Could not find method testCompile() for arguments [{group=junit, name=junit, version=4.12}] on object of type org.gradle.api.internal.artifacts.dsl.dependencies.DefaultDependencyHandler.
I’m using gradle 7.1 and I’m importing an older version of the project
The new version changes the testCompile to testImplementation
Author Archives: Robins
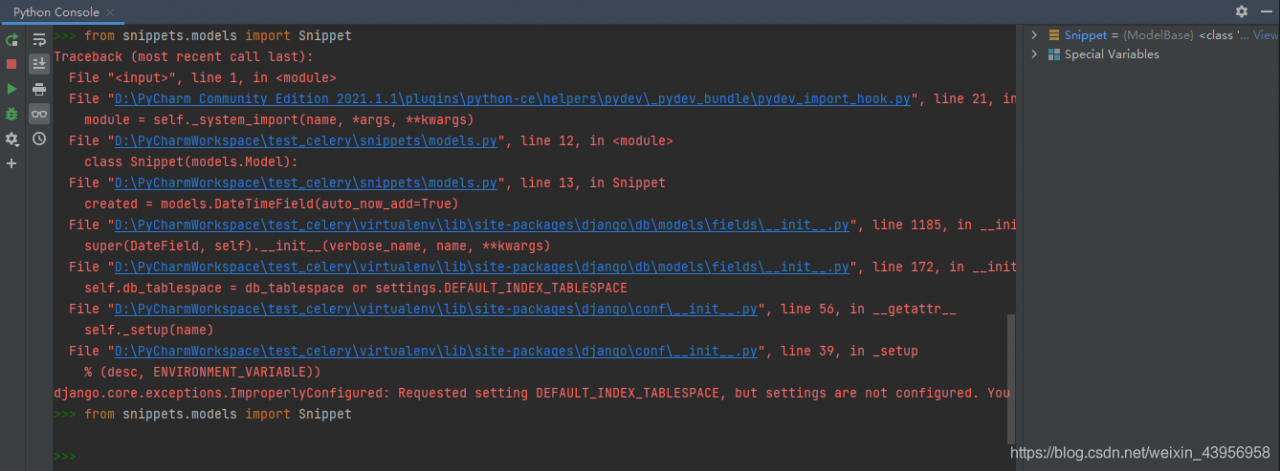
Django PythonConsole error: Requested setting DEFAULT_INDEX_TABLESPACE
Error:
django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.
Solution:
Add to the python file that reports the error:
import os,django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "project_name.settings") # project_name project name
django.setup()
[Solved] Laravel reports an error when executing composer update
Problem 1
– laravel/framework[v5.5.0, …, v5.5.50] require ext-mbstring * -> it is missing from your system. Install or enable PHP’s mbstring extension.
Workaround: Install the required mbstring extension.
Installation command.
sudo apt-get install php-mbstring
Hive 3.1.2 startup error reporting and resolution of guava version conflict
preface
This article belongs to the column “big data abnormal problems summary”, which is the author’s original. Please indicate the source of the quotation, and point out the shortcomings and errors in the comments area. Thank you!
For the table of contents and references of this column, please refer to the summary of big data anomalies
Questions
When installing and deploying hive3.1.2, an error occurred during startup:
[root@node2 apache-hive-3.1.2-bin]# ./bin/hive
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/java/bin:/opt/maven/bin:/opt/bigdata/hadoop-3.2.2/bin:/opt/bigdata/hadoop-3.2.2/sbin:/opt/bigdata/spark-3.2.0/bin:/opt/bigdata/spark-3.2.0/sbin:/opt/java/bin:/opt/maven/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5099)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
solve
From the error log, we can see that there is a problem with the guava package. Either there are fewer packages or there are conflicts. Let’s first check whether the package exists
[root@node2 apache-hive-3.1.2-bin]# find/-name *guava*
find: ‘/proc/9666’: Not having that file or directory
/opt/maven/lib/guava.license
/opt/maven/lib/guava-25.1-android.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/common/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/hdfs/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/kms/tomcat/webapps/kms/WEB-INF/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-2.7.3/share/hadoop/tools/lib/guava-11.0.2.jar
/opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar
/opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
/opt/bigdata/hadoop-3.2.2/share/hadoop/hdfs/lib/guava-27.0-jre.jar
/opt/bigdata/hadoop-3.2.2/share/hadoop/hdfs/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
/opt/bigdata/spark-3.2.0/jars/guava-14.0.1.jar
/opt/bigdata/apache-hive-3.1.2-bin/lib/guava-19.0.jar
/opt/bigdata/apache-hive-3.1.2-bin/lib/jersey-guava-2.25.1.jar
There are guava packages in hive’s lib directory and Hadoop’s common lib directory, but the package versions are inconsistent. We use guava-27.0-jre.jar to override guava-19.0.jar in hive’s lib directory
[root@node2 apache-hive-3.1.2-bin]# cd lib
[root@node2 lib]# ll *guava*
-rwxr-xr-x. 1 hadoop hadoop 2308517 Sep 27 2018 guava-19.0.jar
-rwxr-xr-x. 1 hadoop hadoop 971309 May 21 2019 jersey-guava-2.25.1.jar
[root@node2 lib]# cd /opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/
[root@node2 lib]# ll *guava*
-rwxr-xr-x. 1 hadoop hadoop 2747878 Sep 26 00:18 guava-27.0-jre.jar
-rwxr-xr-x. 1 hadoop hadoop 2199 Sep 26 00:18 listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
[root@node2 lib]# cd /opt/bigdata/apache-hive-3.1.2-bin/lib/
[root@node2 lib]# mv guava-19.0.jar guava-19.0.jar.bak
[root@node2 lib]# cp /opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar /opt/bigdata/apache-hive-3.1.2-bin/lib/
[root@node2 lib]# ll *guava*
-rwxr-xr-x. 1 hadoop hadoop 2308517 Sep 27 2018 guava-19.0.jar.bak
-rwxr-xr-x. 1 root root 2747878 Jun 19 13:23 guava-27.0-jre.jar
-rwxr-xr-x. 1 hadoop hadoop 971309 May 21 2019 jersey-guava-2.25.1.jar
[root@node2 lib]# chmod 755 guava-27.0-jre.jar
[root@node2 lib]# chown hadoop:hadoop guava-27.0-jre.jar
At the same time, we switch to Hadoop users to execute (this can ensure that Hadoop is a super user)
[root@node2 lib]# su - hadoop
Last login: April June 17 22:14:01 CST 2021pts/0 AM
[hadoop@node2 ~]$ cd /opt/bigdata/apache-hive-3.1.2-bin/
[hadoop@node2 apache-hive-3.1.2-bin]$ ./bin/hive
which: no hbase in (/home/hadoop/.local/bin:/home/hadoop/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/java/bin:/opt/maven/bin:/opt/bigdata/hadoop-3.2.2/bin:/opt/bigdata/hadoop-3.2.2/sbin:/opt/bigdata/spark-3.2.0/bin:/opt/bigdata/spark-3.2.0/sbin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 901d74e6-fa5d-45b5-b949-bebdacb582ed
Logging initialized using configuration in jar:file:/opt/bigdata/apache-hive-3.1.2-bin/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
The problem has been solved
[Solved] Hadoop error java.lang.nosuchmethoderror
Record a Hadoop error:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.mapreduce.Job.getArchiveSharedCacheUploadPolicies(Lorg/apache/hadoop/conf/Configuration;)Ljava/util/Map;
at org.apache.hadoop.mapreduce.v2.util.MRApps.setupDistributedCache(MRApps.java:491)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:93)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:172)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:794)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:240)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at hadoop.mapjoin.MapJoinDriver.main(MapJoinDriver.java:59)
At this point, the dependency introduced in POM. XML is
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.3.16.RELEASE</version>
</dependency>
<!--Dependencies used by hbase-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.0</version>
</dependency>
<!--hadoop dependencies-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.18</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--Log information-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
However, after the dependency of HBase is removed, wordcount can run normally. Is it a problem with both versions
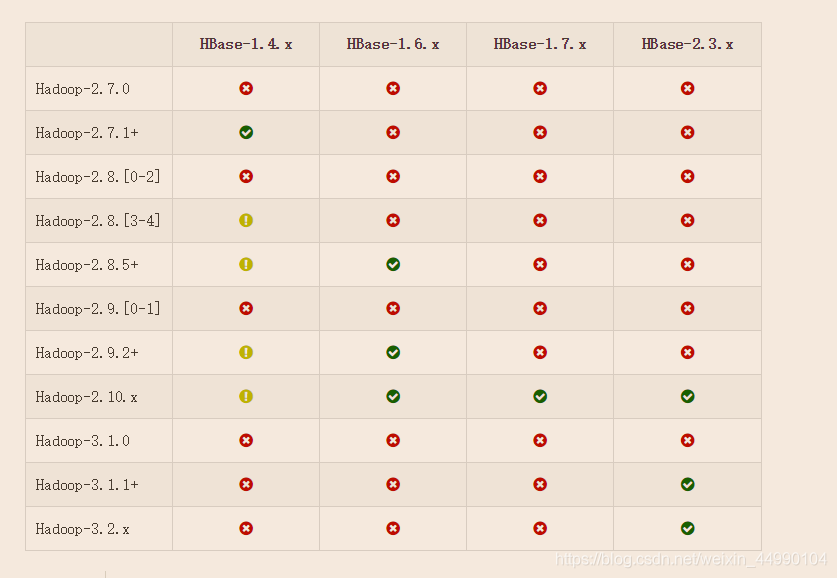
the corresponding relationship of the recommended version on the official website, and the link to view on the official website http://hbase.apache.org/book.html#java
[Solved] Error report of introducing Vue into ecarts GL
ERROR Failed to compile with 3 errors 11:11:19 ├F10: AM┤
This dependency was not found:
echarts/lib/label/labelStyle in ./node_modules/echarts-gl/lib/component/common/LabelsBuilder.js, ./node_modules/echarts-gl/lib/component/grid3D/Grid3DView.js and 1 other
To install it, you can run: npm install –save echarts/lib/label/labelStyle
This error was reported after the introduction was started
then downgraded
npm install [email protected] --save
[Solved] Openwrt Pptpd Start Error: validation filed
It’s probably that the configuration file is directly copied and pasted, resulting in invisible strange strings. If you honestly modify the configuration file without leaving strange spaces, you will not report this error. The configuration file is parsed by UCI. The configuration file of pptpd is in the/etc/config/pptpd file. The content is as follows,
config service 'pptpd'
option enabled '1'
option localip '192.168.0.1'
option remoteip '192.168.0.2-30'
option nat '1'
option internet '1'
#list dns '192.168.1.1'
#list dns '10.10.0.21'
option mppe '1'
config login
option enabled '1'
option username 'user2'
option password 'dfsaf'
option ipaddress '192.168.0.2'/etc/init.d/pptpd restart
/etc/init.d/pptpd start
Both can open pptpd server now
netstat -antp
Check if port 1723 is open, if it is open, it is running.
For sh out of range, see:
https://forum.openwrt.org/t/default-config-file-for-pptpd-lacks-logwtmp-option/4795
######/etc/firewall.user###########
iptables -A forwarding_rule -i ppp+ -j ACCEPT ## luci-app-pptpd
iptables -A forwarding_rule -o ppp+ -j ACCEPT ## luci-app-pptpd
iptables -A output_rule -o ppp+ -j ACCEPT ## luci-app-pptpd
iptables -A input_wan_rule -p tcp --dport 1723 -j ACCEPT ## luci-app-pptpd
iptables -A input_wan_rule -p tcp --dport 47 -j ACCEPT ## luci-app-pptpd
iptables -A input_wan_rule -p gre -j ACCEPT ## luci-app-pptpd
iptables -A input_rule -i ppp+ -j ACCEPT ## luci-app-pptpd
How to Solve HBase error: region is not online
Error information:
2021-06-15 10:55:33.721 ERROR 531 --- [io-8022-exec-33] c.e.dataapi.biz.hbase.HbaseDataProvider : Table Get batch error the connection is exception: Failed after attempts=1, exceptions:
Tue Jun 15 10:55:33 CST 2021, RpcRetryingCaller{globalStartTime=1623725733712, pause=200, retries=1}, org.apache.hadoop.hbase.NotServingRegionException: org.apache.hadoop.hbase.NotServingRegionException: Region rpt_ewt_theme_xxxx_compare_1d_b,348788221_122887872,1623446719723.ebb056cf4a332e5efa355bd2619033c5. is not online on hadoop17,60020,1620193917454
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:2997)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1069)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:2388)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:33648)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2191)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:183)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:163)reason:
When HBase is running, the region will start to split when it reaches the set file size. The process of division is as follows:
1) The old region is offline, which corresponds to is not online in the error log
2) Old region split
3) When the old region is closed, this corresponds to the error in the error log is closing
Solution: turn off automatic splitting and split artificially.
Or set the value of a single region file to uppercase
CDH Namenode Abnormal stop Error: flush failed for required journal (JournalAndStream(mgr=QJM to
The error information is as follows:
2020-12-09 14:07:56,509 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: Error: flush failed for required journal (JournalAndStream(mgr=QJM to [xxx:8485, xxx:8485, xxx:8485], stream=QuorumOutputStream starting at txid 74798133))
2020-12-09 14:07:56,499 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Aborting QuorumOutputStream starting at txid 74798133
at java.lang.Thread.run(Thread.java:748)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogAsync.run(FSEditLogAsync.java:243)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.logSync(FSEditLog.java:711)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream.flush(JournalSet.java:521)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.access$100(JournalSet.java:55)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:385)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream$8.apply(JournalSet.java:525)
at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:107)
at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:113)
at org.apache.hadoop.hdfs.qjournal.client.QuorumOutputStream.flushAndSync(QuorumOutputStream.java:109)
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:142)
at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:286)
at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown:
2020-12-09 14:07:56,496 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: flush failed for required journal (JournalAndStream(mgr=QJM to [xxx:8485, xxx:8485, xxx:8485], stream=QuorumOutputStream starting at txid 74798133))
2020-12-09 14:07:56,494 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Took 7611ms to send a batch of 2 edits (179 bytes) to remote journal xxx:8485
at java.lang.Thread.run(Thread.java:748)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.hadoop.hdfs.qjournal.client.IPCLoggerChannel$7.call(IPCLoggerChannel.java:389)
at org.apache.hadoop.hdfs.qjournal.client.IPCLoggerChannel$7.call(IPCLoggerChannel.java:396)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolTranslatorPB.journal(QJournalProtocolTranslatorPB.java:187)
at com.sun.proxy.$Proxy19.journal(Unknown Source)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.Client.call(Client.java:1355)
at org.apache.hadoop.ipc.Client.call(Client.java:1445)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1499)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
org.apache.hadoop.ipc.RemoteException(java.io.IOException): IPC's epoch 33 is less than the last promised epoch 34
2020-12-09 14:07:56,492 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Remote journal xxx:8485 failed to write txns 74798134-74798135. Will try to write to this JN again after the next log roll.
]
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
, xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
2020-12-09 14:07:55,886 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 7003 ms (timeout=20000 ms) for a response for sendEdits. Exceptions so far: [xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
]
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
, xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
2020-12-09 14:07:54,883 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 6001 ms (timeout=20000 ms) for a response for sendEdits. Exceptions so far: [xxx:8485: IPC's epoch 33 is less than the last promised epoch 34
at java.lang.Thread.run(Thread.java:748)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.hadoop.hdfs.qjournal.client.IPCLoggerChannel$7.call(IPCLoggerChannel.java:389)
at org.apache.hadoop.hdfs.qjournal.client.IPCLoggerChannel$7.call(IPCLoggerChannel.java:396)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolTranslatorPB.journal(QJournalProtocolTranslatorPB.java:187)
at com.sun.proxy.$Proxy19.journal(Unknown Source)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.Client.call(Client.java:1355)
at org.apache.hadoop.ipc.Client.call(Client.java:1445)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1499)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at javax.security.auth.Subject.doAs(Subject.java:422)
at java.security.AccessController.doPrivileged(Native Method)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27401)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.journal(QJournalProtocolServerSideTranslatorPB.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.journal(JournalNodeRpcServer.java:179)
at org.apache.hadoop.hdfs.qjournal.server.Journal.journal(Journal.java:372)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkWriteRequest(Journal.java:484)
at org.apache.hadoop.hdfs.qjournal.server.Journal.checkRequest(Journal.java:458)
org.apache.hadoop.ipc.RemoteException(java.io.IOException): IPC's epoch 33 is less than the last promised epoch 34
2020-12-09 14:07:49,776 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Remote journal xxx:8485 failed to write txns 74798134-74798135. Will try to write to this JN again after the next log roll.
When HA is configured, one of the namenode stops, and the key message “IPC’s epoch is less than the last committed epoch” is probably due to network failure. After reading the log, every time another namenode is started, port 8485 of the three journalnode services will be detected, indicating that it is failed,
indicating that it is most likely a network problem, The troubleshooting is as follows:
ifconfig – a check whether the network card has packet loss
check whether/etc/sysconfig/SELinux = disabled is correct
/etc/init.d/iptables status check whether the firewall is running, because Hadoop is running in the Intranet environment, remember that the firewall was closed when it was deployed before
check the firewalls of three journalnode servers successively, It’s all closed
Online solutions:
1) adjust the write timeout of journal node
for example, dfs.qjournal.write-txns.timeout.ms = 90000
In fact, in the actual production environment, this kind of timeout is also easy to happen, so we need to change the default 20s timeout to a larger value, such as 60 or 90s.
We can add a set of configurations in hdfs-site.xml under Hadoop/etc/Hadoop
dfs.qjournal.write-txns.timeout.ms
60000
CDH cluster searches dfs.qjournal.write-txns.timeout.ms in HDFS configuration interface
2) adjusts the Java parameters of namenode and triggers full GC in advance, so that the time of full GC will be less
3) the default full GC mode of namenode is parallel GC, which is in STW mode and is changed to CMS format. Adjust the startup parameters of namenode:
– XX: + usecompansedoops
– XX: + useparnewgc – XX: + useconcmarksweepgc – XX: + cmsclassunloadingenabled
– XX: + usecmpackage at full collection – XX: cmsfullgcsbeforecompaction = 0
– XX: + cmsparallelremarkenabled – XX: + disableexplicitgc
– XX: + usecmsinitiatingoccupancyonly – XX: cmsinitiatingoccupancyfraction = 75
– XX: cmsfullgcsbeforecompaction SoftRefLRUPolicyMSPerMB=0
[Solved] Android compile error: cannot allocate memory
Problem:
[ 13% 3960/28350] target thumb C++: libRSDriver <= frameworks/rs/driver/rsdScriptGroup.cppninja: fatal: fork: Cannot allocate memory
build/core/ninja.mk:148: recipe for target ‘ninja_wrapper’ failed
make: *** [ninja_wrapper] Error 1
Solution:
Add swap partition
[Solved] Unit test automatically injects error reporting nullpointer
Using @Autowired annotation to generate nullpointer in unit test
terms of settlement
1. Introduce POM
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.2.1.RELEASE</version>
<scope>test</scope>
</dependency>
2. Add notes to the unit test
@SpringBootTest(classes = EduApplication.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class redisTemplate {
@Autowired
RedisTemplate redisTemplate;
@Test
public void testStringAdd(){
BoundValueOperations str = redisTemplate.boundValueOps("str");
// Set the value via redisTemplate
str.set("test1");
str.set("test2");
}
}
[Solved] Spark SQL Error: File xxx could only be written to 0 of the 1 minReplication nodes.
Article Contents
Spark SQL reports an error File xxx could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
There are 3 datanode(s) running and 3 node(s) are excluded in this operation. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
21/06/1917:06:27 ERROR Hive: Failed to move: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hive/warehouse/hdu.db/user_visit_action/user_visit_action.txt could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2205)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2731)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:892)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:568)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:527)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1036)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1000)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:928)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2916)
Exception in thread "main" org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hive/warehouse/hdu.db/user_visit_action/user_visit_action.txt could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2205)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2731)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:892)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:568)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:527)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1036)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1000)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:928)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2916)
;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:109)
at org.apache.spark.sql.hive.HiveExternalCatalog.loadTable(HiveExternalCatalog.scala:874)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.loadTable(ExternalCatalogWithListener.scala:167)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.loadTable(SessionCatalog.scala:491)
at org.apache.spark.sql.execution.command.LoadDataCommand.run(tables.scala:389)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:229)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3616)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3614)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:229)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:100)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
at com.hdu.bigdata.spark.sql.Spark06_SparkSQL_Test$.main(Spark06_SparkSQL_Test.scala:41)
at com.hdu.bigdata.spark.sql.Spark06_SparkSQL_Test.main(Spark06_SparkSQL_Test.scala)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hive/warehouse/hdu.db/user_visit_action/user_visit_action.txt could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2205)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2731)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:892)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:568)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:527)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1036)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1000)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:928)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2916)
at org.apache.hadoop.hive.ql.metadata.Hive.copyFiles(Hive.java:2966)
at org.apache.hadoop.hive.ql.metadata.Hive.copyFiles(Hive.java:3297)
at org.apache.hadoop.hive.ql.metadata.Hive.loadTable(Hive.java:2022)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.hive.client.Shim_v2_1.loadTable(HiveShim.scala:1213)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$loadTable$1(HiveClientImpl.scala:883)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:294)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:227)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:226)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:276)
at org.apache.spark.sql.hive.client.HiveClientImpl.loadTable(HiveClientImpl.scala:878)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$loadTable$1(HiveExternalCatalog.scala:880)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
... 24 more
Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hive/warehouse/hdu.db/user_visit_action/user_visit_action.txt could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2205)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2731)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:892)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:568)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:527)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1036)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1000)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:928)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2916)
at org.apache.hadoop.ipc.Client.call(Client.java:1476)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy29.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy30.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1588)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1373)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:554)
Process finished with exit code 1
Cause of the problem:
The namenode node stores the file directory, that is, the folder and file name. The namenode can be accessed locally through the public network, so the folder can be created. When the upload file needs to write data to the datanode, the namenode and the datanode communicate through the LAN, and the namenode returns the private IP address of the datanode, which cannot be accessed locally
Solution:
The returned IP address cannot return the public IP address, so you can set it to return the host name, and you can access the datanode node through the mapping between the host name and the public address. The problem will be solved
because the priority of code setting is the highest, you can set the code directly:
Add configuration information:
config("dfs.client.use.datanode.hostname", "true")
config("dfs.replication", "2")
Add as follows:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf)
.config("dfs.client.use.datanode.hostname", "true")
.config("dfs.replication", "2")
.getOrCreate()