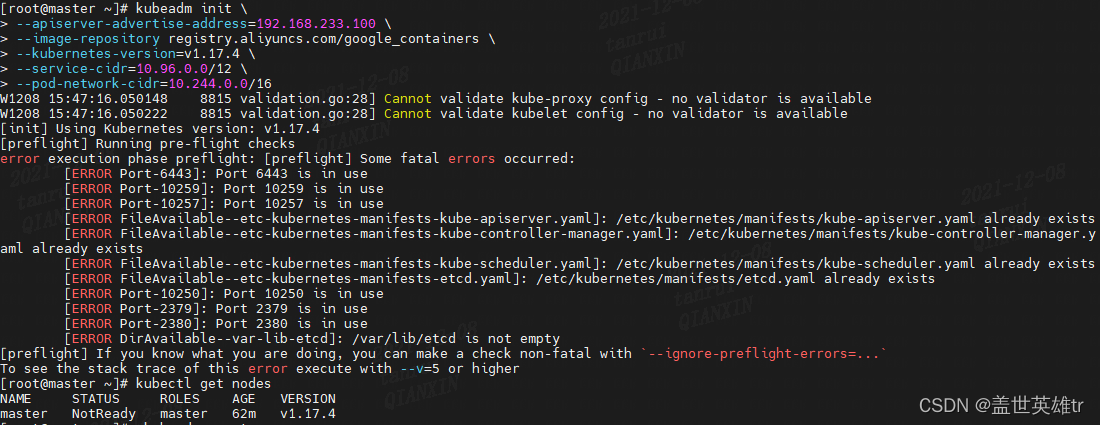
redis-cli -p 12345 [root@localhost ~]# redis-cli -p 6379 127.0.0.1:6379> auth "123456" OK 127.0.0.1:6379> info # Server redis_version:3.2.12 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:7897e7d0e13773f redis_mode:standalone os:Linux 3.10.0-1127.19.1.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.8.5 process_id:1242 run_id:XXX tcp_port:6379 uptime_in_seconds:1186639 uptime_in_days:13 hz:10 lru_clock:11977524 executable:/usr/bin/redis-server config_file:/etc/redis.conf # Clients connected_clients:1 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 # Memory used_memory:3486652368 used_memory_human:3.25G used_memory_rss:3548164096 used_memory_rss_human:3.30G used_memory_peak:3486886808 used_memory_peak_human:3.25G total_system_memory:16637546496 total_system_memory_human:15.49G used_memory_lua:37888 used_memory_lua_human:37.00K maxmemory:0 maxmemory_human:0B maxmemory_policy:noeviction mem_fragmentation_ratio:1.02 mem_allocator:jemalloc-3.6.0 # Persistence loading:0 rdb_changes_since_last_save:8 rdb_bgsave_in_progress:0 rdb_last_save_time:1639367433 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:20 rdb_current_bgsave_time_sec:-1 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok # Stats total_connections_received:3831251 total_commands_processed:18072447 instantaneous_ops_per_sec:15 total_net_input_bytes:1538227697 total_net_output_bytes:907587826299 instantaneous_input_kbps:0.61 instantaneous_output_kbps:3.07 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 evicted_keys:0 keyspace_hits:7332354 keyspace_misses:6533 pubsub_channels:0 pubsub_patterns:0 latest_fork_usec:2025 migrate_cached_sockets:0 # Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # CPU used_cpu_sys:1586.86 used_cpu_user:625.00 used_cpu_sys_children:3198.40 used_cpu_user_children:46091.06 # Cluster cluster_enabled:0 # Keyspace db0:keys=936,expires=0,avg_ttl=0
redis maxmemory:0 There is no limit to the amount of memory that can be used.
linux
[root@localhost redis]# sysctl -a|grep overcommit_memory
vm.overcommit_memory = 0
vm.overcommit_memory = 0 Heuristic The size of the virtual memory allocated for this request and the current free physical memory on the system plus swap determine whether to release it. When the system allocates virtual address space for the application process, it determines whether the size of the currently requested virtual address space exceeds the remaining memory size, and if it does, the virtual address space allocation fails.
When redis saves in-memory data to disk, in order to prevent the main process from falsely dying, it forks a child process to complete this save operation. However, the forked subprocess will need to allocate the same amount of memory as the main process, which is equivalent to double the amount of memory needed, and if there is not enough memory available to allocate the required memory, the forked subprocess will fail to save the data to disk.
/etc/redis.conf
[root@localhost etc]# more redis.conf |grep “stop-writes-on-bgsave-error”
stop-writes-on-bgsave-error yes
stop-writes-on-bgsave-error: Whether to continue processing Redis write commands when generating RDB files with errors, the default yes Redis does not allow users to perform any update operations
Reasons.
1 The memory of redis itself is not limited. maxmemory:0.
2 redis forks the same memory as the main process when it forks the process to save data, which is memory double.
3 linux server vm.overcommit_memory = 0, which does not allow excessive memory overcommits.
4 redis configuration file default stop-writes-on-bgsave-error, which does not allow users to exceed when writes fail.
Optimization suggestions.
Modify vm.overcommit_memory = 0 vm.overcommit_memory = 1