java.lang.ClassCastException: class date2021_11_27_5.Commodity at java.lang.Class.asSubclass(Unknown Source) at org.apache.hadoop.mapred.JobConf.getOutputKeyComparator(JobConf.java:887) at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1004) at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402) at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) at java.util.concurrent.FutureTask.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) at java.lang.Thread.run(Unknown Source) 2021-11-29 10:00:26,301 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete. 2021-11-29 10:00:26,302 WARN [org.apache.hadoop.mapred.LocalJobRunner] - job_local49120036_0001 java.lang.Exception: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :class date2021_11_27_5.Commodity at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) Caused by: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :class date2021_11_27_5.Commodity at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:415) at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) at java.util.concurrent.FutureTask.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) at java.lang.Thread.run(Unknown Source) Caused by: java.lang.ClassCastException: class date2021_11_27_5.Commodity at java.lang.Class.asSubclass(Unknown Source) at org.apache.hadoop.mapred.JobConf.getOutputKeyComparator(JobConf.java:887) at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1004) at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402) ... 10 more
How to Solve:
This is because the custom entity class does not implement the WritableComparable<Commodity> interface, or does not override the compareTo method, resulting in a class conversion exception due to lack of serialization.
There is another possibility that
Implementing the WritableComparable<Commodity> interface instead of the WritableComparable<Commodity> interface because of the mapreducer rules
This implementation of two interfaces will result in the above error message when using a custom entity class for the value without problems, but when using a custom entity class for the key
Just reimplement the WritableComparable<Commodity> interface and guide the package
Hadoop specifies that if you implement the Writable and Comparable<Commodity> interfaces, the data of the custom entity class can only be used as value, but if you implement the WritableComparable<Commodity> interface, the data of the custom entity class can be used as both key and value.
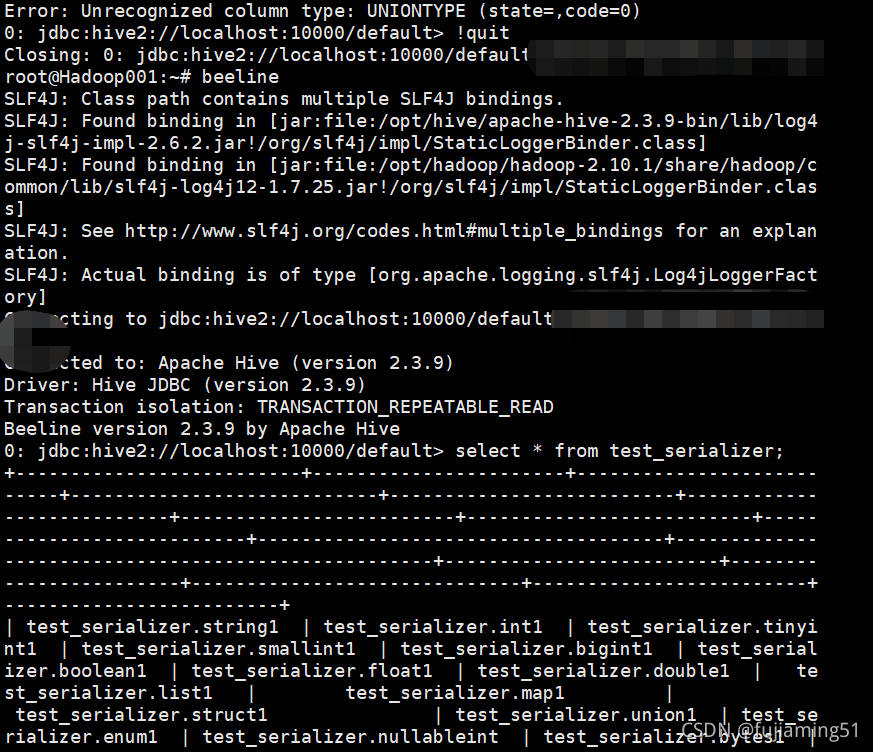
 view
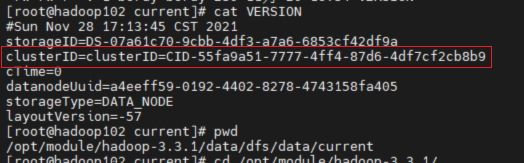
view 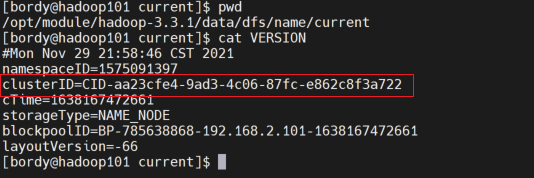 found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.
