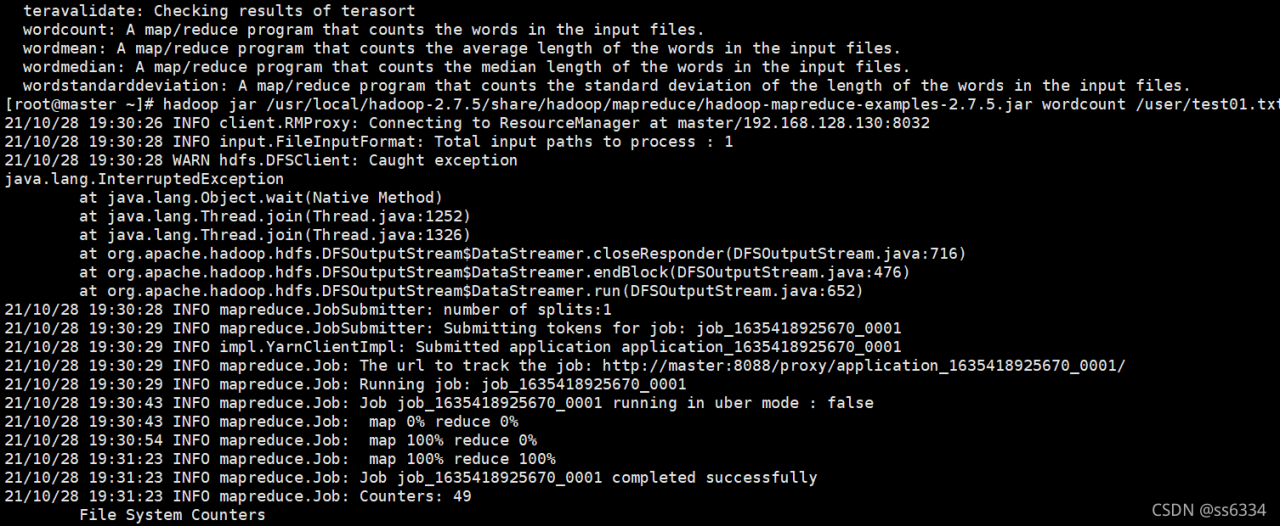
To view the files on haddop, enter:
hadoop fs -ls /
The following occurred:
ls: Call From yx/127.0.1.1 to 0.0.0.0:9000 failed on connection exception:
java.net.ConnectException: Denied to Access
For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Display 9000 port access denied
from the configuration file, you can know that Hadoop needs to access the machine through 9000 port, but now 9000 port access is denied
Input:
telnet localhost 9000
Display:
Trying 127.0.0.1…
telnet: Unable to connect to remote host: Connection refused
Input:
nmap -p 9000 localhost
Display:
Starting Nmap 7.80 ( https://nmap.org ) at 2020-04-25 14:57 CST
Nmap scan report for localhost (127.0.0.1)
Host is up (0.000051s latency).
PORT STATE SERVICE
9000/tcp closed cslistener
Nmap done: 1 IP address (1 host up) scanned in 0.03 seconds
Use the command:
lsof -i :9000
See which app is using the port. If the result is empty (return value 1), it is not opened
the above is just to check the status and will not change anything.
Because hadoop connects to the local port in core-site.xml
Open $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
</configuration>
It is found that I have not configured the port number, which is modified to:
hdfs://localhost:9000
It still not work.
I tried many methods, and finally found that the most commonly used method on the Internet is to use this method, which is really OK:
cd $HADOOP_HOME/bin
hdfs namenode -format
But I still couldn’t run it. I tried many times and all the results were the same. Later, then I found an error:
WARN common.Util: Path /data/tmp/hadoop/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
This is due to the non-standard path. The file describing the path is in:
$HADOOP_HOMW/etc/hadoop/hdfs-site.xml
Place in the file:
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/tmp/hadoop/hdfs/data</value>
</property>
Amend to read:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/tmp/hadoop/hdfs/data</value>
</property>
The warning disappears
but this does not play a decisive role. My reason is that the security mode is turned on. Just turn off the security mode
cd $HADOOP_HOME/bin
hadoop dfsadmin -safemode leave
Users can
hadoop dfsadmin -safemode value
Operation security mode
value value:
enter: enter security mode
leave: force to leave security mode
get: return to security mode status
wait: until the end of security mode
now:
root@yx:/apps/hadoop/bin# hadoop fs -ls /
20/04/25 19:24:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - root supergroup 0 2020-04-25 17:13 /test
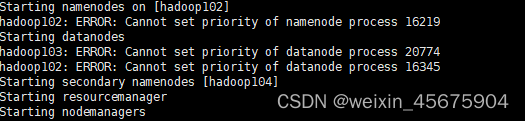
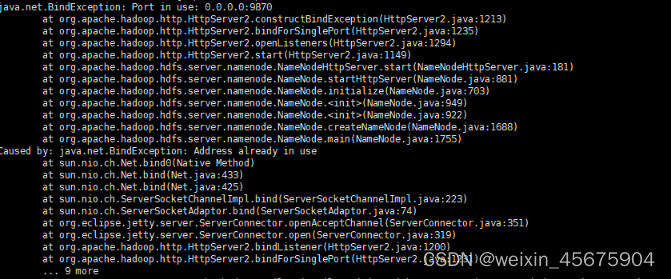


 at first, I thought it was my JDK version. The JDK version of Linux was 1.8 and my windows JDK version was 11.0. I changed the JDK environment variable to 1.8, but the problem remained the same after running.
at first, I thought it was my JDK version. The JDK version of Linux was 1.8 and my windows JDK version was 11.0. I changed the JDK environment variable to 1.8, but the problem remained the same after running.