preface
Today, a project using pytorch on the viewing server suddenly made an error after upgrading. The whole content of the error report is limited by the title. I’ll send it below.
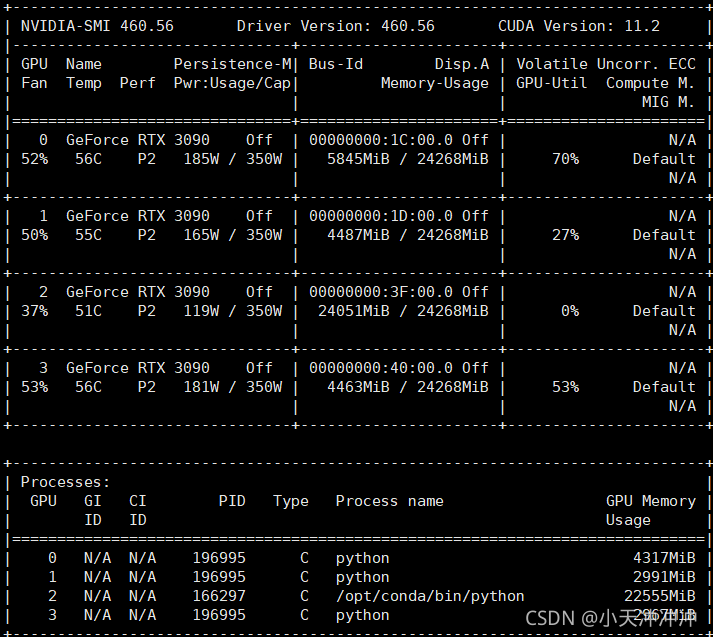
builtins. RuntimeError: CUDA unknown error – this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_ VISIBLE_ DEVICES after program start. Setting the available devices to be zero.
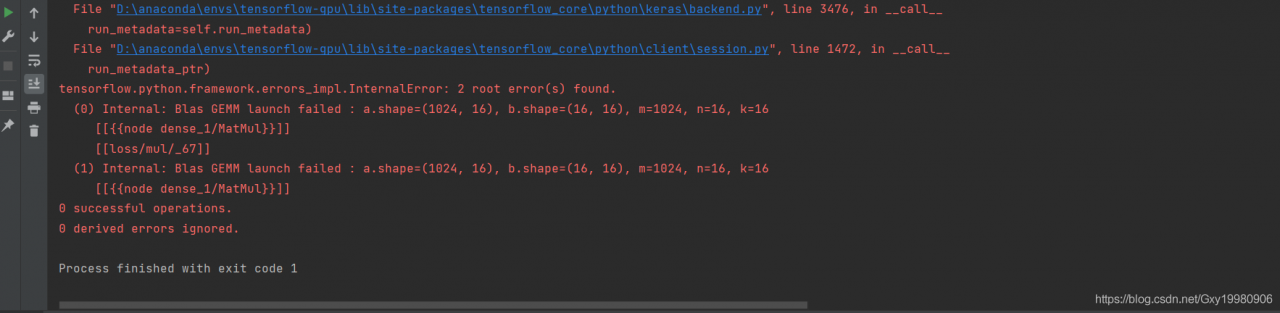
Screenshot of error reporting

Later, I consulted some materials, and the following are some solutions.
Solution:
Method 1: add environment variables
Since I started the project as a docker container, I installed VIM after entering the container, and then in ~/Bashrc finally added something.
export CUDA_ VISIBLE_ DEVICES=0
Since the selected graphics card number is 0 when building the container, the number I configured above is 0.
Check $CUDA after restarting the container_ VISIBLE_ The devices output is normal, but the problem is not solved, and the error is still reported.
Method 2: add environment variables to the code
Add the following code at the beginning of the initialization CUDA area.
import os
os.environ['CUDA_VISIBLE_DEVICES'] =‘0’It still hasn’t solved the problem.
Method 3: restart the server
Referring to some articles, I mentioned that if the system upgrades the graphics card driver without restarting, it will also lead to the same error.
So I restarted the server and solved the problem.