found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.




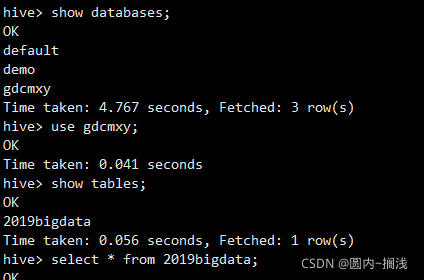

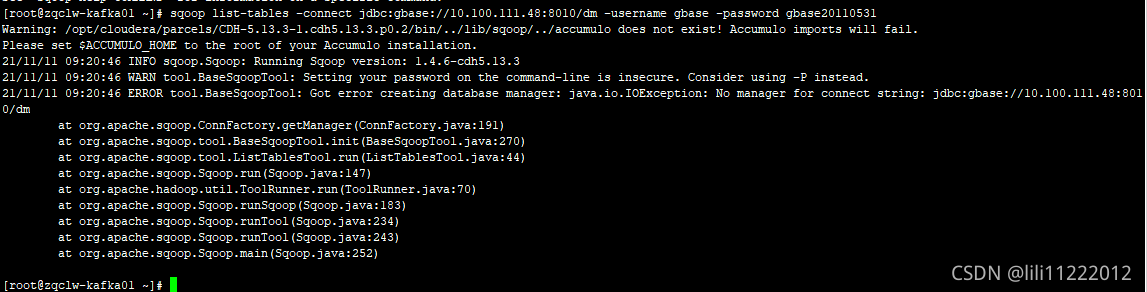
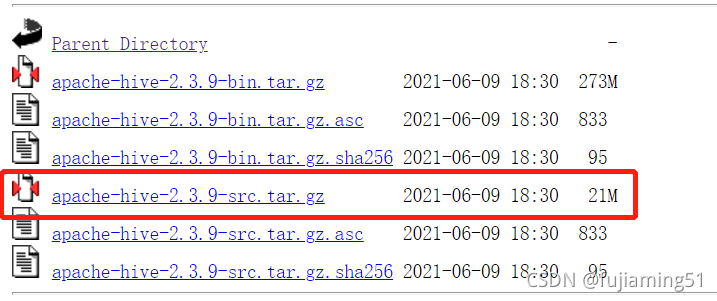
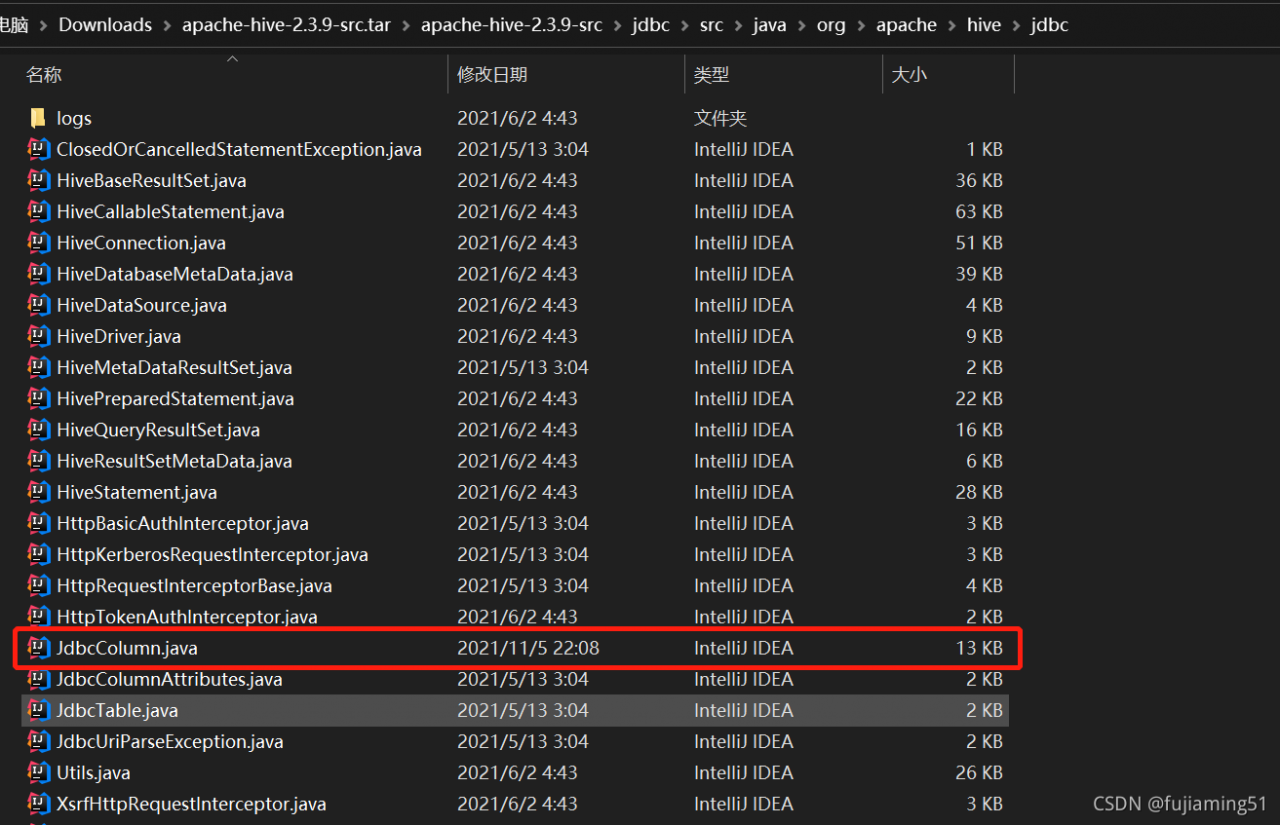
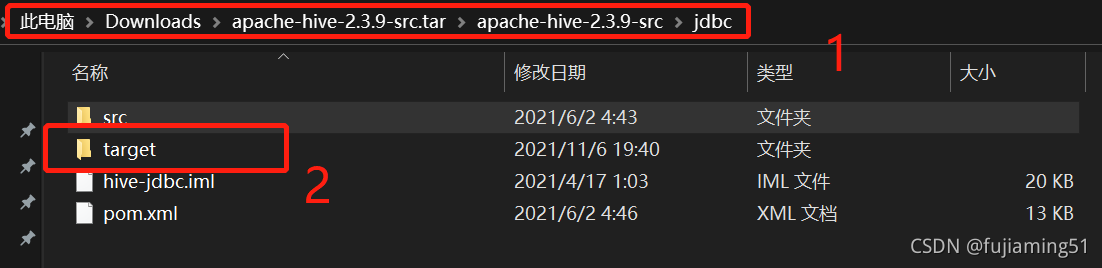
 After packaging, find hive-jdbc-2.3.9-standalone.jar and hive-jdbc-2.3.9.jar in the target directory under the JDBC directory, copy them to {$hive_home}/JDBC and {$hive_home}/lib directories respectively, and restart hiverver2:
After packaging, find hive-jdbc-2.3.9-standalone.jar and hive-jdbc-2.3.9.jar in the target directory under the JDBC directory, copy them to {$hive_home}/JDBC and {$hive_home}/lib directories respectively, and restart hiverver2: