Set up automatic networking alias for @Mac terminal
#= alias for connect wifi.
alias lsnt=‘networksetup -listallhardwareports’ # list network device
alias lswf=’/System/Library/PrivateFrameworks/Apple80211.framework/Versions/A/Resources/airport scan’ # scan wifi, and show list
alias onwf=‘networksetup -setairportpower en0 on’
alias offwf=‘networksetup -setairportpower en0 off’
alias lkwf=‘networksetup -setairportnetwork en0’
#- alias lk413=‘networksetup -setairportnetwork en0 HUAWEI-xxx passwd’
alias lk413=‘lkwf HUAWEI-xxx passwd’
alias lsbb=‘lsbb(){ lswf | grep pi | cut -c 23-32 | grep “$1” ;}; lsbb’ # scan BB wifi, and show list
alias lkbb=‘lkbb(){ lkwf “$1” passwd ; }; lkbb’
alias lkb=‘lkb(){ lkwf lsbb "$1" passwd ; }; lkb’
Tag Archives: Method documentation
MySQL driver compiling method of QT under windows and solutions to abnormal errors
2015-11-20
Recently, in the process of compiling QT’s MySQL driver with MinGW under windows, it was compiled through several twists and turns. In the process of compiling, there are many problems. In order to avoid similar errors in the subsequent driver compilation and facilitate the rapid completion of this driver compilation, the compilation methods are sorted out.
This method is illustrated by a case of my own compiling environment.
1、 Compiling environment
Operating system: win7 64 bit
MySQL service version: mysql-5.5.46-win32
QT version: 4.8.6
Compiling environment: MinGW 64 bit
2、 Compilation steps
(1) Generate libmysql. A file
Because MinGW compiler needs to use “. A” suffix static library file to connect with static library, but according to MySQL database, there is only “. Lib” format static library, so it needs to be converted. Two tools are needed for conversion reimp.exe and dlltool.exe The paths of these two tools need to be configured in the path environment variable. The conversion command is as follows:
First of all, open the CMD command input box and enter the Lib path under the MySQL installation path. For example, my path is: “C:// program files (x86) MySQL MySQL server 5.5 lib”.
Next, enter the following commands in turn:
reimp -d libmysql.lib
dlltool -k -d libmysql.def -l libmysql.a
After successful execution, you can view the library file of libmysql. A in this path.
(2) Editor mysql.pro Engineering documents
Find it in the installation path of QT mysql.pro The path of my pro file is: “C:// Qt/4.8.6/SRC/plugins/sqldrivers/MySQL”.
open mysql.pro File, add the following configuration below:
INCLUDEPATH+=”C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/include/”
LIBS+= -L”C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/” –llibmysql
The second line can also be written as follows:
LIBS+= “C:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/libmysql.a”
Makefile Makefile.Debug 、 Makefile.Release Three makefile files and others. As shown in the figure below:
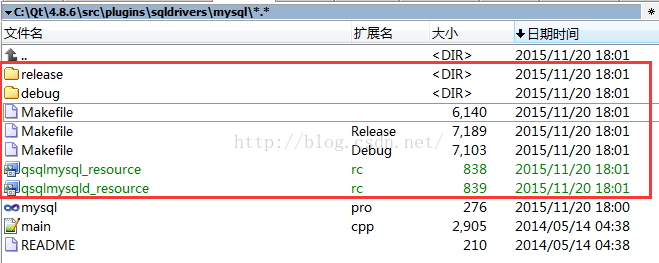
(3) Edit makefile file
Take the debug version as an example. open Makefile.Debug File, find LIBS = “XXXX” line and modify it. Because there is a problem with this configuration generated.
The original configuration is as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o -llibmysql “-LC:/ProgramFiles(x86)/MySQL/MySQL Server 5.5/lib/” -llibmysql -lQtSqld4 -lQtCored4
According to our intention, according to makefile’s syntax rules, we can clearly find the problem. First of all, “L” must be placed outside the path of the configuration library. Second, the – llibmysql command has repetition.
