The specific error reports are as follows:
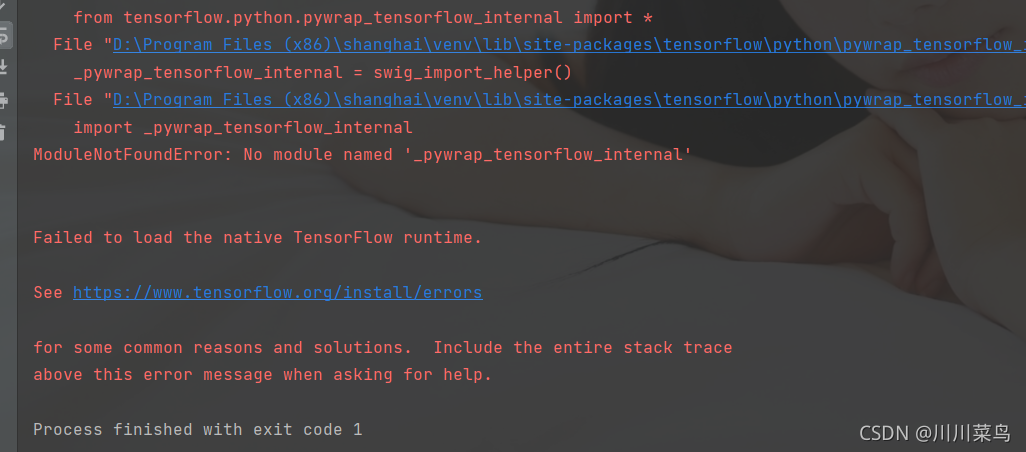
Solution:
write in the lower version first:
pip uninstall tensorflow
Install the latest version:
pip install --upgrade tensorflow
After execution.
The specific error reports are as follows:
Solution:
write in the lower version first:
pip uninstall tensorflow
Install the latest version:
pip install --upgrade tensorflow
After execution.
Error Messages:
FailedPreconditionError (see above for traceback): GetNext() failed because the iterator has not been initialized. Ensure that you have run the initializer operation for this iterator before getting the next element. [[Node: IteratorGetNext = IteratorGetNextoutput_shapes=[, ], output_types=[DT_UINT8, DT_UINT8], _device=”/job:localhost/replica:0/task:0/device:CPU:0″]]
Solution:
Iterator is not initialized
Add before the error code: sess.run(iterator.initializer)
When running the image stylization code with tensorflow version 2.4.0, the following error occurred:
tensorflow.python.framework.errors_impl.InternalError: Blas xGEMM launch failed : a.shape=[1,480000,64], b.shape=[1,480000,64], m=64, n=64, k=480000 [Op:Einsum]
The following two solutions are found by consulting the data:
1. Add the following code to the program:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '/gpu:0'
The program can run normally, but the CPU is used, and the running speed of the program is much slower
2. Modify the cudnn version, but it is generally not recommended. It is too troublesome.
Hint: if you want to see a list of allocated tenants when oom happens, add Report_tensor_allocations_upon_oom to RunOptions for current allocation info.
Problem description
The problems encountered in today’s 50% off cross-validation and grid search are that the amount of data was too large or bitch_ It also occurs when the size is too large, as shown in the figure:
use the command: Watch – N 0.1 NVIDIA SMI in Linux to view the GPU usage
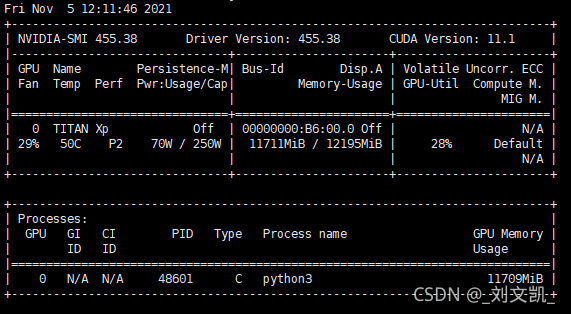
reason
Due to the lack of video memory, but it is not the real lack of video memory, but because TensorFlow has eaten up the video memory, but there is no actual effective utilization. Therefore, the required video memory can be allocated to TensorFlow. (keras based on TensorFlow is also applicable)
Solution:
1. Set small pitch_Size, although it can be used, the indicator does not cure the root cause
2. Manually set the GPU. In train.py:
import tensorflow as tf
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" Specify which GPU to use
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # Allocate video memory on demand
config.gpu_options.per_process_gpu_memory_fraction = 0.4 # Maximum memory usage 40%
session = tf.Session(config=config)) # Create tensorflow session
...
import tensorflow as tf
from keras.models import Sequential
import os
from keras.backend.tensorflow_backend import set_session ## Different from tf.keras
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # Allocate video memory on demand
set_session(tf.Session(config=config)) # Pass the settings to keras
model = Sequential()
...
import tensorflow as tf
from tensorflow.keras.models import Sequential
import os
from tensorflow_core.python.keras.backend import set_session # Different from tf.keras
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # Allocate video memory on demand
config.gpu_options.per_process_gpu_memory_fraction = 0.4 # use 40% of the maximum video memory
set_session(tf.Session(config=config)) # Pass the settings to tf.keras
model = Sequential()
...
