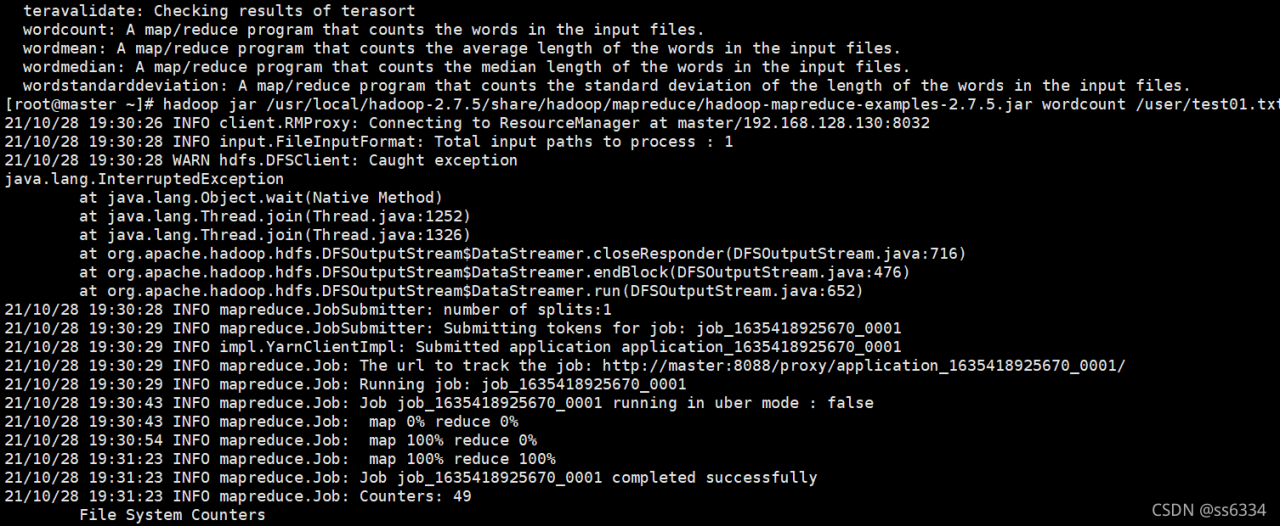
SQL Error [1] [08S01]: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798) at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
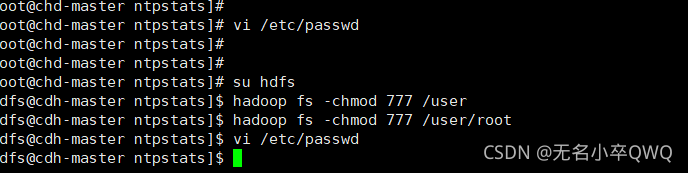
Solution: if su hdfs enter hdfs user vi /etc/password will
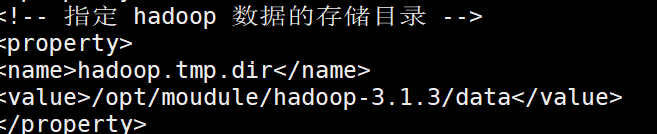
The back of hdfs is changed to the following

Then execute hadoop fs -chmod 777 /user
 at first, I thought it was my JDK version. The JDK version of Linux was 1.8 and my windows JDK version was 11.0. I changed the JDK environment variable to 1.8, but the problem remained the same after running.
at first, I thought it was my JDK version. The JDK version of Linux was 1.8 and my windows JDK version was 11.0. I changed the JDK environment variable to 1.8, but the problem remained the same after running.