It is revised as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o -L “C:/Program Files(x86)/MySQL/MySQLServer 5.5/lib/” -llibmysql -lQtSqld4 -lQtCored4
Or it can be modified as follows:
LIBS = -L”c:\Qt\4.8.6\lib”debug\qsqlmysqld_ resource_ res.o “C:/Program Files(x86)/MySQL/MySQL Server5.5/lib/libmysql.a” -lQtSqld4 -lQtCored4
The release version of makefile is modified in the same way.
(4) Execute the make command
Use the mingw32 make command to execute makefile. If no parameter is added, it will be executed by default Makefile.Debug . You can write debug or release or both after mingw32 make command to execute the corresponding version of makefile.
For example, execute debug and release makefile at the same time. The command is as follows:
mingw32-make debug release
After successful execution, you can see qsqlmysqld. A qsqlmysqld.dll Two library files, in the release folder, see qsqlmysql. A qsqlmysql.dll Two library files.
These four library files are the static library and dynamic library driven by MySQL of debug and release versions.
(5) Copy the driver file to the specified directory
Copy the four driver files generated in the previous step to the database driver directory of QT, that is, under the path of “C:: (QT) ﹣ 4.8.6 ﹣ plugins ﹣ sqldrivers”.
(6) Copy libmysql.dll File to specified directory
Install the libmysql.dll Copy the dynamic library file to the bin directory of QT, i.e. “C:// Qt/4.8.6/plugins/sqldrivers”. At this point, use QT to write a program to connect to MySQL database.
3、 Test whether the driver is available
Write demo program to test QT driver. The main codes are as follows:
#include <QtCore/QCoreApplication>
#include <QDebug>
#include <QStringList>
#include <QString>
#include <QSqlDatabase>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
qDebug()<<“Available drivers:”;
QStringList drivers = QSqlDatabase::drivers();
foreach(QString driver,drivers)
qDebug()<<“\t”<<driver;
return a.exec();
}
Add in project file
QT +=sql
Running this demo program, you can see “qmysql3” and “qmmysql” in the list of available drivers. As shown in the figure below:
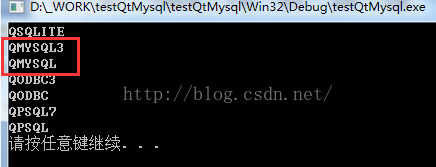
4、 Common problems and Solutions
(1) Cannot find – llibmysql
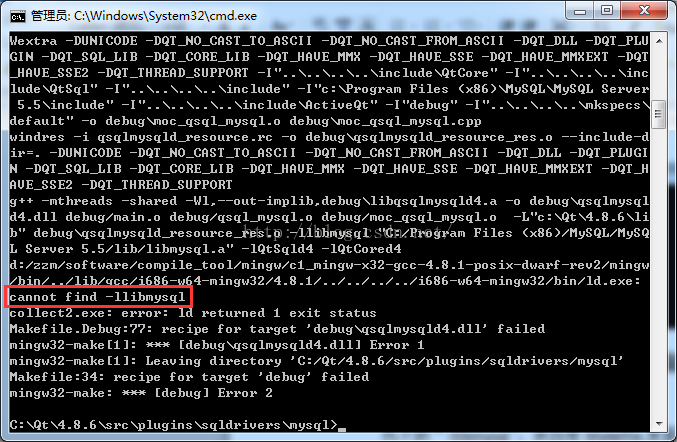
“- llibmysql” cannot be found because the configuration in makefile is incorrect. After modifying Makefile, compile it again, and the compilation passes.
The solution to this problem is: check the configuration in Makefile, modify it to conform to the rules of makefile syntax, and then try again.
(2) Undefined reference to ‘MySQL’_ character_ set_ name@4 ’
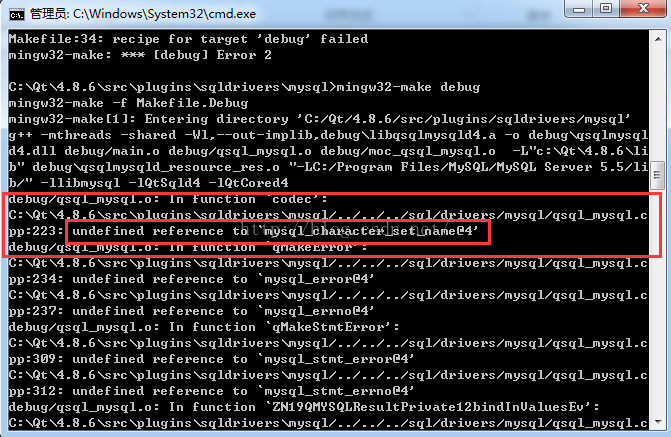
This situation, as well as a series of undefined references related to MySQL, is due to a problem loading the MySQL library. After online query of relevant information, we know that it is the version problem of MySQL database. When using the link library in 64 bit MySQL database, we will report this error.
