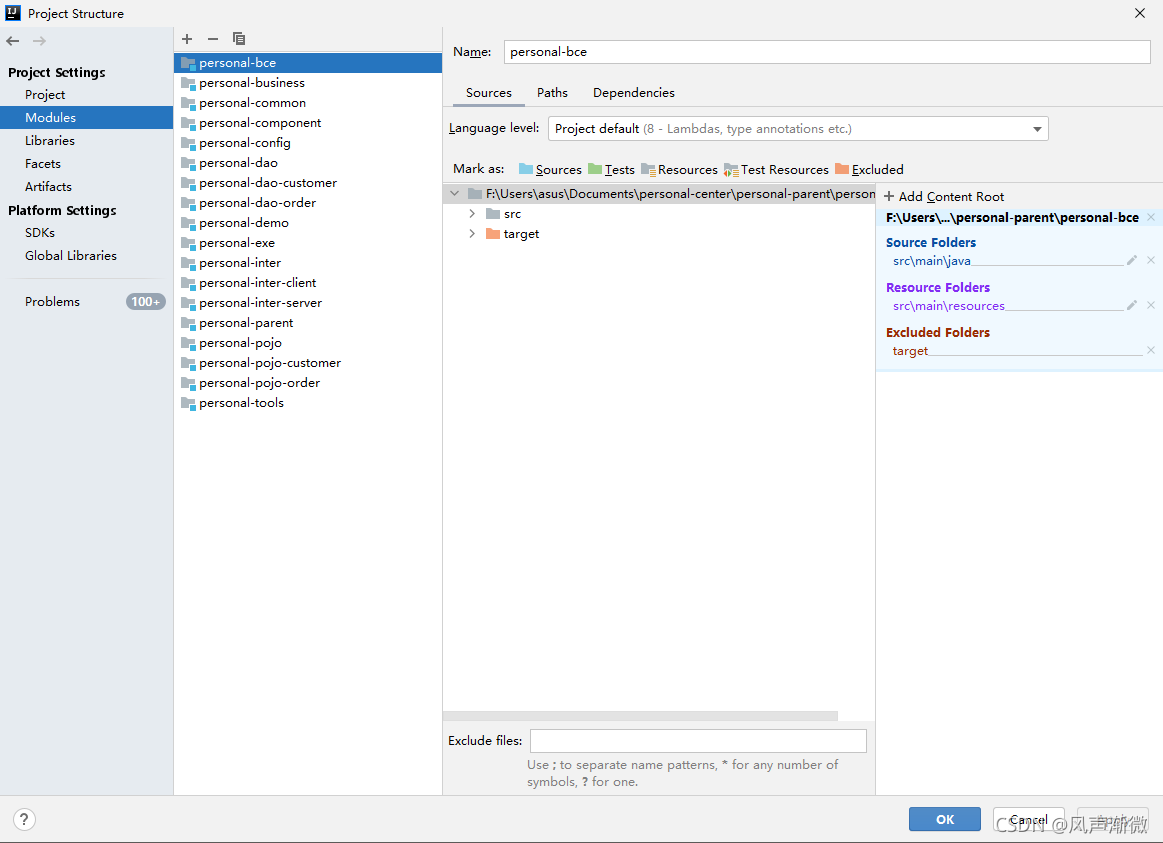
2. The project is too large, the build process heap is small, and the stack is insufficient during construction
This requires changing the size of the generated process heap
setting–> Build,Execution,Deployment–> Compiler –> User local build process heap size (Mbytes)
here is user local build process heap size (Mbytes). Different versions may not be consistent, but they should be very different. The original default is 700, but it is generally changed to 1024, which is enough. You can’t add it again
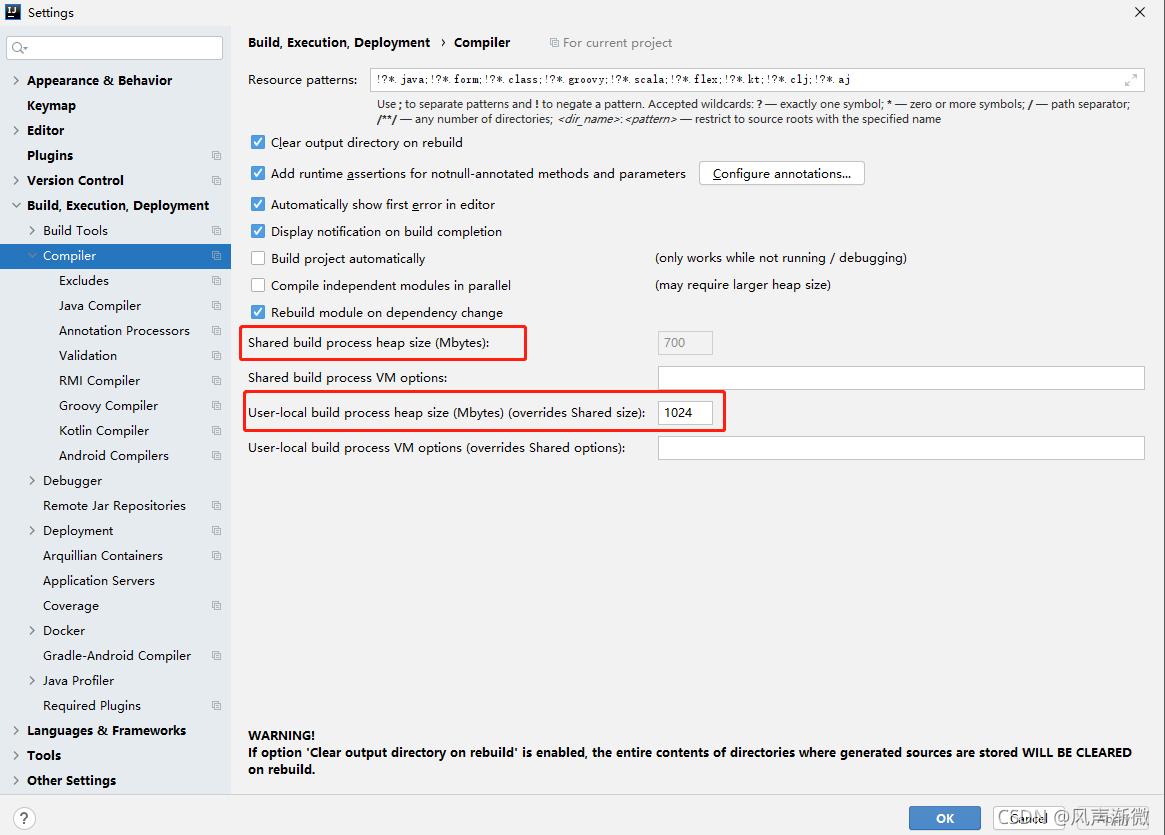
Note:
after the JDK version is changed, it is recommended to clear the cache and restart
file – > Invalidate Caches/Restart
Nacos is started on 192.168.11.13, and the access is normal
the local server is started on 192.168.11.11, and the startup log reports an error
server check fail, please check server 192.168.11.13, port 9848 is available, error = {}
2021-10-09 17:33:16.178 ERROR 21512 --- [ main] c.a.n.c.remote.client.grpc.GrpcClient : Server check fail, please check server 192.168.11.13 ,port 9848 is available , error ={}
java.util.concurrent.TimeoutException: Waited 3000 milliseconds (plus 731800 nanoseconds delay) for com.alibaba.nacos.shaded.io.grpc.stub.ClientCalls$GrpcFuture@157ec23b[status=PENDING, info=[GrpcFuture{clientCall={delegate={delegate=ClientCallImpl{method=MethodDescriptor{fullMethodName=Request/request, type=UNARY, idempotent=false, safe=false, sampledToLocalTracing=true, requestMarshaller=com.alibaba.nacos.shaded.io.grpc.protobuf.lite.ProtoLiteUtils$MessageMarshaller@60d6fdd4, responseMarshaller=com.alibaba.nacos.shaded.io.grpc.protobuf.lite.ProtoLiteUtils$MessageMarshaller@66f28a1f, schemaDescriptor=com.alibaba.nacos.api.grpc.auto.RequestGrpc$RequestMethodDescriptorSupplier@60a19573}}}}}]]
