SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xbe in position 0: invalid start byte
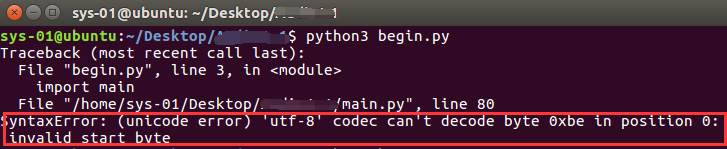
Modify # -*- coding:utf-8 -*- to # coding = gbk
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xbe in position 0: invalid start byte
Modify # -*- coding:utf-8 -*- to # coding = gbk
Question:
When I encountered this problem on the way to write the model, baidu either said it was the pytorch version problem or the category index exceeded, but it was useless, because the error was a very simple assignment operation.
scores[:, 0] = -float("inf")
#RuntimeError: CUDA error: an illegal memory access was encounteredAt the same time, in the process of debugging, it is found that a warning burst after the execution of a network of the model
lm_logits = self.linear(outputs) + self.bias
#warning:Thudacheck FAIL file=/pytorch/aten/c/THC/Thccachinghostallocator cpp Line=278 error=700: an illegal memory access was encounteredAt first glance, both places are relatively simple, but they reported strange mistakes.
Solution:
The debug process found an exception
In the data data output by the pytorch network, the variable does not display the specific network output value, but the address information of the data
T:torch.Tensor object at 0x7fb27e7c8f30
data:torch.Tensor object at 0x7fb27e7c8f30Later, it was found that it was because of self The linear layer is’ CPU ‘, while other networks are on’ CUDA ‘, which is equivalent to the inconsistency caused by the forward propagation of’ CUDA ‘type data to the’ CPU ‘network. Just transfer the network to’ CUDA ‘.
Question
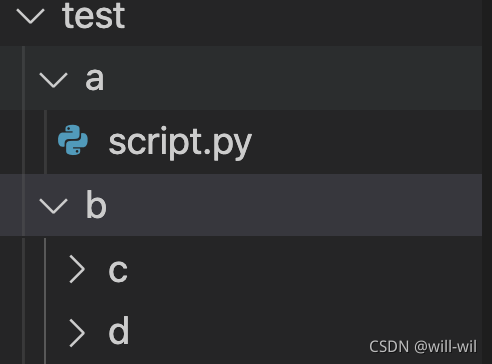
Importing a custom module in the project reports an error ModuleNotFoundError. The project directory structure is as follows. When in a.script.py from bc script.py, it prompts that the b module cannot be found, and the __init__.py file created in the b directory still reports an error.
Solution:
There are several methods of online search:
2. import sys (Working)
sys.path.append(‘The address of the reference module’)
3. Create in the folder that needs to be imported __init.py__ (Not Working)
4. Direct export PYTHONPATH=path in linux (Working)
Summary
1.
The following method can be used, but it is a one-time thing.
import sys
sys.path.append('address of the referenced module')
File directory structure, need to be in the a.script.py filefrom b.c.1.py report error module not found
test
├── a
│ ├── _init_paths.py
│ └── script.py
└── b
├── c
│ └── 1.py
└── d
Suggested forms.
1. Write import sys sys.path.append('address of referenced module') directly at the beginning of the script.py file to add the path.
2. Create the _init_paths.py script in the a directory, and then just import _init_paths in script.py.
#_init_paths.py
import os
import sys
def add_path(path):
"""Add path to sys system path
"""
if path not in sys.path:
sys.path.append(path)
current_dir = os.path.dirname(__file__)
parent_dir = os.path.dirname(current_dir)
add_path(parent_dir)
2.Modify the environment variables directly, you can use export PYTHONPATH=path to add in linux.
Operating system: Ubuntu 18.04
Test time: November 18, 2021
Problem Description:
Recently, the author encountered the following problems when downloading the repository on GitHub by using the GIT clone command, resulting in cloning failure
$ git clone https://github.com/pjreddie/darknet
Clone to 'darknet'...
fatal: unable to access 'https://github.com/pjreddie/darknet/': gnutls_handshake() failed: The TLS connection was non-properly terminated.
Solution:
Modify the HTTPS of the warehouse connection to git to clone
$ git clone https://github.com/pjreddie/darknet
Burn the program into the FPGA chip with USB blaster, and the prompt is “error: can’t access JTAG chain”, and then the test JTAG chain still prompts this problem. After looking for the information on the Internet, I summarized the reasons for the prompt of “can’t access JTAG chain” when downloading. The common reasons are as follows:
(1) The selected FPGA model is inconsistent with the hardware;
(2) The communication between the parallel port and the download line is faulty or the download line is broken;
(3) Poor contact between download cable and JTAG socket;
(4) The JTAG port of the download line and the board is connected reversely;
(5) FPGA burned;
(6) Power supply problems;
(7) There is a problem with the schematic design;
(8) The large pad at the bottom of the FPGA chip is not grounded.
my problem is 4.