The solution is to install a 32-bit MySQL database and configure it mysql.pro File, compile the driver again, and the error will not appear again.
(3) Unrecognized command line option \ “- fno keep inline dllexport \”
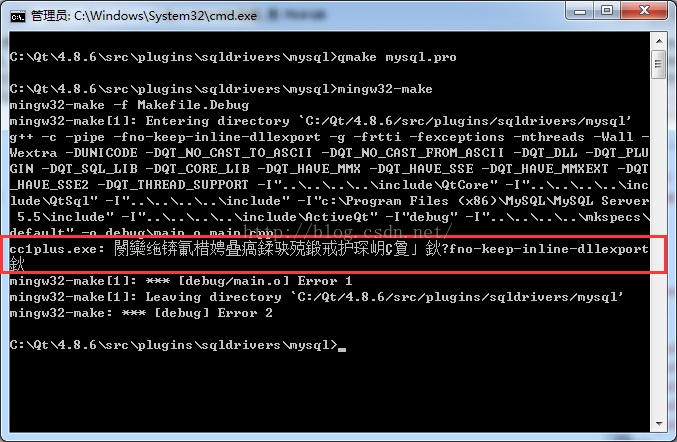
The reason for this error is that the version of the compiler is relatively low. To query the version of the currently used gcc compiler is GCC – 4.4.0. The explanation of the online information is as follows:
this is because\”-fno-keep-inline-dllexport\” is the option of mingw 4.6.1, but i’musing 4.5. So I change it by installingcodelite-3.5.5377-mingw4.6.1-wx2.9.2.exe
The translation is as follows:
This is because the option “- fno keep inline dllexport” is a function of mingw4.6.1. The current version is too low, so the gcc compiler of version 4.6.1 or above is needed.
Later, the MinGW compiler environment of 4.8.1 version of gcc compiler was installed. When compiling this driver, the above error disappeared.
Therefore, the solution to this problem is to install the gcc compiler above 4.6.1.
How to use C + + function pointer array
2015-11-24
1、 Origin
Under what circumstances did you come up with an array of function pointers?Because there are a series of sequential functions in a program recently written, and the forms of these functions are basically the same, it is necessary to judge the execution result of each step, whether the execution is successful or not. If the execution is successful, the next function will continue to be executed. If the execution fails, the terminal will execute and exit.
Because there are many functions to be executed in turn, there are five. To write code according to the conventional way of thinking is to judge the result of each step by if-else, and decide the content of the next step according to the result. At present, there are only five functions to be executed. If there are more similar functions to be executed in sequence, this function will be very long, not easy to read, and the code will not be beautiful.
Considering that the parameter list and return value of the current function are basically the same, we consider whether we can traverse the function pointer array, store the function pointer in the array and traverse the array, so as to execute the function pointed to by the corresponding pointer in turn, judge the results one by one, and do the corresponding processing. In this way, the result processing part can adopt a unified way, which is very convenient to judge, the code is also very simple and clear, and it is easy to read.
So online query related information, to understand the use of function pointer array. Through data query, the use of C + + function pointer array can be divided into two categories, one is the use of global function pointer array (the same as C language), the other is the use of C + + member function pointer array. Now the two cases are sorted out respectively.
2、 The use of global function pointer array in C
(1) Requirements
1. The parameter list and return value type of a series of functions to be called should be identical;
2. It is required to put the function pointer to be called into the function pointer array (if the function must have sequential execution, then the storage order of the function pointer should be consistent with the calling order);
3. When calling, take out the function pointer to be executed from the array and execute the corresponding function.
(2) Code case
Reference from: http://blog.csdn.net/feitianxuxue/article/details/7300291
#include <iostream>
using namespace std;
void function0(int);
void function1(int);
void function2(int);
int _ tmain(int argc, _ TCHAR* argv[])
{
Void (* f [3]) (int) = {function0, function1, function2};// save the three function pointers in the array F
intchoice;
cout<< “Enter a number between 0 and 2,3 to end: “;
cin>> choice;
//handle user selection
while((choice >= 0) && (choice <3))
{
//call a function in the array f
(* f [choice]) (choice);// F [choice] select the pointer whose position is choice in the array.
