Recently in the course design, the main process is to collect data from the CSV file, store it in HBase, and then use MapReduce for statistical analysis of the data. During this period, we encountered some problems, which were finally solved through various searches. Record these problems and their solutions here.
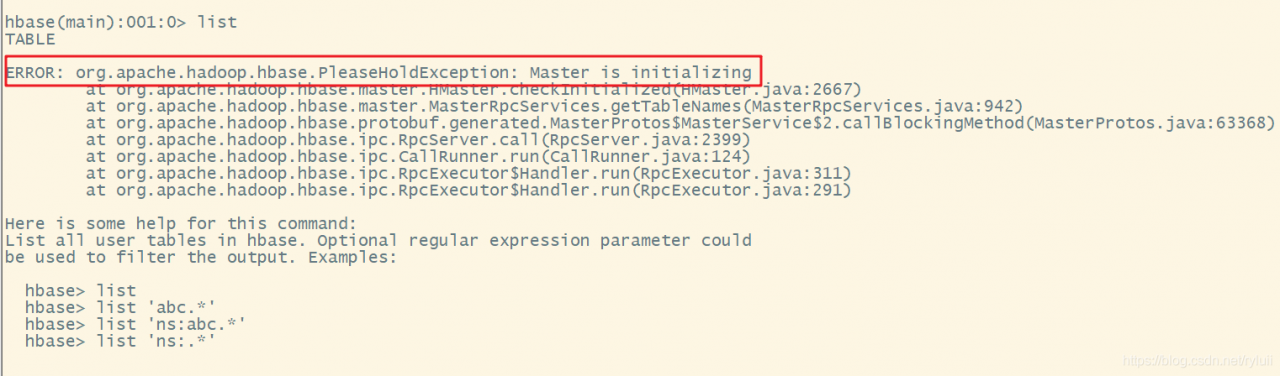
1. HBase hmaster auto close problem
Enter zookeeper, delete HBase data (use with caution), and restart HBase
./zkCli.sh
rmr /hbase
stop-hbase.sh
start-hbase.sh
2. Dealing with multi module dependency when packaging with Maven
The project structure is shown in the figure below
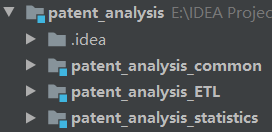
ETL and statistics both refer to the common module. When they are packaged separately, they are prompted that the common dependency cannot be found and the packaging fails.
Solution steps:
1. To do Maven package and Maven install for common, I use idea to operate directly in Maven on the right.
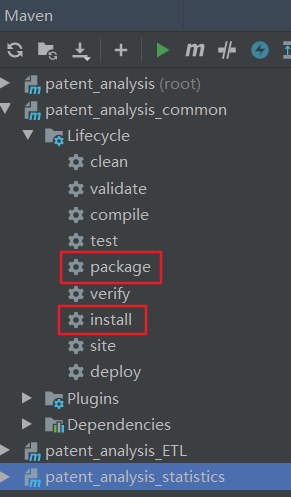
2. Run Maven clean and Maven install commands in the outermost total project (root)
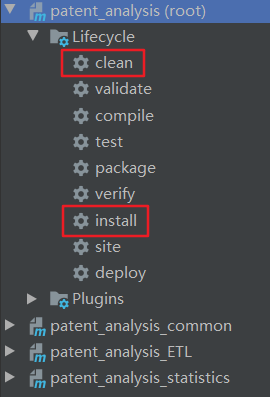
After completing these two steps, the problem can be solved.
3. When the Chinese language is stored in HBase, it becomes a form similar to “ XE5 x8f x91 Xe6 x98 x8e”
The classic Chinese encoding problem can be solved by calling the following method before using.
public static String decodeUTF8Str(String xStr) throws UnsupportedEncodingException {
return URLDecoder.decode(xStr.replaceAll("\\\\x", "%"), "utf-8");
}
4. Error in job submission of MapReduce
Write the code locally, type it into a jar package and run it on the server. The error is as follows:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.mapreduce.Job.getArchiveSharedCacheUploadPolicies(Lorg/apache/hadoop/conf/Configuration;)Ljava/util/Map;
at org.apache.hadoop.mapreduce.v2.util.MRApps.setupDistributedCache(MRApps.java:491)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:92)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:172)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:788)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:240)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at MapReduce.main(MapReduce.java:49)
Solution: add dependencies
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
Among them
Hadoop-mapreduce-client-core.jar supports running on a cluster
Hadoop-mapreduce-client-common.jar supports running locally
After solving the above problems, my code can run smoothly on the server.
Finally, it should be noted that the output path of MapReduce cannot already exist, otherwise an error will be reported.
I hope this article can help you with similar problems.


 At first, I thought it was a version problem. After all, the error message said update, but the version of CLI was the latest. After asking, the node and NPM versions were also the latest (12.16.1, which was the latest as of the time I wrote this article). Most importantly, there was no old version of Vue cli
At first, I thought it was a version problem. After all, the error message said update, but the version of CLI was the latest. After asking, the node and NPM versions were also the latest (12.16.1, which was the latest as of the time I wrote this article). Most importantly, there was no old version of Vue cli