Problem phenomenon
At present, there are three Hadoop clusters with 01, 02 and 03 nodes, among which 01 is the master node and 02 and 03 are the slave nodes. After dynamically adding 04 slave nodes, the number of nodes displayed in Hadoop web interface does not increase. Further observation shows that the contents of slave nodes in the node list are sometimes 02 and 04 nodes, and sometimes 02 and 03 nodes, which is very strange.
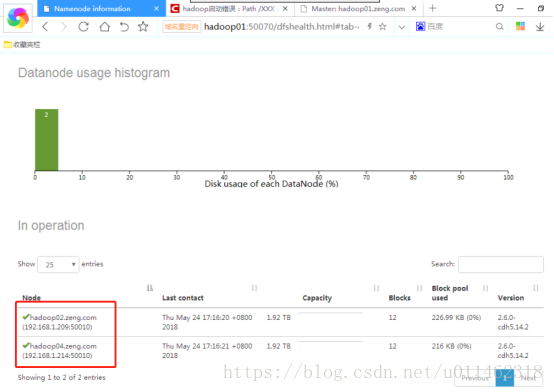
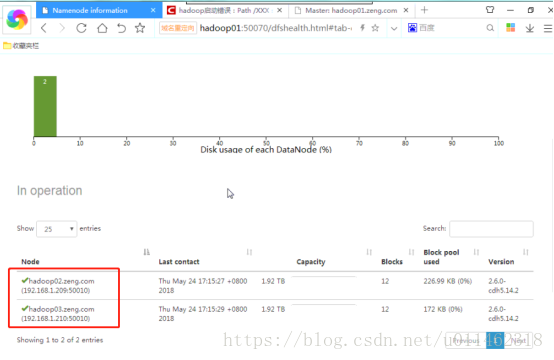
Analyze the reasons
Find the current/version file in the dataDir directory, and the datanodeuuid values in the 03 and 04 servers are exactly the same. It can be inferred that the master node treats 03 and 04 as the same server. The reason is that the 03 server has been started before, and the datanodeuuid has been recorded in the generated version. When the virtual machine is cloned, all the information is the same as the 03 server.
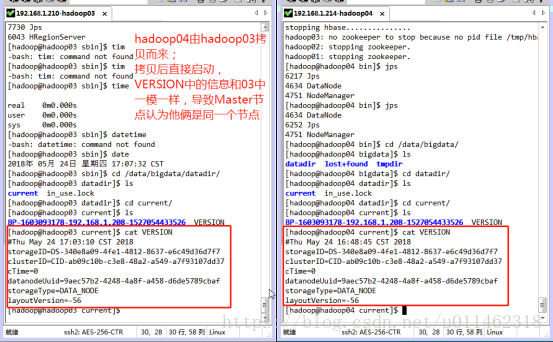
Solution
Considering that if it is not a clone but a direct installation, the dataDir and TMPDIR directories of the 04 server are blank, so stop the datanode and nodemanager services of the 04 server, delete all the files in the dataDir and TMPDIR directories, restart the datanode and nodemanager services, and observe again that the contents of the Hadoop cluster display three datanodes 02, 03 and 04, which are similar to the The expectation is consistent and the problem is solved.
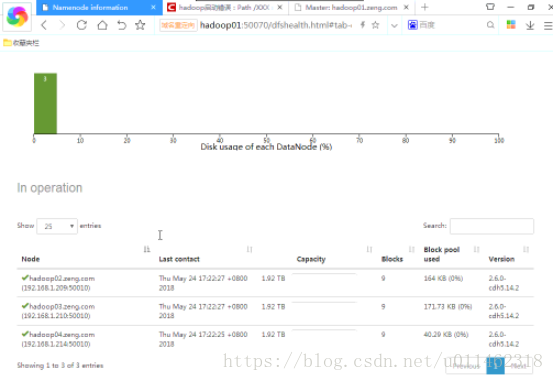
matters needing attention
When adding new nodes by copying or cloning virtual machines, the following operations need to be done:
1. Modify the host name and IP address, restart the new node, and copy the/etc/hosts file to other nodes in the cluster (if using the local DNS server, this step can be omitted, just add the modified node to the domain name resolution record in the DNS server);
2. The new node needs to re run SSH keygen – t RSA to generate the public key and add it to authorized_ And copy it to other nodes in the cluster.
reference material:
1. Hadoop datanode starts normally, but there is no node in live nodes
https://blog.csdn.net/wk51920/article/details/51729460
2. Hadoop 2.7 dynamically adds and deletes nodes
in this paper
https://blog.csdn.net/Mark_ LQ/article/details/53393081
Read More:
- [Solved] Spark SQL Error: File xxx could only be written to 0 of the 1 minReplication nodes.
- “No nodes available to run query” is reported when using Presto to connect to MySQL query“
- When react dynamically prunes components by operating arrays, the state of the remaining components is not preserved. Solution to the problem (method of dynamically setting unique key value)
- Hadoop cluster: about course not obtain block: error reporting
- Solve the problem that the local flow of the nifi node is inconsistent with the cluster flow, resulting in the failure to join the cluster
- Error reported when debugging Hadoop cluster under windows failed to find winutils.exe
- Hadoop datanode using JPS to view the solution that can’t be started
- How to increase the effect of onchange event after adding readonly attribute to input tag and display time of laydate plug-in
- When setting up etcd cluster, an error is reported. Etcd: request cluster ID mismatch error resolution is only applicable to new etcd cluster or no data cluster
- There is a problem with newtonsoft.json.dll after adding plastic SCM
- Solution to the problem of failure to elect leaders when offline service is reported in Nacos
- Linux Mint installs Hadoop environment
- mkdir: Call From hadoop102/192.168.6.102 to hadoop102:8020 failed on connection exception: java.net.
- JQuery is a solution to the disappearance of listening events after adding elements with append
- Elasticsearch in Spring uses Spel to dynamically create Index of Documet class
- In Java, int is converted to string, and zero is added before the number of bits is insufficient
- After node.js is installed, use the instruction node version in vscode to show that it is not an external or internal instruction. The solution is as follows:
- Solution to the problem that listen TCP 0.0.0.0:3306: bind: address already in use port is occupied in Linux centos7
- What to do if you repeatedly format a cluster
- Error in configuring Hadoop 3.1.3: attempting to operate on yarn nodemanager as root error