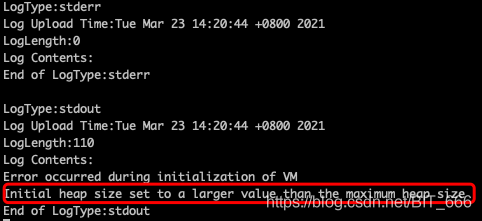
MSBUILD : error MSB3428: Could not load the Visual C++ component “VCBuild.exe”.
This problem occurs in the install front-end project
MSBUILD : error MSB3428: Could not load the Visual C++ component “VCBuild.exe”…
Solution:
1. The administrator opens CMD and sets the agent (optional, if you have one)
set HTTP_PROXY=http://127.0.0.1:1080
set HTTPS_PROXY=http://127.0.0.1:1080
2. Install windows build tool
npm install -g --production windows-build-tools
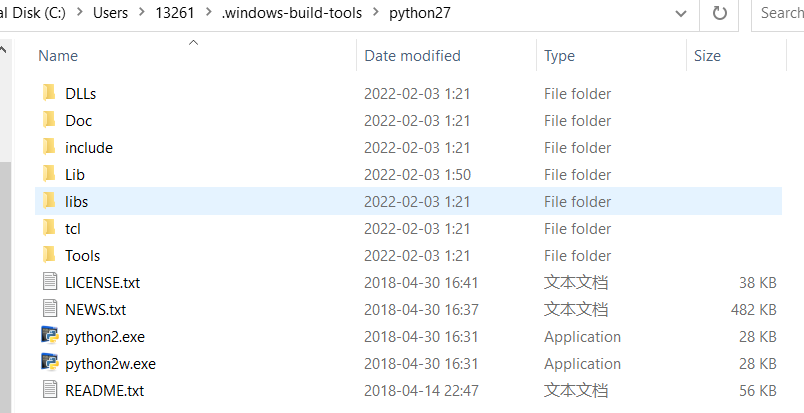
3. If the card is completely stuck, wait for one minute, and then enter C:\Users\Username\.windows-build-tools
If there is a file in the figure below, the download is successful, and if there is no file, the download fails
If the download fails, download it manually and extract it to C:\Users\Username\
The final status is shown in the figure:
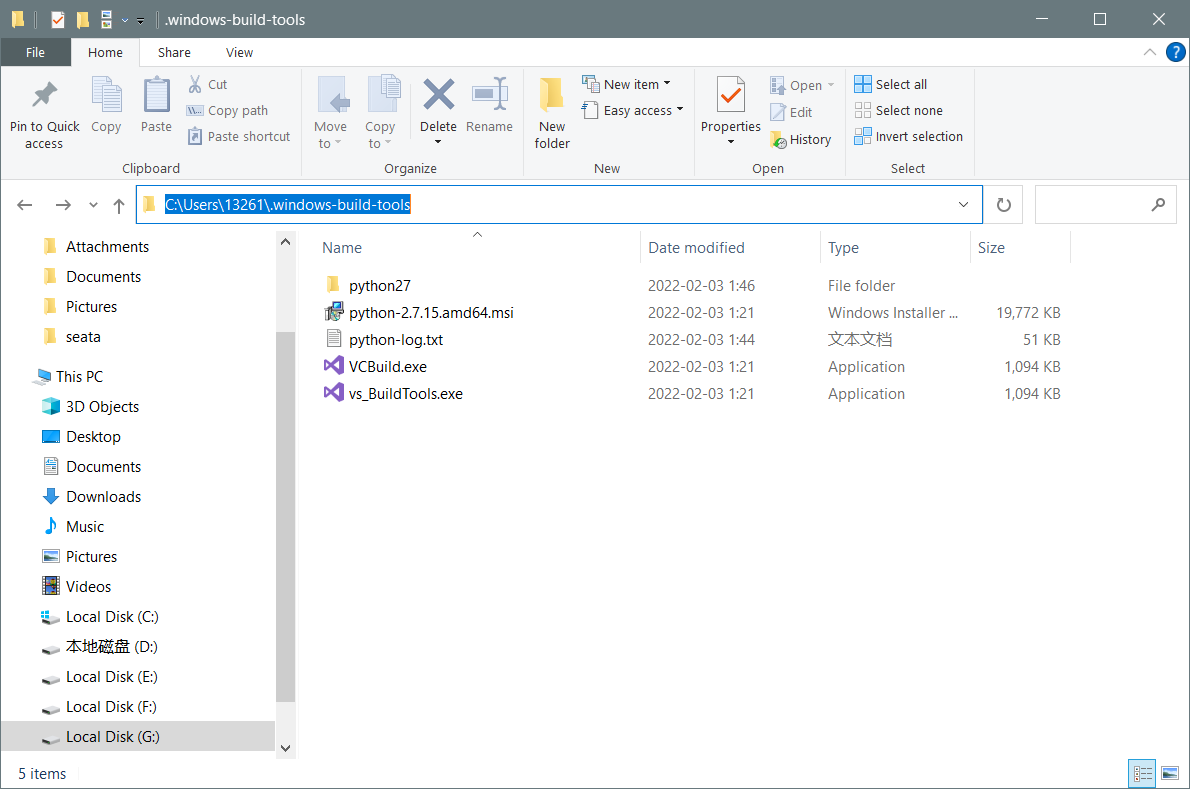
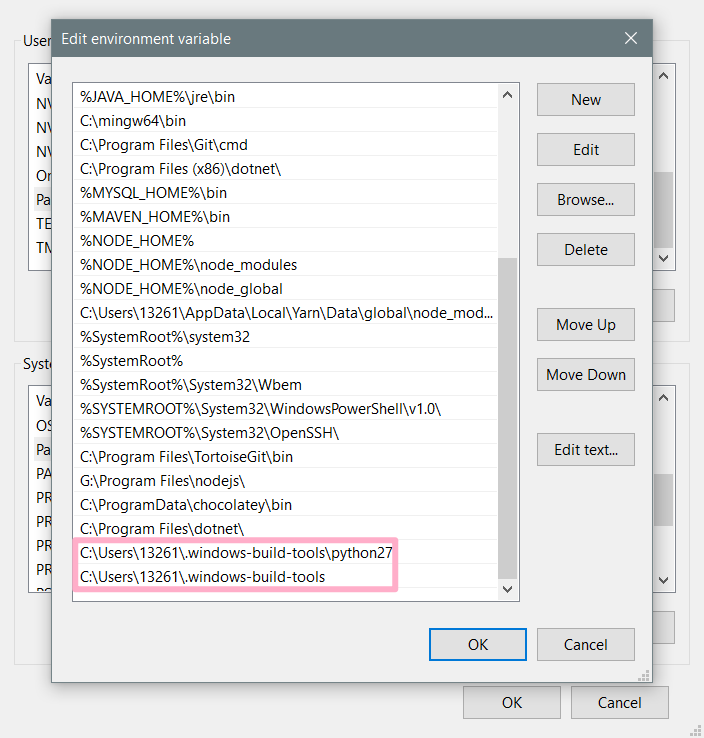
5 Configure system environment variables (Setting -> advanced system settings -> environment variables)
Append to path item
C:\Users\13261.windows-build-tools
C:\Users\13261.windows-build-tools\python27
6. change the file name
Because the problem I encountered was MSBUILD : error MSB3428: Could not load the Visual C++ component “VCBuild.exe”…