//the pointer is dereferenced to call the function, and choice is passed as an argument to the function.
cout<< “Enter a number between 0 and 2,3 to end: “;
cin>> choice;
}
cout<< “Program execution completed.” << endl;
system(“pause”);
return0;
}
void function0(int a)
{
cout<< “You entered” << a << ” so function0 wascalled\n\n”;
}
void function1(int b)
{
cout<< “You entered” << b << ” so function1 wascalled\n\n”;
}
void function2(int c)
{
cout<< “You entered” << c << ” so function2 wascalled\n\n”;
}
3、 The use of pointer array of member function in C + + class
(1) Requirements
When using the pointer array of member function in C + + class, it is different from that of C. The requirements are as follows:
1. It is required that the parameter list and return value type of the member function put into the function pointer array are completely consistent;
2. Define a function pointer array, and specify the length of the array (equal to the number of member functions to be stored), and assign the member function pointer to the corresponding array variable during initialization (if the function must have sequential execution, the storage order of the function pointer should be consistent with the calling order);
3. When calling, take out the function pointer to be executed from the array and execute the corresponding function. When calling, use “& gt; *” or “. *” to point to array elements, otherwise an error will be reported during compilation.
(2) Code case
Reference from: http://www.cppblog.com/dragon/archive/2010/12/02/135250.html
/*
* small program for testing pointer array of member function
* key points of the code have been marked in red
*/
#include <iostream>
using namespace std;
class Test
{
public:
Test();
~Test();
private:
void add5(){ res+=5;}
void add6(){ res+=6;}
//this 2 is very important. If it is not written in VC, an error will be reported, but it is not reported in QT, but an error will be reported during the deconstruction!
void (Test::*add[2])();
public:
void DoAddAction();
void Display();
private:
int res;
};
Test::Test()
{
//pay attention to the writing here
add[0]=&Test::add5;
add[1]=&Test::add6;
res=0;
}
Test::~Test()
{
}
void Test::DoAddAction()
{
for (int i=0;i<2;i++)
{
//using class member function pointer must have a call of “& gt; *” or “. *”
(this->*add[i])();
}
}
void Test::Display()
{
cout<<“The res is:”<<res<<endl;
}
int main()
{
Test * test=new Test();
test->DoAddAction();
test->Display();
delete test;
return 0;
}
4、 Summary
The above methods illustrate the method of using function pointer array in C and C + + classes. It is obvious that using function pointer array can call functions more conveniently, make the code concise and beautiful, and provide a level of code quality.
In the future program development process, we encounter similar problems. When we can use the function pointer array, we can try to only use the function pointer array to make the development easier and more fun.
Python uses CX_ Oracle batch insert error report ora-01036 error solution
Recently, in the process of using Python to write data import program, CX is used_ When the Oracle database was imported into Oracle database, there was an error of “ora-01036: illegal variable name/number”. After querying the data and trying, the problem was solved.
The Error statement is:
sql = ‘insert into \”mytable_ a\” values(%s,%s,%s)’
cursor.executemany (sql, data)
As a result, the error “ora-01036: illegal variable name/number” appears.
resolvent:
Change the place holder of parameter transfer to “: 1,: 2,: 3”,
The modified statement is as follows:
sql = ‘insert into \”mytable_ a\” values(:1, :2, :3)’
cursor.executemany (sql, data)
Execute again and solve the problem.
The solution to frequently pop up “cannot find a valid baseurl for repo” error prompt box in CentOS 6.7
The situation is: CentOS 6.7 server cannot connect to the external network normally, and can only be used in the internal network. The “cannot find a valid baseurl for repo” error box pops up frequently. Here’s a screenshot:
As the system is running normally, it does not need to be updated. Therefore, by adjusting the system settings and setting the system to “never check for updates” and “never update”, this error box will not appear in the system. As shown in the figure below:
Oracle quick replacement undo table space method
Undo table space is not enough. There are two ways to deal with it
1. Expand the table space size;
2. Create a new undo table space and delete the original one.
1、 Preliminary operation
Confirm undo table space name
select name from v$tablespace;
Check the occupancy of undo table space and the storage location of data files;
select file_ name,bytes/1024/1024 from dba_ data_ files where tablespace_ name like ‘UNDOTBS1’;
2、 Expand undo table space
alter database UNDOTBS1 datafile ‘/opt/oracle/oradata/inms/undotbs02.dbf’ resize 4000M;
3、 Create a new undo table space and delete the original one
1. Create a new undo table space and set the automatic extension parameters;
create undo tablespace undotbs2 datafile ‘/oradata/oradata/ddptest/UNDOTBS1.dbf’ size 2 1000m reuse autoextend on next 800m maxsize unlimited;
2. Change the SPFILE configuration file dynamically;
alter system set undo_ tablespace=undotbs2 scope=both;
3. Delete the original undo table space;
drop tablespace undotbs1 including contents;
4. Confirm whether the deletion is successful;
select name from v$tablespace;
5. Determine $Oracle_ HOME/dbs/ spfileoinms.ora Whether the content has changed:
$more spfileoinms.ora
*.undo_ management=’AUTO’
*.undo_ retention=10800
*.undo_ tablespace=’UNDOTBS2′
If there is no change, execute the following statement:
SQL> create pfile from spfile;
File created.
6. Delete the data file of the original undo table space, and the file name is the result of the step.
#rm $ORACLE_ BASE/oradata/$ORACLE_ SID/undotbs01.dbf
4、 Conclusion
According to the actual situation, expanding undo table space can only support for a period of time. After running for a period of time, the undo table space data file will eventually reach the upper limit. Therefore, the second scheme is adopted. You can use the script to replace the undotbs1 and undotbs2 table spaces alternately, which can quickly solve the problem.
(1) Script 1: replace the undotbs2 table space with undotbs1
create undo tablespace undotbs1 datafile ‘/u01/oracle/oradata/orcl/UNDOTBS1.dbf’ size 512m reuse autoextend on next 512m maxsize unlimited;
alter system set undo_ tablespace=undotbs1 scope=both;
drop tablespace undotbs2 including contents;
rm ‘/u01/oracle/oradata/orcl/UNDOTBS2.dbf’
(2) Script 2: replace the undotbs1 table space with undotbs2
create undo tablespace undotbs2 datafile ‘/u01/oracle/oradata/orcl/UNDOTBS2.dbf’ size 512m reuse autoextend on next 512m maxsize unlimited;
alter system set undo_ tablespace=undotbs2 scope=both;
drop tablespace undotbs1 including contents;
rm ‘/u01/oracle/oradata/orcl/UNDOTBS1.dbf’
Oracle data file space release
When the data of Oracle database takes up a large space, and the data stored in it does not take up such a large space, the reason may be that the user has deleted some data, but the size of the data file will not automatically shrink. At this time, if you want to reduce the size of the data file, you can use the following methods.