I’m ashamed. In fact, try the opposite and find the position of the first JTAG pin (small semicircle).
USB blaster user manual
1. Phenomenon
2. Solution
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 8071;
server_name 101.42.104.247;
location/{
root /home/intelligent_evaluation_of_rock_burst/development_project/dist;
index index.html index.htm;
try_files $uri $uri/ /index.html; //Add this line
}
#Dynamic requests
location /api{
include uwsgi_params;
uwsgi_pass 127.0.0.1:5000;
}
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
Nginx – s reload nginx
Nginx – t test whether nginx is normal
Project scenario:
tip: briefly describe the project background here:
for example, project scenario: example: communicate with mobile app through Bluetooth chip (hc-05), and transmit a batch of sensor data every 5S (not very large)
Problem Description:
The following code will report an error if it can’t be found in the database, and it doesn’t work whether you judge it to be empty or judge the length.
@Override
public String queryUserNameByUserId(String userId) {
String sql = "SELECT username FROM info WHERE userId= :userId";
MapSqlParameterSource source = new MapSqlParameterSource();
source.addValue("userId", userId);
return namedParameterJdbcTemplate.queryForObject(sql, source, String.class);
}
Cause analysis:
Queryforobject(), try to operate when querying data that must exist in the database.
Solution:
1. Try catch is not recommended
2. Change to list and judge to be empty, as follows.
@Override
public List<String> queryUserNameByUserId(String userId) { //Modify
String sql = "SELECT username FROM info WHERE userId= :userId";
MapSqlParameterSource source = new MapSqlParameterSource();
source.addValue("userId", userId);
return namedParameterJdbcTemplate.queryForList(sql, source, String.class); //修改
}
Wireshark is a powerful packet capture analysis tool. When it is first used on win7/10 64 bit system, unexpected situations may occur. The NPF driver isn’t running. This may be because WinPcap driver is not installed or WinPcap option is not selected when WinPcap is installed.
resolvent:
3. None of the above two situations can be solved. First, you need to confirm whether the NPF service has been installed in the system correctly. First, you need to confirm whether the npf.sys file exists in the folder C: windows?System32?Drivers. If the file does not exist, please re install WinPcap. If the file exists, then run CMD (win7/Vista user needs to press start, input CMD search, right-click the icon of cmd.exe in the search program results, and select run as administrator.
3.1 enter the command to query whether the NPF service is installed
C:\Windows\system32> sc qc npf
[SC] QueryServiceConfig SUCCESS
SERVICE_ NAME: npf
TYPE : 1 KERNEL_ DRIVER
START_ TYPE : 2 AUTO_ START
ERROR_ CONTROL : 1 NORMAL
BINARY_ PATH_ NAME : system32\drivers\npf.sys
LOAD_ ORDER_ GROUP :
TAG : 0
DISPLAY_ NAME : NetGroup Packet Filter Driver
DEPENDENCIES :
SERVICE_ START_ Name:
with the above results, the output is normal. If not, re install WinPcap and try again.
3.2 start NPF service manually:
C:\Windows\system32> SC start NPF
if there is no error prompt, Wireshark can be used normally.
3.3 if start in the query result of NPF service_ The value of type is not auto_ If you want to start, you don’t want to run the NPF driver manually every time. You can use the following command to change the NPF service to start automatically.
C:\Windows\system32> sc config npf start= auto
The source text of the post is from the website
and http://blog.sina.com.cn/s/blog_ 718ccdb90102uzqr.html
Recently in the course design, the main process is to collect data from the CSV file, store it in HBase, and then use MapReduce for statistical analysis of the data. During this period, we encountered some problems, which were finally solved through various searches. Record these problems and their solutions here.
1. HBase hmaster auto close problem
Enter zookeeper, delete HBase data (use with caution), and restart HBase
./zkCli.sh
rmr /hbase
stop-hbase.sh
start-hbase.sh
2. Dealing with multi module dependency when packaging with Maven
The project structure is shown in the figure below
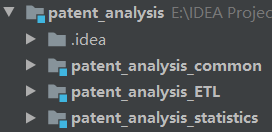
ETL and statistics both refer to the common module. When they are packaged separately, they are prompted that the common dependency cannot be found and the packaging fails.
Solution steps:
1. To do Maven package and Maven install for common, I use idea to operate directly in Maven on the right.
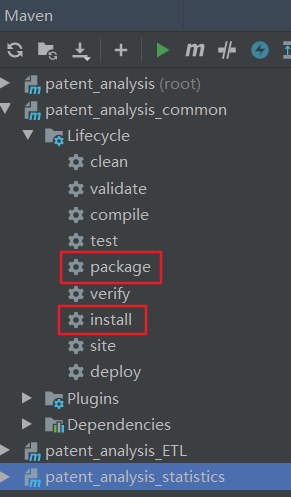
2. Run Maven clean and Maven install commands in the outermost total project (root)
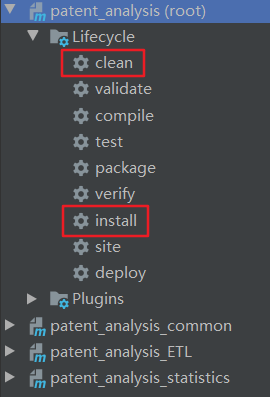
After completing these two steps, the problem can be solved.
3. When the Chinese language is stored in HBase, it becomes a form similar to “ XE5 x8f x91 Xe6 x98 x8e”
The classic Chinese encoding problem can be solved by calling the following method before using.
public static String decodeUTF8Str(String xStr) throws UnsupportedEncodingException {
return URLDecoder.decode(xStr.replaceAll("\\\\x", "%"), "utf-8");
}
4. Error in job submission of MapReduce
Write the code locally, type it into a jar package and run it on the server. The error is as follows:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.mapreduce.Job.getArchiveSharedCacheUploadPolicies(Lorg/apache/hadoop/conf/Configuration;)Ljava/util/Map;
at org.apache.hadoop.mapreduce.v2.util.MRApps.setupDistributedCache(MRApps.java:491)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:92)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:172)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:788)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:240)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at MapReduce.main(MapReduce.java:49)
Solution: add dependencies
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
Among them
Hadoop-mapreduce-client-core.jar supports running on a cluster
Hadoop-mapreduce-client-common.jar supports running locally
After solving the above problems, my code can run smoothly on the server.
Finally, it should be noted that the output path of MapReduce cannot already exist, otherwise an error will be reported.
I hope this article can help you with similar problems.
Ubuntu pyinstaller Error when packaging the executable: … qt.qpa.plugin: Could not find the Qt platform plugin “xcb” in “…
Solution to the problem
Problem
Ubuntu pyinstaller reports an error when packaging the executable: .QFactoryLoader::QFactoryLoader() checking directory path “/home/dyj/CarUI/dist/carmain/platforms” … qt.qpa.plugin: Could not find the Qt platform plugin “xcb” in “” This application failed to start because no Qt platform plugin could be initialized.
Solution
Add the following code to your own main program code.
import os
import PySide2
dirname = os.path.dirname(PySide2.__file__)
plugin_path = os.path.join(dirname, 'plugins', 'platforms')
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = plugin_path
Sorry, that didn’t work.please try again
Today, I just finished installing Ubuntu 20.04. After setting the root password, I found that the root login would report such an error:
sorry, that didn’t work.please try again
In fact, there is no problem with the command line login, which indicates that it is not the password, but the desktop environment.
vi /etc/pam.d/gdm-autologin
#Note "auth requied pam_succeed_if.so user != root quiet success"
vi /etc/pam.d/gdm-password
#Note "auth requied pam_succeed_if.so user != root quiet success"
follow the video operation, delete node_modules directory, webpack
ERROR in ./src/js/index.js
Module build failed: TypeError: fileSystem.statSync is not a function
at module.exports (/Users/mac/source/9-01/node_modules/babel-loader/lib/utils/exists.js:7:25)
at find (/Users/mac/source/9-01/node_modules/babel-loader/lib/resolve-rc.js:13:9)
at Object.module.exports (/Users/mac/source/9-01/node_modules/babel-loader/lib/index.js:113:132)Baidu once, someone said because
webpack version inconsistency results. So reinstall
npm install webpack --save-devThere are many warnings when performing this step
npm notice save webpack is being moved from dependencies to devDependencies
npm WARN [email protected] requires a peer of webpack@2 || 3 but none is installed. You must install peer dependencies yourself.
npm WARN [email protected] requires a peer of jquery@>=1.8.0 but none is installed. You must install peer dependencies yourself.
npm WARN [email protected] No description
npm WARN [email protected] No repository field.The babel-Loader version requires a more advanced WebPack, so execute the following statement to install version 3.0
npm install [email protected] --save-devExecute the WebPack and it will run successfully.