CUDA driver version is insufficient for CUDA runtime version
Question:
An error is reported when docker runs ONEFLOW code of insightface
Failed to get cuda runtime version: CUDA driver version is insufficient for CUDA runtime version
reason:
1. View CUDA runtime version
cat /usr/local/cuda/version.txt
The CUDA version in my docker is 10.0.130
CUDA Version 10.0.130
2. The CUDA version has requirements for the graphics card driver version, see the following link.
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
| CUDA Toolkit |
Linux x86 64 Driver Version |
Windows x86 and 64 Driver Version |
| CUDA 11.0.3 Update 1 |
| CUDA 11.0.2 GA |
>= 450.51.05 |
>= 451.48 |
| CUDA 11.0.1 RC |
>= 450.36.06 |
>= 451.22 |
| CUDA 10.2.89 |
>= 440.33 |
>= 441.22 |
| CUDA 10.1 (10.1.105 general release, and updates) |
>= 418.39 |
>= 418.96 |
| CUDA 10.0.130 |
>= 410.48 |
>= 411.31 |
| CUDA 9.2 (9.2.148 Update 1) |
>= 396.37 |
>= 398.26 |
| CUDA 9.2 (9.2.88) |
>= 396.26 |
>= 397.44 |
cat /proc/driver/nvidia/version took a look at the server’s graphics card driver is 418.67, CUDA 10.1 should be installed, and I installed 10.0.130 cuda.
NVRM version: NVIDIA UNIX x86_64 Kernel Module 418.67 Sat Apr 6 03:07:24 CDT 2019
GCC version: gcc version 7.3.0 (Ubuntu 7.3.0-27ubuntu1~18.04)
solve:
Installing CUDA 10.1
(1) First in https://developer.nvidia.com/cuda-toolkit-archive According to the machine environment, download the corresponding cuda10.1 installation file. For the installer type, I choose runfile (local). The installation steps will be simpler.
wget https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.runsudo sh
(2) Installation
sh cuda_10.1.243_418.87.00_linux.run
The same error occurred, unresolved
it will be updated when a solution is found later.

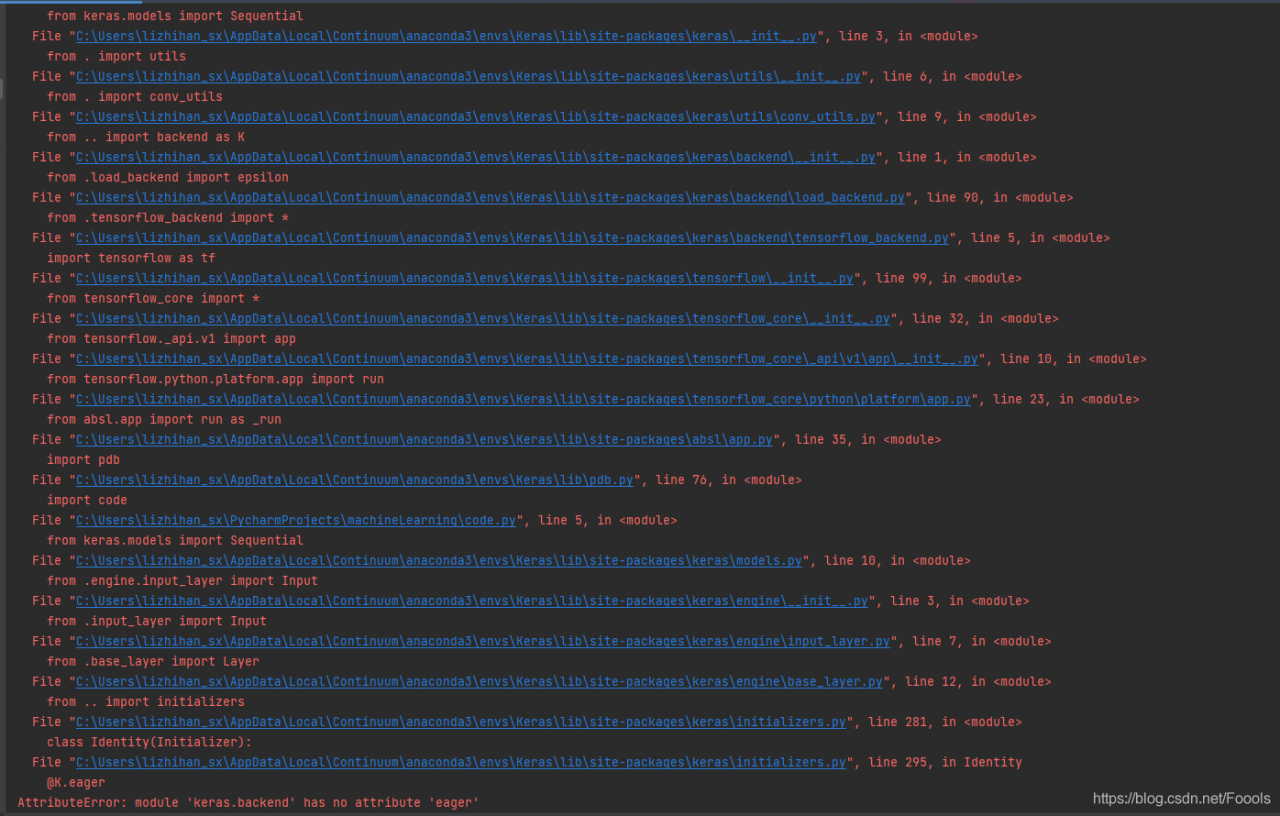
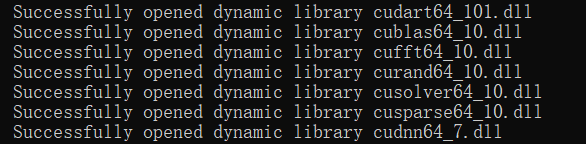
 . According to the above figure, I find that my computer’s CUDA version is 10.0, so I will report an error at runtime. At this time, there are two solutions.
. According to the above figure, I find that my computer’s CUDA version is 10.0, so I will report an error at runtime. At this time, there are two solutions.