at com.alibaba.nacos.shaded.com.google.common.util.concurrent.AbstractFuture.get(AbstractFuture.java:508)
at com.alibaba.nacos.common.remote.client.grpc.GrpcClient.serverCheck(GrpcClient.java:146)
at com.alibaba.nacos.common.remote.client.grpc.GrpcClient.connectToServer(GrpcClient.java:268)
at com.alibaba.nacos.common.remote.client.RpcClient.start(RpcClient.java:395)
at com.alibaba.nacos.client.config.impl.ClientWorker$ConfigRpcTransportClient.ensureRpcClient(ClientWorker.java:924)
at com.alibaba.nacos.client.config.impl.ClientWorker$ConfigRpcTransportClient.getOneRunningClient(ClientWorker.java:1087)
at com.alibaba.nacos.client.config.impl.ClientWorker$ConfigRpcTransportClient.queryConfig(ClientWorker.java:979)
at com.alibaba.nacos.client.config.impl.ClientWorker.getServerConfig(ClientWorker.java:407)
at com.alibaba.nacos.client.config.NacosConfigService.getConfigInner(NacosConfigService.java:166)
at com.alibaba.nacos.client.config.NacosConfigService.getConfig(NacosConfigService.java:94)
at com.alibaba.cloud.nacos.client.NacosPropertySourceBuilder.loadNacosData(NacosPropertySourceBuilder.java:85)
at com.alibaba.cloud.nacos.client.NacosPropertySourceBuilder.build(NacosPropertySourceBuilder.java:73)
at com.alibaba.cloud.nacos.client.NacosPropertySourceLocator.loadNacosPropertySource(NacosPropertySourceLocator.java:199)
at com.alibaba.cloud.nacos.client.NacosPropertySourceLocator.loadNacosDataIfPresent(NacosPropertySourceLocator.java:186)
