Solve the problem of error: java.io.eofexception: precondition EOF from InputStream
1. Question
1. Problem process
During the log parsing task, an error is reported suddenly, and the task is always very stable. How can an error be reported suddenly?A tight heart
2. Detailed error type:
Check the log and find the following errors
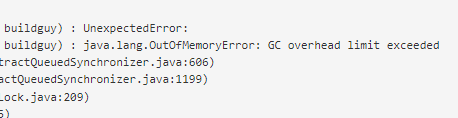
21/11/18 14:36:29 INFO mapreduce.Job: Task Id : attempt_1628497295151_1290365_m_000002_2, Status : FAILED
Error: java.io.EOFException: Premature EOF from inputStream
at com.hadoop.compression.lzo.LzopInputStream.readFully(LzopInputStream.java:75)
at com.hadoop.compression.lzo.LzopInputStream.readHeader(LzopInputStream.java:114)
at com.hadoop.compression.lzo.LzopInputStream.<init>(LzopInputStream.java:54)
at com.hadoop.compression.lzo.LzopCodec.createInputStream(LzopCodec.java:83)
at com.hadoop.mapreduce.LzoSplitRecordReader.initialize(LzoSplitRecordReader.java:58)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:548)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:786)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1907)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
The error is queried through a search engine, and the result points to the upper limit of the dfs.datanode.max.transfer.threads parameter, such as
https://blog.csdn.net/zhoujj303030/article/details/44422415
Viewing the cluster configuration, it is found that the parameter is modified to 8192. Check other problems.
Later, it was found that there was an LZO empty file in the log file. After deletion, the task was executed again and successfully.
2. Solution
To prevent the above problems from happening again, write a script to delete LZO empty files before performing the parsing task
1. Traverse the files under the specified path
for file in `hdfs dfs -ls /xxx/xxx/2037-11-05/pageview | sed '1d;s/ */ /g' | cut -d\ -f8`;
do
echo $file;
done
Result output:
/xxx/xxx/2037-11-05/pageview/log.1631668209557.lzo
/xxx/xxx/2037-11-05/pageview/log.1631668211445.lzo
2. Judge whether the file is empty
for file in `hdfs dfs -ls /xxx/xxx/2037-11-05/pageview | sed '1d;s/ */ /g' | cut -d\ -f8`;
do
echo $file;
lzoIsEmpty=$(hdfs dfs -count $file | awk '{print $3}')
echo $lzoIsEmpty;
if [[ $lzoIsEmpty -eq 0 ]];then
# is empty, delete the file
hdfs dfs -rm $file;
else
echo "Loading data"
fi
done
3. Final script
for type in webclick error pageview exposure login
do
isEmpty=$(hdfs dfs -count /xxx/xxx/$do_date/$type | awk '{print $2}')
if [[ $isEmpty -eq 0 ]];then
echo "------ Given Path:/xxx/xxx/$do_date/$type is empty"
else
for file in `hdfs dfs -ls /xxx/xxx/$do_date/$type | sed '1d;s/ */ /g' | cut -d\ -f8`;
do
echo $file;
lzoIsEmpty=$(hdfs dfs -count $file | awk '{print $3}')
echo $lzoIsEmpty;
if [[ $lzoIsEmpty -eq 0 ]];then
echo Delete Files: $file
hdfs dfs -rm $file;
fi
done
echo ================== Import log data of type $do_date $type into ods layer ==================
... Handling log parsing logic
fi
done