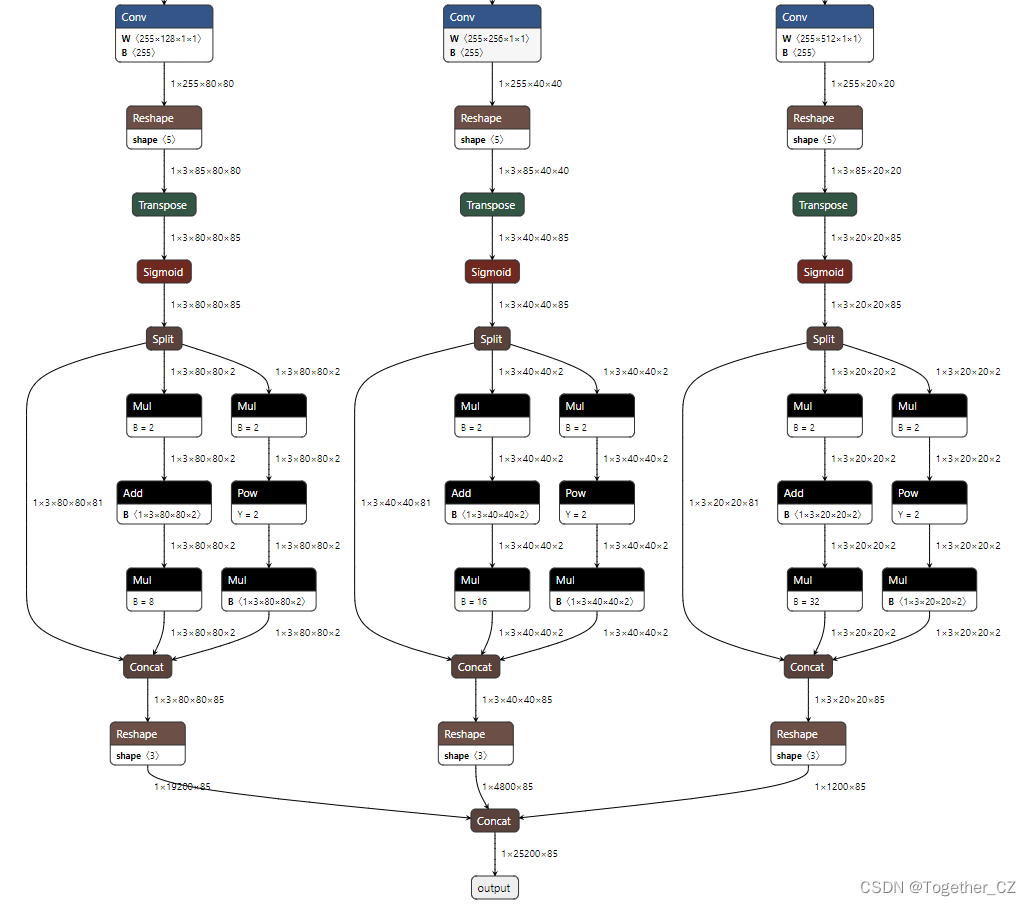
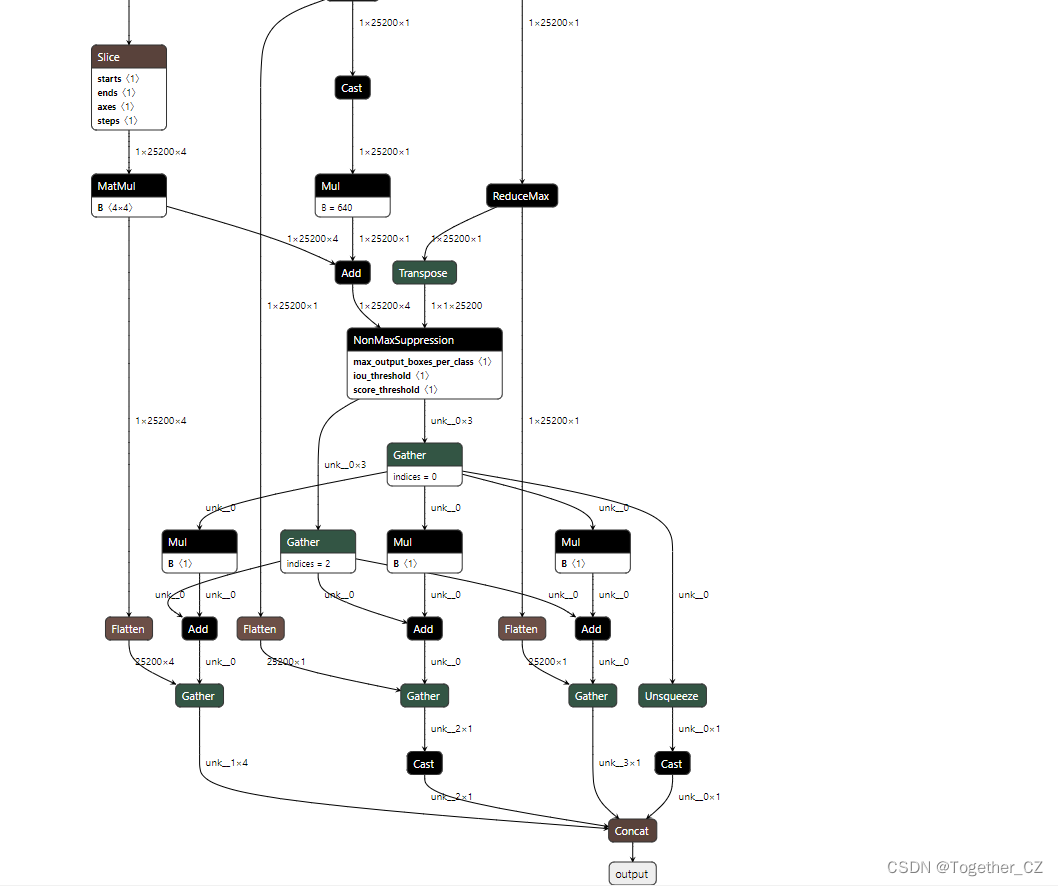
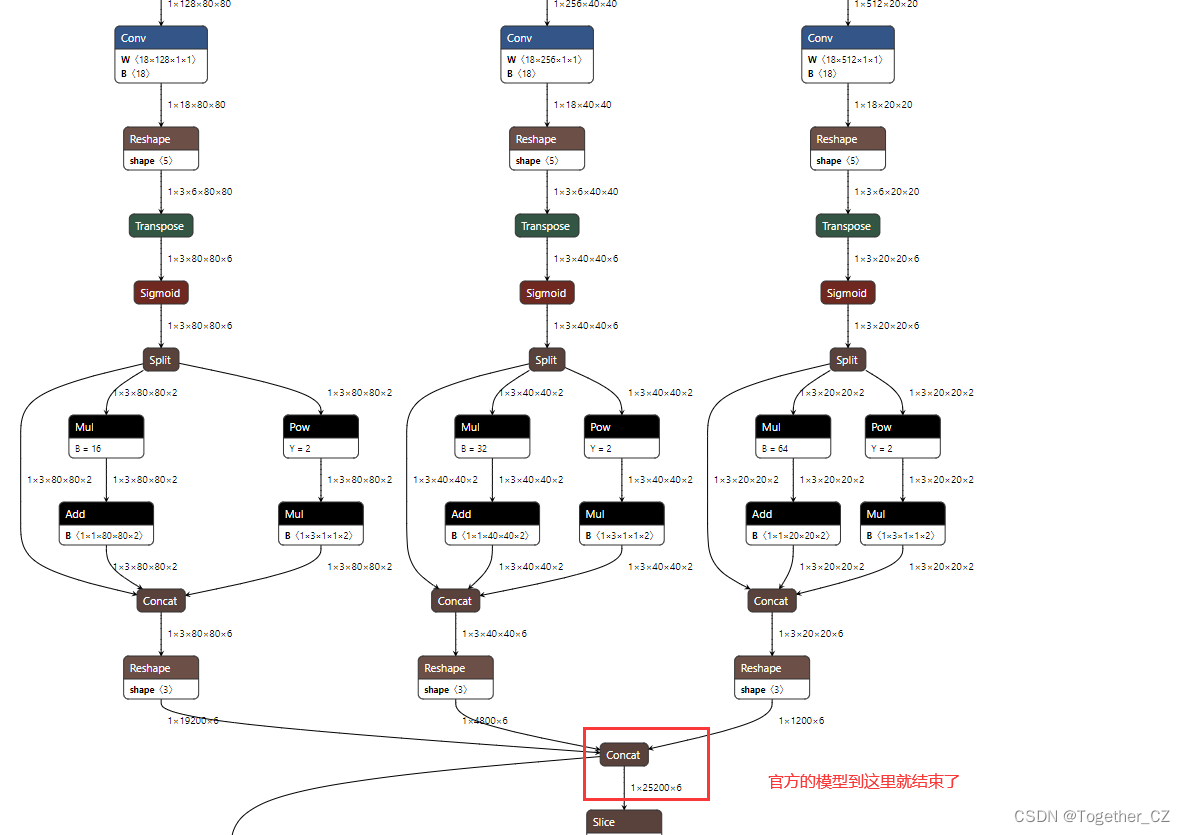
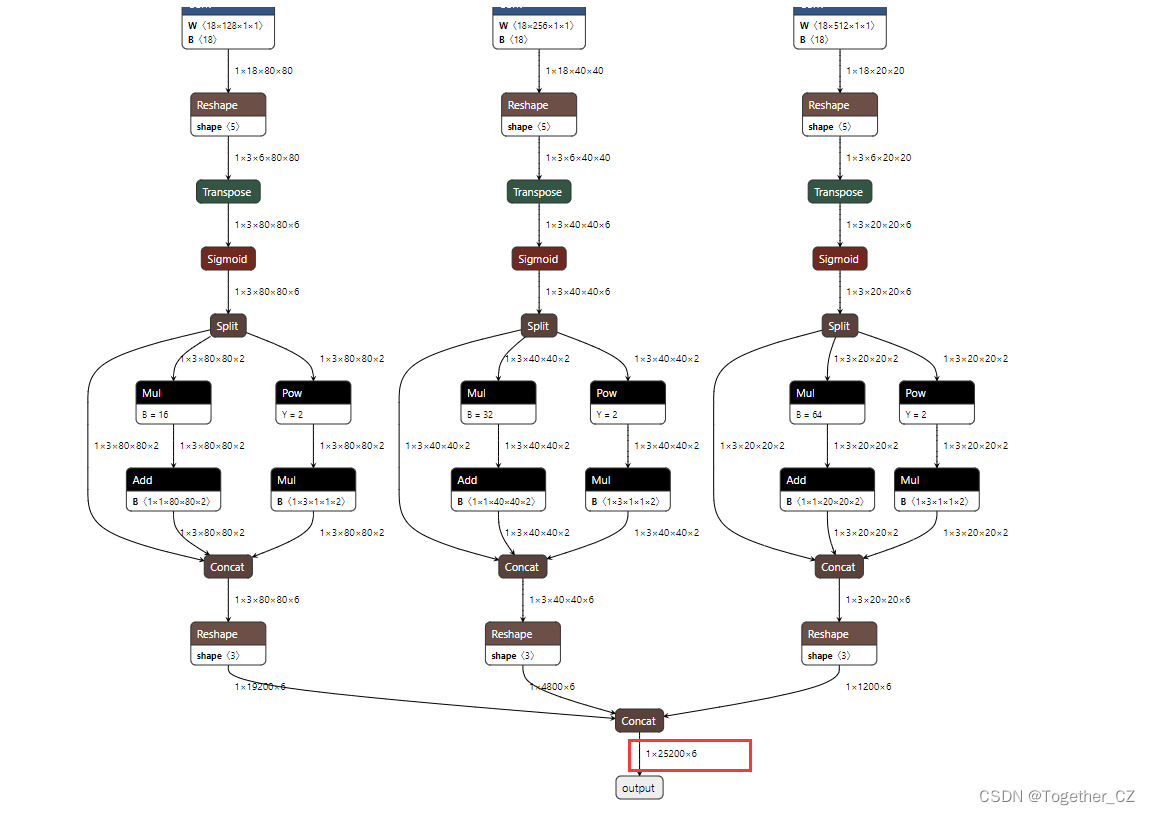
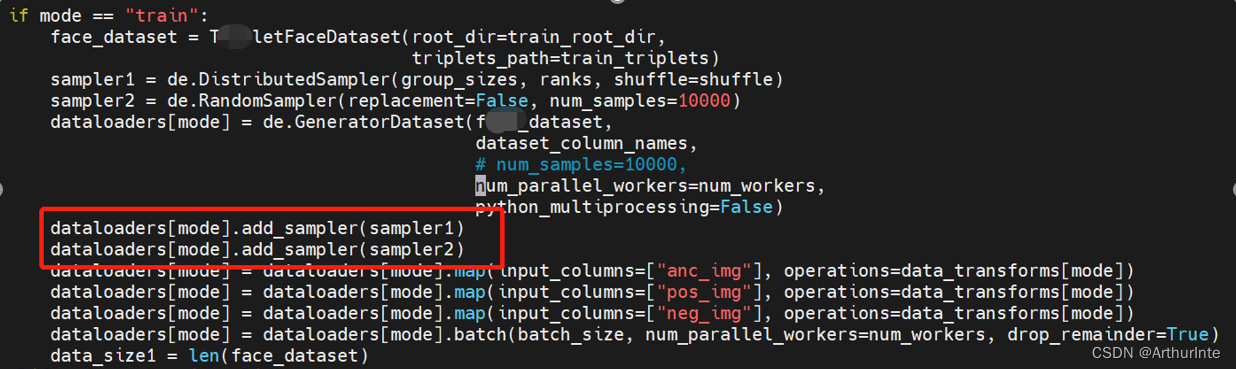
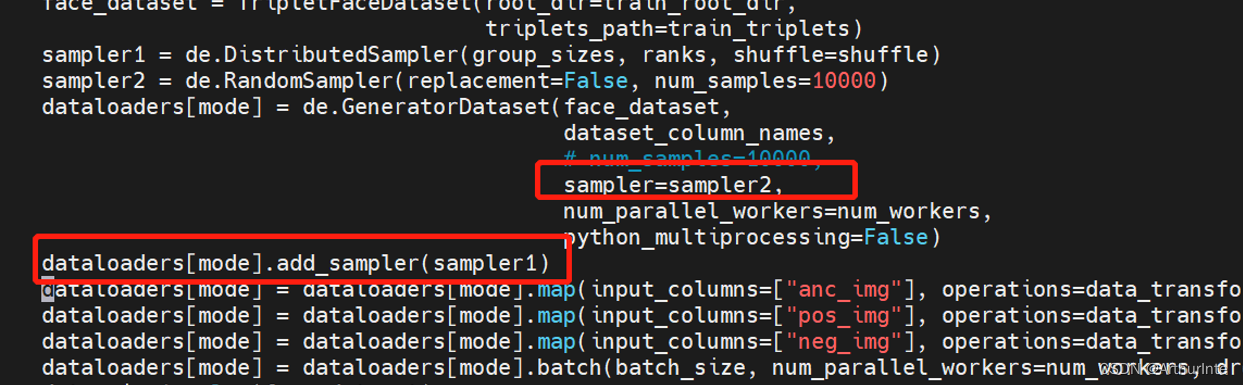
If you need to view the specific parameters of the network, use the use summary
from torchsummary import summary
summary(model, (3, 448, 448))
Show results
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 9,408
BatchNorm2d-2 [-1, 64, 224, 224] 128
ReLU-3 [-1, 64, 224, 224] 0
MaxPool2d-4 [-1, 64, 112, 112] 0
Conv2d-5 [-1, 64, 112, 112] 4,096
BatchNorm2d-6 [-1, 64, 112, 112] 128
ReLU-7 [-1, 64, 112, 112] 0
Conv2d-8 [-1, 64, 112, 112] 36,864
BatchNorm2d-9 [-1, 64, 112, 112] 128
ReLU-10 [-1, 64, 112, 112] 0
Conv2d-11 [-1, 256, 112, 112] 16,384
BatchNorm2d-12 [-1, 256, 112, 112] 512
Conv2d-13 [-1, 256, 112, 112] 16,384
BatchNorm2d-14 [-1, 256, 112, 112] 512
ReLU-15 [-1, 256, 112, 112] 0