The project will use the executable file VCBuild.exe to build
So I made a copy of vs_BuildTools.exe and modified it to VCBuild.exe, so that cmd can use “VCBuild”!
Because I have already installed python3 or higher, the command is also “python”
so python2.7 I will also modify the executable to python.exe -> python2.exe, pythonw.exe -> python2w.exe
TIP: If your front-end project will be built with commands like “python2” or “python3” instead of “python” to execute python code, then you also need to rename the executable
Translated with www.DeepL.com/Translator (free version)
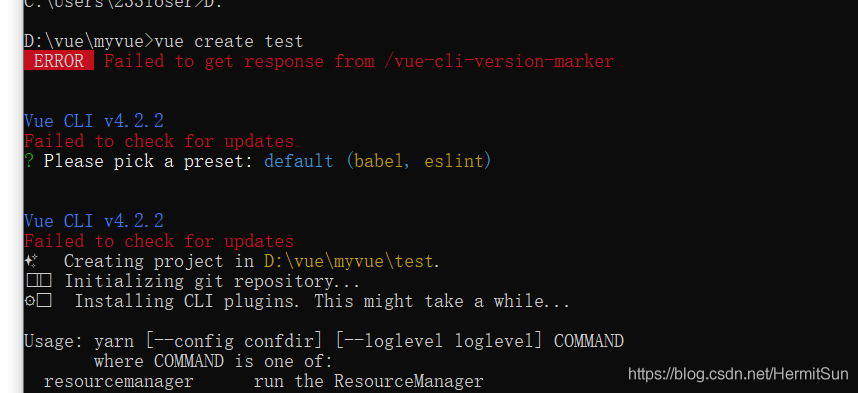
 At first, I thought it was a version problem. After all, the error message said update, but the version of CLI was the latest. After asking, the node and NPM versions were also the latest (12.16.1, which was the latest as of the time I wrote this article). Most importantly, there was no old version of Vue cli
At first, I thought it was a version problem. After all, the error message said update, but the version of CLI was the latest. After asking, the node and NPM versions were also the latest (12.16.1, which was the latest as of the time I wrote this article). Most importantly, there was no old version of Vue cli