at com.alibaba.cloud.nacos.client.NacosPropertySourceLocator.loadNacosConfiguration(NacosPropertySourceLocator.java:158)
at com.alibaba.cloud.nacos.client.NacosPropertySourceLocator.loadSharedConfiguration(NacosPropertySourceLocator.java:116)
at com.alibaba.cloud.nacos.client.NacosPropertySourceLocator.locate(NacosPropertySourceLocator.java:101)
at org.springframework.cloud.bootstrap.config.PropertySourceLocator.locateCollection(PropertySourceLocator.java:52)
at org.springframework.cloud.bootstrap.config.PropertySourceLocator.locateCollection(PropertySourceLocator.java:47)
at org.springframework.cloud.bootstrap.config.PropertySourceBootstrapConfiguration.initialize(PropertySourceBootstrapConfiguration.java:98)
at org.springframework.boot.SpringApplication.applyInitializers(SpringApplication.java:623)
at org.springframework.boot.SpringApplication.prepareContext(SpringApplication.java:367)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:311)
at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:140)
at org.springblade.core.launch.BladeApplication.run(BladeApplication.java:50)
at com.ht.bms.custom.CustomApplication.main(CustomApplication.java:31)
Although an error is reported, the service can be started normally. The problem is that when the local server calls other services registered in Nacos, it cannot be called after timeout
But other colleagues started the service on their computer and reported no error.
The problem has been solved:
check whether the Nacos server 8848884998489849 is open to these ports. If the docker is started, the ports need to be exposed.