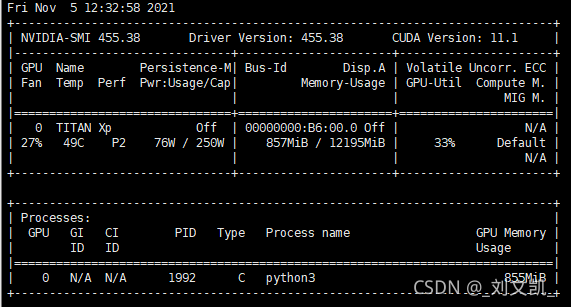
Supplement:
tf.keras can use data reading multithreading acceleration:
model.fit(x_train,y_train,use_multiprocessing=True, workers=4) # Enable multithreading, using 4 CPUs
Empty session:
from tensorflow import keras
keras.backend.clear_session()
After emptying, you can continue to create a new session
Vs 2019 is installed, Microsoft Visual C + + 2015 is available, and GPU is not supported, so CUDA installation is skipped, and pip install tensorflow = = 2.1.0 is directly used. The result shows importerror: DLL load failed.
Solution: PIP uninstall tensorflow uninstall tensorflow
pip install tensorflow = = 2.0.0
Solution:
Add:
tf.compat.v1.disable_eager_execution()
When running the more complex deep learning model of tessorflow, it is easy to get stuck in the interface
if it is a single graphics card (there is f at the end of the CPU model), you can install OpenGL and restart it before running the code
if course not create cudnn handle: cudnn appears_STATUS_INTERNAL_Error is reported, which is caused by insufficient video memory. Add
#Used to limit the use of video memory
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
###############
The problem can be solved
>>> import tensorflow as tf
>>> tf.__version__
'2.6.0'Error code snippet:
model.compile(optimizer=tf.train.AdampOptimizer(0.001),
loss='mse',
metrics=['accuracy'])Replace with:
from tensorflow.keras.optimizers import Adam
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse', metrics=['accuracy'])It can also be changed as follows:
model.compile(optimizer='adam',
loss='mse',
metrics=['accuracy'])Both are operational.

tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above. [Op:Conv2D]
2021-09-24 15:31:45.989272: W tensorflow/core/kernels/data/generator_dataset_op.cc:103] Error occurred when finalizing GeneratorDataset iterator: Failed precondition: Python interpreter state is not initialized. The process may be terminated.
Googled the blog and said that the batchsize was set too large, resulting in insufficient memory. So I changed the batchsize from 16 to 4, and then to 1, and I still got this error.
I don’t think the model I’m running is very big, so why is there this problem?
Solution!
It is not set properly when calling the GPU
Just add these two lines of code at the top of the code
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True)) sess = tf.compat.v1.Session(config=config)
This problem is because you are using load_ Single quotation marks are used in model, and double quotation marks are always used in Python
keras_model = tf.keras_models.load_model("./test.h5")Double quotes are also used when writing
open("./test1.tflite","wb").write(tflite_model)Traceback (most recent call last):
File "D:/master/Multi-level-DCNet-master/3leveldcnet.py", line 342, in <module>
routings=args.routings)
File "D:/master/Multi-level-DCNet-master/3leveldcnet.py", line 60, in MultiLevelDCNet
conv, nb_filter = densenet.DenseBlock(x, growth_rate=32, nb_layers=8, nb_filter=32)
File "D:\master\Multi-level-DCNet-master\densenet.py", line 64, in DenseBlock
cb = __conv_block(x, growth_rate, bottleneck, dropout_rate, weight_decay)
File "D:\master\Multi-level-DCNet-master\densenet.py", line 27, in __conv_block
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(ip)
File "D:\Anaconda\envs\tensorflow\lib\site-packages\keras\engine\topology.py", line 575, in __call__
self.build(input_shapes[0])
File "D:\Anaconda\envs\tensorflow\lib\site-packages\keras\layers\normalization.py", line 103, in build
constraint=self.gamma_constraint)
File "D:\Anaconda\envs\tensorflow\lib\site-packages\keras\legacy\interfaces.py", line 87, in wrapper
return func(*args, **kwargs)
File "D:\Anaconda\envs\tensorflow\lib\site-packages\keras\engine\topology.py", line 399, in add_weight
constraint=constraint)
File "D:\Anaconda\envs\tensorflow\lib\site-packages\keras\backend\tensorflow_backend.py", line 323, in variable
v.constraint = constraint
AttributeError: can't set attributeModify parts of the code:
v = tf.Variable(value, dtype=_convert_string_dtype(dtype), name=name)
if isinstance(value, np.ndarray):
v._keras_shape = value.shape
elif hasattr(value, 'get_shape'):
v._keras_shape = int_shape(value)
v._uses_learning_phase = False
# TODO: move to `tf.get_variable` when supported in public release.
v.constraint = constraint #Modify to v._constraint = constraint
return vScenario:
rstudio reported error R: Python module tensorflow.keras was not found.
at first, I suspected that I could not accurately locate the keras package of R, because I was using Anaconda to do other things, but later I saw other error reports and felt that they were not so complex… Later, I found that they were just simple and not installed properly… In short, the solution is as follows
Solution:
terminal input:
install.packages(tensorflow)
install_tensorflow()
library(tensorflow)
#Keras The R interface uses the TensorFlow backend engine.
# To install the core Keras library and TensorFlow backend, use the install_keras() function
install_keras()
library(keras)
# Run them all and then tune the package, if you have already done so, restart RStudio
-------------------------------------------
#Other solutions to this problem are as follows:
library(tensorflow)
library(keras)
use_condaenv("r-tensorflow")