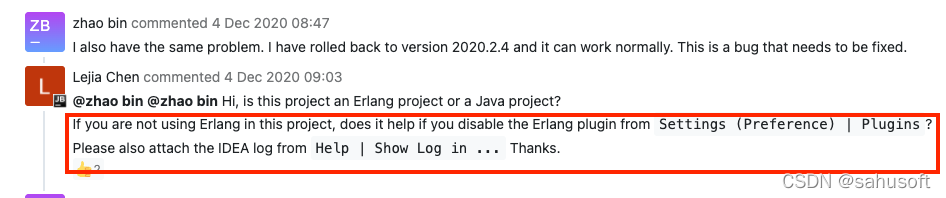
Error when running the project to connect to Spark:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/10/08 21:02:10 INFO SparkContext: Running Spark version 3.0.0
22/10/08 21:02:10 ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:380)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:120)
at test.wyh.wordcount.TestWordCount$.main(TestWordCount.scala:10)
at test.wyh.wordcount.TestWordCount.main(TestWordCount.scala)
22/10/08 21:02:10 INFO SparkContext: Successfully stopped SparkContext
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:380)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:120)
at test.wyh.wordcount.TestWordCount$.main(TestWordCount.scala:10)
at test.wyh.wordcount.TestWordCount.main(TestWordCount.scala)
Process finished with exit code 1Solution:
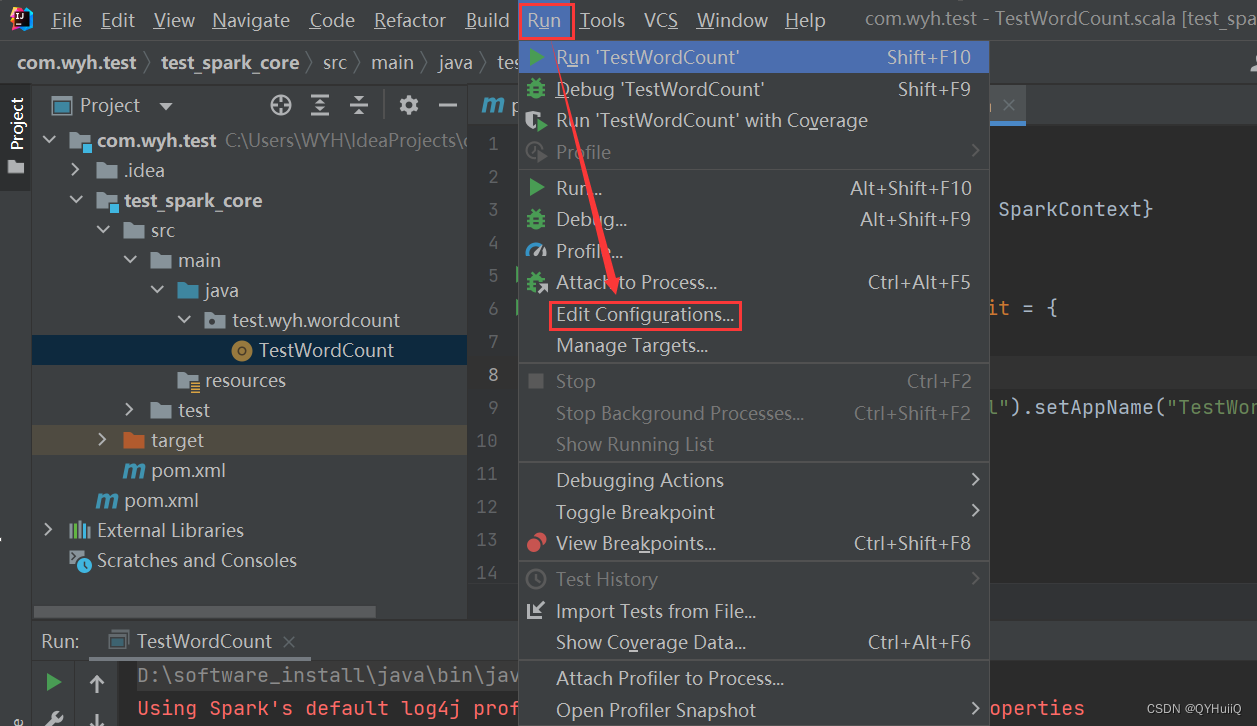
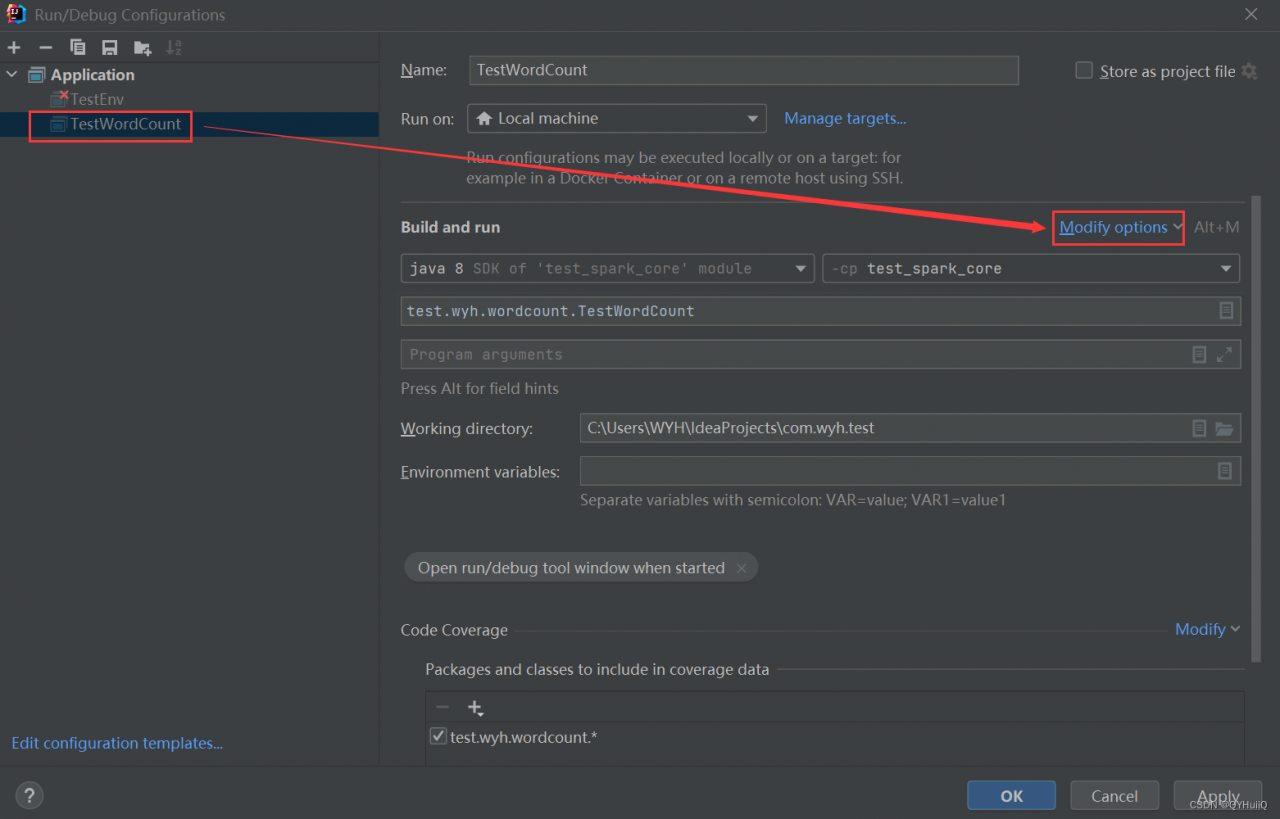

Configure the following parameters:
-Dspark.master=local[*]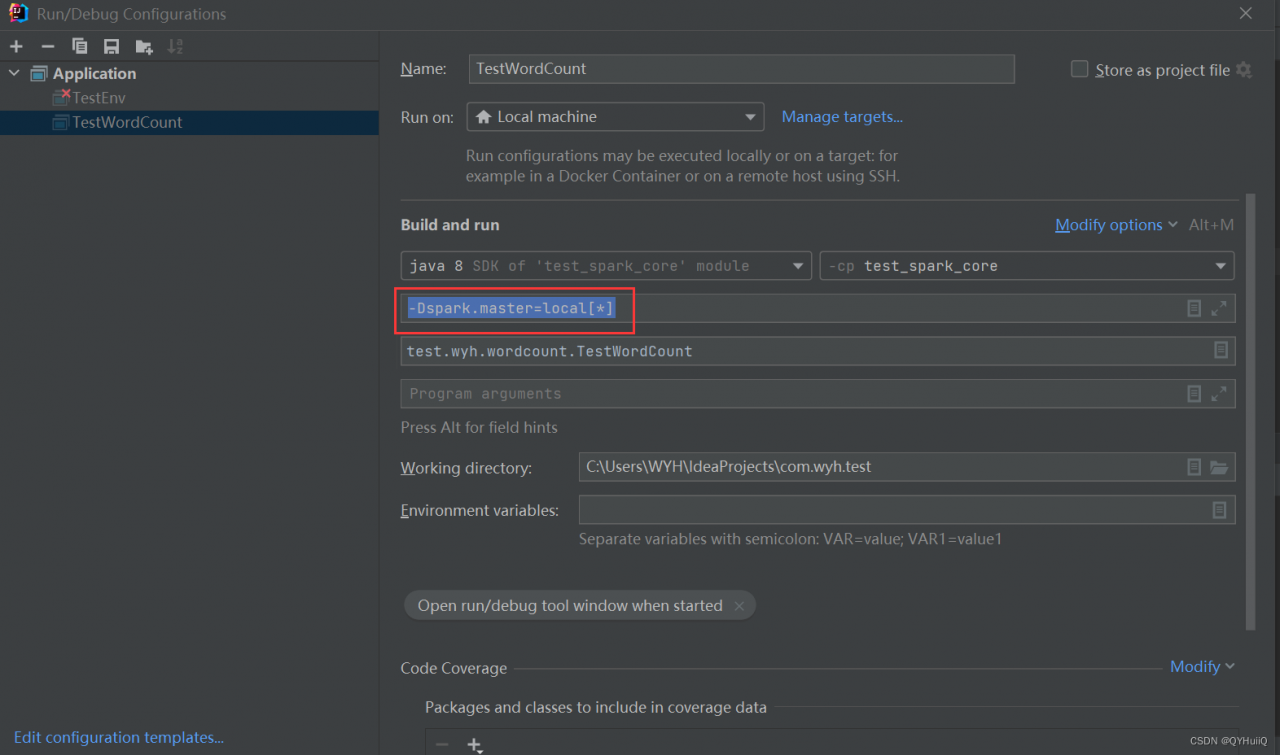
Restart IDEA.
 Reference:
Reference: