Error reporting
After installing and entering HBase for the first time, you will encounter this problem:
[root@zhiyong2 /]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.1.10, rUnknown, Mon Nov 23 09:56:35 WIB 2020
Took 0.0036 seconds
hbase(main):001:0> list_namespace
NAMESPACE
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
at org.apache.hadoop.hbase.master.HMaster.checkInitialized(HMaster.java:3003)
at org.apache.hadoop.hbase.master.HMaster.getNamespaces(HMaster.java:3299)
at org.apache.hadoop.hbase.master.MasterRpcServices.listNamespaceDescriptors(MasterRpcServices.java:1237)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
For usage try 'help "list_namespace"'
Took 9.8027 seconds
In this case, I can’t wait all the time. I waited for a while and didn’t initialize well…
Solution
Because it is a new cluster, there is no useful data. You can clear the metadata in the following way to reinitialize. Before clearing metadata, close HBase components in USDP’s Web UI.
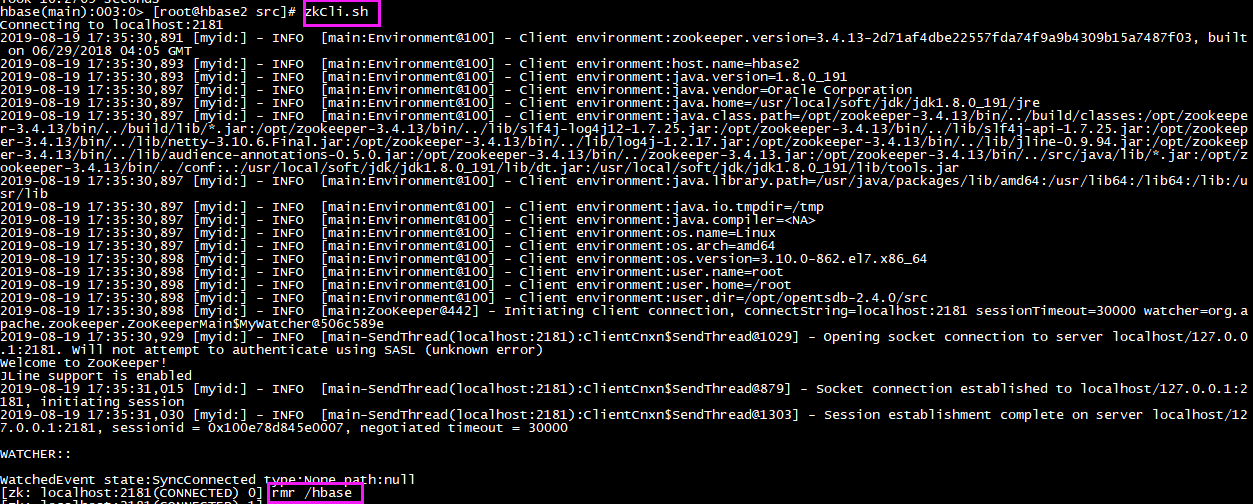
Delete ZK’s metadata
Since part of the metadata of HBase is stored on zookeeper, so you should so this as below:
[root@zhiyong2 /]# zkCli.sh
Connecting to localhost:2181
2022-03-03 00:09:47,689 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT
2022-03-03 00:09:47,693 [myid:] - INFO [main:Environment@100] - Client environment:host.name=zhiyong2
2022-03-03 00:09:47,693 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_202
2022-03-03 00:09:47,695 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2022-03-03 00:09:47,695 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.8.0_202/jre
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/srv/udp/2.0.0.0/zookeeper/bin/../zookeeper-server/target/classes:/srv/udp/2.0.0.0/zookeeper/bin/../build/classes:/srv/udp/2.0.0.0/zookeeper/bin/../zookeeper-server/target/lib/*.jar:/srv/udp/2.0.0.0/zookeeper/bin/../build/lib/*.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/slf4j-log4j12-1.7.25.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/slf4j-api-1.7.25.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/netty-3.10.6.Final.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/log4j-1.2.17.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/jline-0.9.94.jar:/srv/udp/2.0.0.0/zookeeper/bin/../lib/audience-annotations-0.5.0.jar:/srv/udp/2.0.0.0/zookeeper/bin/../zookeeper-3.4.13.jar:/srv/udp/2.0.0.0/zookeeper/bin/../zookeeper-server/src/main/resources/lib/*.jar:/srv/udp/2.0.0.0/zookeeper/bin/../conf:.:/usr/java/jdk1.8.0_202/jre/lib/rt.jar:/usr/java/jdk1.8.0_202/lib/dt.jar:/usr/java/jdk1.8.0_202/lib/tools.jar
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2022-03-03 00:09:47,696 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2022-03-03 00:09:47,697 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.10.0-957.el7.x86_64
2022-03-03 00:09:47,697 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root
2022-03-03 00:09:47,697 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root
2022-03-03 00:09:47,697 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/
2022-03-03 00:09:47,698 [myid:] - INFO [main:ZooKeeper@442] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@41906a77
2022-03-03 00:09:47,721 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1029] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
Welcome to ZooKeeper!
JLine support is enabled
2022-03-03 00:09:47,808 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2022-03-03 00:09:47,817 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1303] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x1000009708f000e, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[cluster, brokers, zookeeper, yarn-leader-election, hadoop-ha, admin, isr_change_notification, dolphinscheduler, log_dir_event_notification, controller_epoch, rmstore, consumers, latest_producer_id_block, config, hbase]
[zk: localhost:2181(CONNECTED) 1] rmr /hbase
[zk: localhost:2181(CONNECTED) 2] [root@zhiyong2 /]# ^C
[root@zhiyong2 /]# ^C
[root@zhiyong2 /]#
HDFS metadata deletion
Since part of HBase data is stored in HDFS, it is also necessary to delete the metadata stored in HDFS by HBase. Since USDP has Ranger and actually has users and permissions, you can’t use root to delete important data of HDFS. You must switch to Hadoop user first.
[root@zhiyong2 /]# hadoop fs -rmr /hbase/data/hbase/meta/*
rmr: DEPRECATED: Please use '-rm -r' instead.
rmr: Failed to move to trash: hdfs://zhiyong-1/hbase/data/hbase/meta/.tabledesc: Permission denied: user=root, access=WRITE, inode="/hbase/data/hbase/meta":hadoop:supergroup:drwxr-xr-x
rmr: Failed to move to trash: hdfs://zhiyong-1/hbase/data/hbase/meta/.tmp: Permission denied: user=root, access=WRITE, inode="/hbase/data/hbase/meta":hadoop:supergroup:drwxr-xr-x
rmr: Failed to move to trash: hdfs://zhiyong-1/hbase/data/hbase/meta/1588230740: Permission denied: user=root, access=WRITE, inode="/hbase/data/hbase/meta":hadoop:supergroup:drwxr-xr-x
[root@zhiyong2 /]# cd /etc/passwd/
-bash: cd: /etc/passwd/: 不是目录
[root@zhiyong2 /]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
libstoragemgmt:x:998:997:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
chrony:x:997:995::/var/lib/chrony:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
hadoop:x:1000:1000::/home/hadoop:/bin/bash
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
saslauth:x:996:76:Saslauthd user:/run/saslauthd:/sbin/nologin
elastic:x:1001:1001::/home/elastic:/bin/bash
hue:x:1002:1002::/home/hue:/bin/bash
[root@zhiyong2 /]# su - hadoop
上一次登录:四 3月 3 00:24:33 CST 2022
[hadoop@zhiyong2 ~]$ hadoop fs -rmr /hbase/data/hbase/meta/*
rmr: DEPRECATED: Please use '-rm -r' instead.
2022-03-03 00:27:31 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/meta/.tabledesc' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/meta/.tabledesc
2022-03-03 00:27:31 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/meta/.tmp' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/meta/.tmp
2022-03-03 00:27:31 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/meta/1588230740' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/meta/1588230740
[hadoop@zhiyong2 ~]$ hadoop fs -rmr /hbase/data/hbase/namespace/*
rmr: DEPRECATED: Please use '-rm -r' instead.
2022-03-03 00:27:34 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/namespace/.tabledesc' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/namespace/.tabledesc
2022-03-03 00:27:34 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/namespace/.tmp' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/namespace/.tmp
2022-03-03 00:27:34 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/data/hbase/namespace/98fb8a0448305b2f9af4f9a72495b6df' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/data/hbase/namespace/98fb8a0448305b2f9af4f9a72495b6df
[hadoop@zhiyong2 ~]$ hadoop fs -rmr /hbase/MasterProcWALs/*
rmr: DEPRECATED: Please use '-rm -r' instead.
2022-03-03 00:27:38 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/MasterProcWALs/pv2-00000000000000000009.log' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/MasterProcWALs/pv2-00000000000000000009.log
2022-03-03 00:27:38 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/MasterProcWALs/pv2-00000000000000000010.log' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/MasterProcWALs/pv2-00000000000000000010.log
2022-03-03 00:27:38 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/MasterProcWALs/pv2-00000000000000000011.log' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/MasterProcWALs/pv2-00000000000000000011.log
2022-03-03 00:27:38 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/MasterProcWALs/pv2-00000000000000000012.log' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/MasterProcWALs/pv2-00000000000000000012.log
2022-03-03 00:27:38 INFO fs.TrashPolicyDefault: Moved: 'hdfs://zhiyong-1/hbase/MasterProcWALs/pv2-00000000000000000013.log' to trash at: hdfs://zhiyong-1/user/hadoop/.Trash/Current/hbase/MasterProcWALs/pv2-00000000000000000013.log
[hadoop@zhiyong2 ~]$ exit
登出
[root@zhiyong2 /]#
Restart HBase
Available after restart:
[hadoop@zhiyong2 ~]$ hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.1.10, rUnknown, Mon Nov 23 09:56:35 WIB 2020
Took 0.0045 seconds
hbase(main):001:0> list_namespace
list_namespace list_namespace_tables
hbase(main):001:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.5645 seconds
hbase(main):002:0> exit
[hadoop@zhiyong2 ~]$ exit
登出
[root@zhiyong2 /]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.1.10, rUnknown, Mon Nov 23 09:56:35 WIB 2020
Took 0.0035 seconds
hbase(main):001:0> list_namespace
list_namespace list_namespace_tables
hbase(main):001:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.6270 seconds
hbase(main):002:0> exit
[root@zhiyong2 /]#
At this time, both the root and the root of the HDFS can see whether the root of the HDFS has the highest permission on the HDFS component or not.