1、 Use the following statement to query data files that can free up space:
select a.file#,
a.name,
a.bytes/1024/1024 CurrentMB,
ceil(HWM * a.block_ size)/1024/1024 ResizeTo,
(a.bytes – HWM * a.block_ size)/1024/1024 ReleaseMB,
‘alter database datafile ”’ || a.name || ”’ resize ‘ ||
ceil(HWM * a.block_ size)/1024/1024 || ‘M;’ ResizeCmd
from v$datafile a,
(SELECT file_ id, MAX(block_ id + blocks – 1) HWM
FROM DBA_ EXTENTS
GROUP BY file_ id) b
where a.file# = b.file_ id(+)
And (a.bytes – HWM * a.block_ size) >0
and rownum < 10
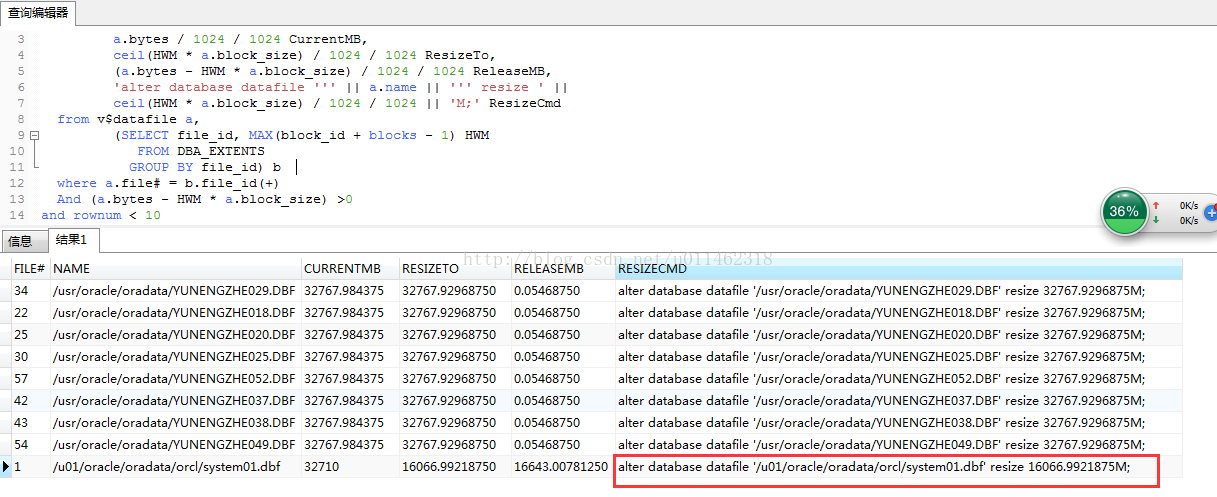
View the data file that belongs to the system table space, and reset it.
2、 Find out the data file that needs to be reset, and execute the reset statement
An error is reported because the reset data file size needs to be set to an integer.

Adjust the size of resize to 16GB, 16384mb;
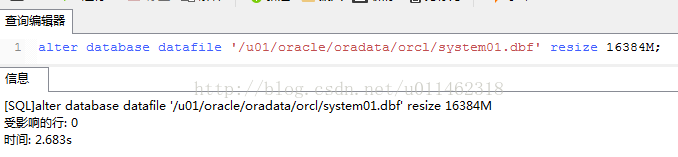
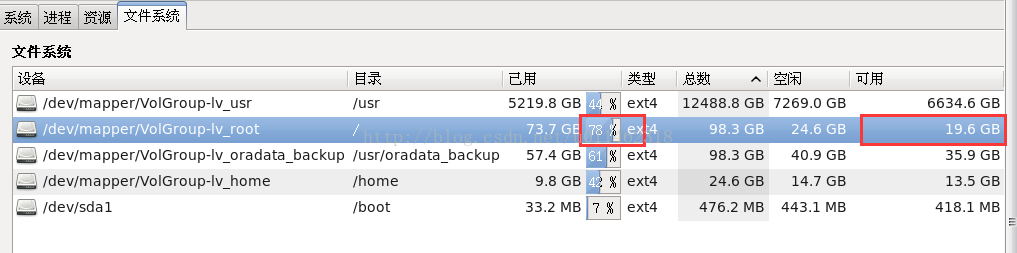
3、 View free disk space
The size of the system file is reduced to 16GB, the remaining space of the root disk is greatly increased to 19.6gb, and the utilization rate is reduced to 78%.
A solution to the problem that the number of nodes does not increase and the name of nodes is unstable after adding nodes dynamically in Hadoop cluster
Problem phenomenon
At present, there are three Hadoop clusters with 01, 02 and 03 nodes, among which 01 is the master node and 02 and 03 are the slave nodes. After dynamically adding 04 slave nodes, the number of nodes displayed in Hadoop web interface does not increase. Further observation shows that the contents of slave nodes in the node list are sometimes 02 and 04 nodes, and sometimes 02 and 03 nodes, which is very strange.