when the ports are exposed and open, there are still problems. I modified the configuration of the idea. The problem is solved:
configuration before modification:
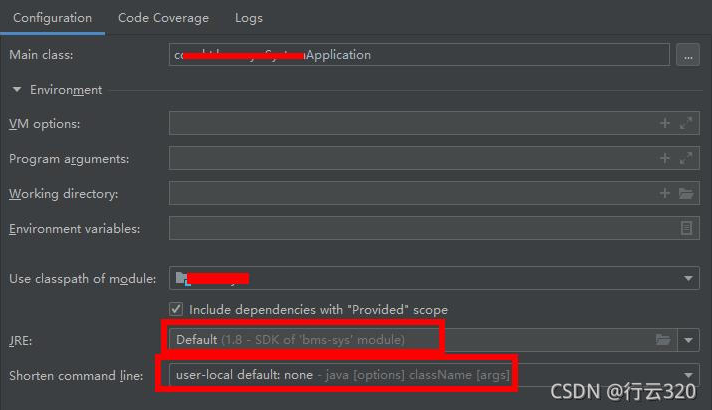
After modification:
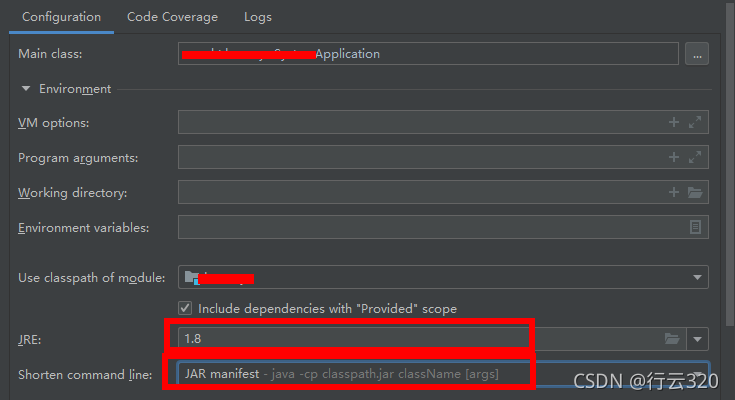
the JRE is changed to the JRE installed locally instead of the JRE provided by idea
in addition, the short command line is also modified
The error is not reported when restarting. It is normal, but the configuration is changed back, and the error is still not reported when restarting. It is strange
it may be due to the cache
have a nice work!
Material: ch32f103c8 minimum system board, keil5.27
Phenomenon: burning prompt internal command error
Solution: connect boot0 and boot1 to the jumper cap as shown in the figure below