Bottleneck-16 [-1, 256, 112, 112] 0
Conv2d-17 [-1, 64, 112, 112] 16,384
BatchNorm2d-18 [-1, 64, 112, 112] 128
ReLU-19 [-1, 64, 112, 112] 0
Conv2d-20 [-1, 64, 112, 112] 36,864
BatchNorm2d-21 [-1, 64, 112, 112] 128
ReLU-22 [-1, 64, 112, 112] 0
Conv2d-23 [-1, 256, 112, 112] 16,384
BatchNorm2d-24 [-1, 256, 112, 112] 512
ReLU-25 [-1, 256, 112, 112] 0
Bottleneck-26 [-1, 256, 112, 112] 0
Conv2d-27 [-1, 64, 112, 112] 16,384
BatchNorm2d-28 [-1, 64, 112, 112] 128
ReLU-29 [-1, 64, 112, 112] 0
Conv2d-30 [-1, 64, 112, 112] 36,864
BatchNorm2d-31 [-1, 64, 112, 112] 128
ReLU-32 [-1, 64, 112, 112] 0
Conv2d-33 [-1, 256, 112, 112] 16,384
BatchNorm2d-34 [-1, 256, 112, 112] 512
ReLU-35 [-1, 256, 112, 112] 0
Bottleneck-36 [-1, 256, 112, 112] 0
Conv2d-37 [-1, 128, 112, 112] 32,768
BatchNorm2d-38 [-1, 128, 112, 112] 256
ReLU-39 [-1, 128, 112, 112] 0
Conv2d-40 [-1, 128, 56, 56] 147,456
BatchNorm2d-41 [-1, 128, 56, 56] 256
ReLU-42 [-1, 128, 56, 56] 0
Conv2d-43 [-1, 512, 56, 56] 65,536
BatchNorm2d-44 [-1, 512, 56, 56] 1,024
Conv2d-45 [-1, 512, 56, 56] 131,072
BatchNorm2d-46 [-1, 512, 56, 56] 1,024
ReLU-47 [-1, 512, 56, 56] 0
Bottleneck-48 [-1, 512, 56, 56] 0
Conv2d-49 [-1, 128, 56, 56] 65,536
BatchNorm2d-50 [-1, 128, 56, 56] 256
ReLU-51 [-1, 128, 56, 56] 0
Conv2d-52 [-1, 128, 56, 56] 147,456
BatchNorm2d-53 [-1, 128, 56, 56] 256
ReLU-54 [-1, 128, 56, 56] 0
Conv2d-55 [-1, 512, 56, 56] 65,536
BatchNorm2d-56 [-1, 512, 56, 56] 1,024
ReLU-57 [-1, 512, 56, 56] 0
Bottleneck-58 [-1, 512, 56, 56] 0
Conv2d-59 [-1, 128, 56, 56] 65,536
BatchNorm2d-60 [-1, 128, 56, 56] 256
ReLU-61 [-1, 128, 56, 56] 0
Conv2d-62 [-1, 128, 56, 56] 147,456
BatchNorm2d-63 [-1, 128, 56, 56] 256
ReLU-64 [-1, 128, 56, 56] 0
Conv2d-65 [-1, 512, 56, 56] 65,536
BatchNorm2d-66 [-1, 512, 56, 56] 1,024
ReLU-67 [-1, 512, 56, 56] 0
Bottleneck-68 [-1, 512, 56, 56] 0
Conv2d-69 [-1, 128, 56, 56] 65,536
BatchNorm2d-70 [-1, 128, 56, 56] 256
ReLU-71 [-1, 128, 56, 56] 0
Conv2d-72 [-1, 128, 56, 56] 147,456
BatchNorm2d-73 [-1, 128, 56, 56] 256
ReLU-74 [-1, 128, 56, 56] 0
Conv2d-75 [-1, 512, 56, 56] 65,536
BatchNorm2d-76 [-1, 512, 56, 56] 1,024
ReLU-77 [-1, 512, 56, 56] 0
Bottleneck-78 [-1, 512, 56, 56] 0
Conv2d-79 [-1, 256, 56, 56] 131,072
BatchNorm2d-80 [-1, 256, 56, 56] 512
ReLU-81 [-1, 256, 56, 56] 0
Conv2d-82 [-1, 256, 28, 28] 589,824
BatchNorm2d-83 [-1, 256, 28, 28] 512
ReLU-84 [-1, 256, 28, 28] 0
Conv2d-85 [-1, 1024, 28, 28] 262,144
BatchNorm2d-86 [-1, 1024, 28, 28] 2,048
Conv2d-87 [-1, 1024, 28, 28] 524,288
BatchNorm2d-88 [-1, 1024, 28, 28] 2,048
ReLU-89 [-1, 1024, 28, 28] 0
Bottleneck-90 [-1, 1024, 28, 28] 0
Conv2d-91 [-1, 256, 28, 28] 262,144
BatchNorm2d-92 [-1, 256, 28, 28] 512
ReLU-93 [-1, 256, 28, 28] 0
Conv2d-94 [-1, 256, 28, 28] 589,824
BatchNorm2d-95 [-1, 256, 28, 28] 512
ReLU-96 [-1, 256, 28, 28] 0
Conv2d-97 [-1, 1024, 28, 28] 262,144
BatchNorm2d-98 [-1, 1024, 28, 28] 2,048
ReLU-99 [-1, 1024, 28, 28] 0
Bottleneck-100 [-1, 1024, 28, 28] 0
Conv2d-101 [-1, 256, 28, 28] 262,144
BatchNorm2d-102 [-1, 256, 28, 28] 512
ReLU-103 [-1, 256, 28, 28] 0
Conv2d-104 [-1, 256, 28, 28] 589,824
BatchNorm2d-105 [-1, 256, 28, 28] 512
ReLU-106 [-1, 256, 28, 28] 0
Conv2d-107 [-1, 1024, 28, 28] 262,144
BatchNorm2d-108 [-1, 1024, 28, 28] 2,048
ReLU-109 [-1, 1024, 28, 28] 0
Bottleneck-110 [-1, 1024, 28, 28] 0
Conv2d-111 [-1, 256, 28, 28] 262,144
BatchNorm2d-112 [-1, 256, 28, 28] 512
ReLU-113 [-1, 256, 28, 28] 0
Conv2d-114 [-1, 256, 28, 28] 589,824
BatchNorm2d-115 [-1, 256, 28, 28] 512
ReLU-116 [-1, 256, 28, 28] 0
Conv2d-117 [-1, 1024, 28, 28] 262,144
BatchNorm2d-118 [-1, 1024, 28, 28] 2,048
ReLU-119 [-1, 1024, 28, 28] 0
Bottleneck-120 [-1, 1024, 28, 28] 0
Conv2d-121 [-1, 256, 28, 28] 262,144
BatchNorm2d-122 [-1, 256, 28, 28] 512
ReLU-123 [-1, 256, 28, 28] 0