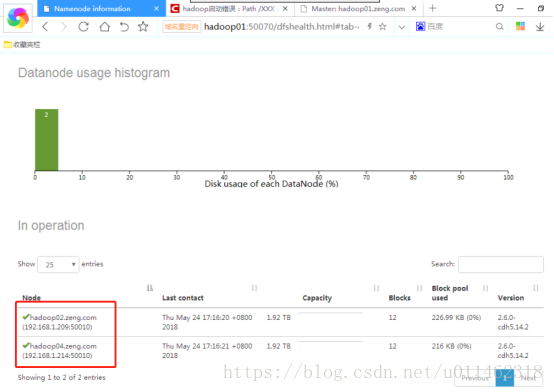
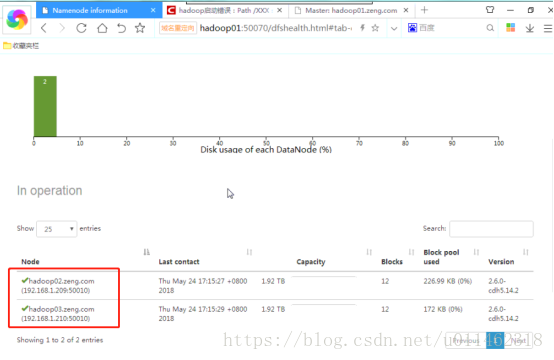
Analyze the reasons
Find the current/version file in the dataDir directory, and the datanodeuuid values in the 03 and 04 servers are exactly the same. It can be inferred that the master node treats 03 and 04 as the same server. The reason is that the 03 server has been started before, and the datanodeuuid has been recorded in the generated version. When the virtual machine is cloned, all the information is the same as the 03 server.
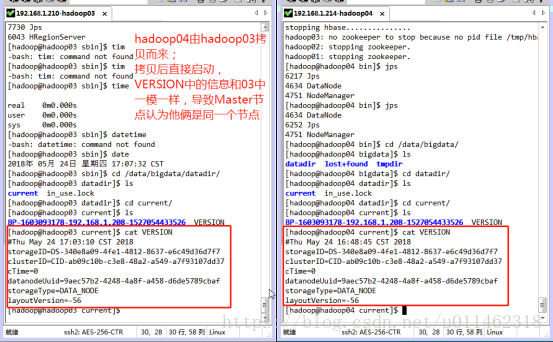
Solution
Considering that if it is not a clone but a direct installation, the dataDir and TMPDIR directories of the 04 server are blank, so stop the datanode and nodemanager services of the 04 server, delete all the files in the dataDir and TMPDIR directories, restart the datanode and nodemanager services, and observe again that the contents of the Hadoop cluster display three datanodes 02, 03 and 04, which are similar to the The expectation is consistent and the problem is solved.
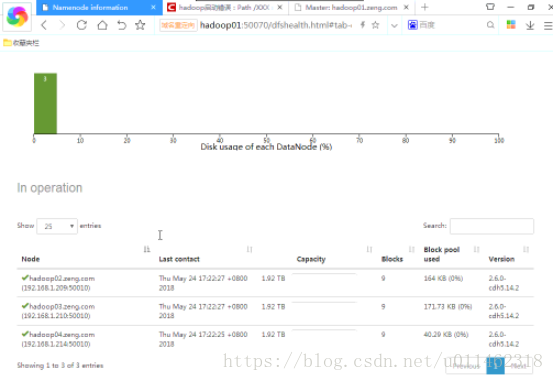
matters needing attention
When adding new nodes by copying or cloning virtual machines, the following operations need to be done:
1. Modify the host name and IP address, restart the new node, and copy the/etc/hosts file to other nodes in the cluster (if using the local DNS server, this step can be omitted, just add the modified node to the domain name resolution record in the DNS server);
2. The new node needs to re run SSH keygen – t RSA to generate the public key and add it to authorized_ And copy it to other nodes in the cluster.
reference material:
1. Hadoop datanode starts normally, but there is no node in live nodes
https://blog.csdn.net/wk51920/article/details/51729460
2. Hadoop 2.7 dynamically adds and deletes nodes
in this paper
https://blog.csdn.net/Mark_ LQ/article/details/53393081
Method of canceling anydesk startup under Windows
Anydesk, a remote connection tool, is not used frequently after installation. It starts automatically every time it is turned on. It takes up resources. Hanging it in the windows tray is very eye-catching.
The solution is as follows:
In the start folder of the start menu, find anydesk, right-click and select Delete.
complete