Then click keil’s debug – & gt; Setting, select SWD in the connection port to see if the serial number similar to that in the figure below appears in the SWD service serial port (you can burn when it appears)
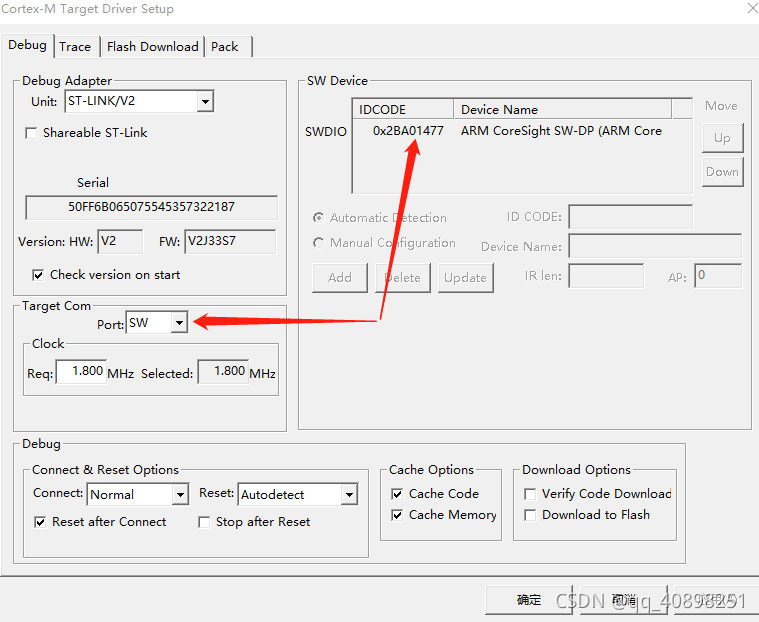
Solution:
Add:
tf.compat.v1.disable_eager_execution()
Today, during the image test in envi, I wanted to back up (save) the image, but the following error was reported
saverasterfile failed: idlnametadata error: nagetmetadata getmetadatajob failed
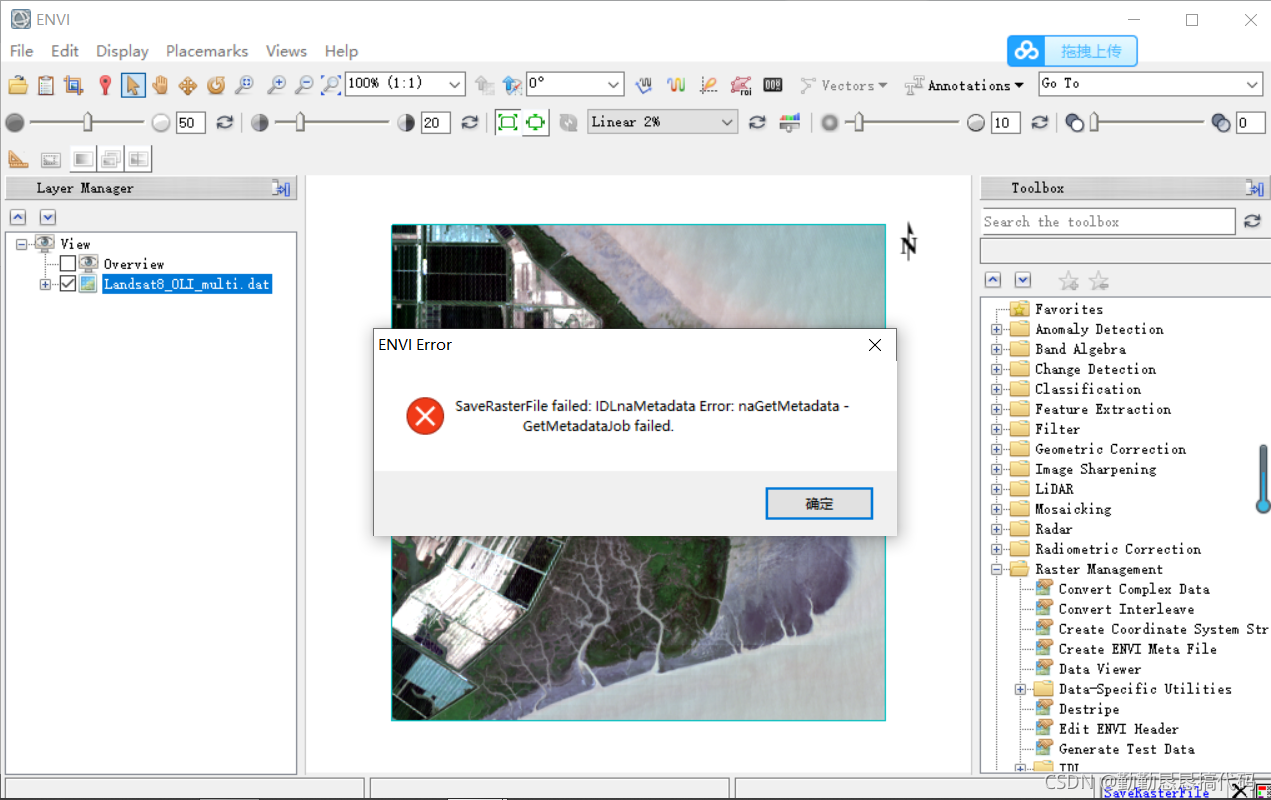
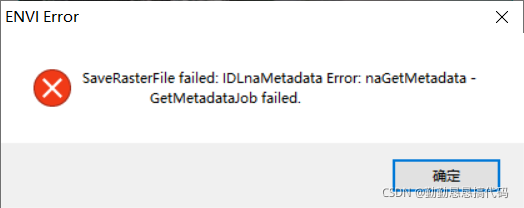
the reason is that Chinese cannot appear in the storage path, otherwise an error will be reported
When exporting to raster data, envi needs to read the metadata in the input file. If there is Chinese in the path, it will be unable to read and this error will be reported. At this time, you can change the storage path
the path where I read the image happens to have Chinese files, so I want to change it to English