Conv2d-124 [-1, 256, 28, 28] 589,824
BatchNorm2d-125 [-1, 256, 28, 28] 512
ReLU-126 [-1, 256, 28, 28] 0
Conv2d-127 [-1, 1024, 28, 28] 262,144
BatchNorm2d-128 [-1, 1024, 28, 28] 2,048
ReLU-129 [-1, 1024, 28, 28] 0
Bottleneck-130 [-1, 1024, 28, 28] 0
Conv2d-131 [-1, 256, 28, 28] 262,144
BatchNorm2d-132 [-1, 256, 28, 28] 512
ReLU-133 [-1, 256, 28, 28] 0
Conv2d-134 [-1, 256, 28, 28] 589,824
BatchNorm2d-135 [-1, 256, 28, 28] 512
ReLU-136 [-1, 256, 28, 28] 0
Conv2d-137 [-1, 1024, 28, 28] 262,144
BatchNorm2d-138 [-1, 1024, 28, 28] 2,048
ReLU-139 [-1, 1024, 28, 28] 0
Bottleneck-140 [-1, 1024, 28, 28] 0
Conv2d-141 [-1, 512, 28, 28] 524,288
BatchNorm2d-142 [-1, 512, 28, 28] 1,024
ReLU-143 [-1, 512, 28, 28] 0
Conv2d-144 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-145 [-1, 512, 14, 14] 1,024
ReLU-146 [-1, 512, 14, 14] 0
Conv2d-147 [-1, 2048, 14, 14] 1,048,576
BatchNorm2d-148 [-1, 2048, 14, 14] 4,096
Conv2d-149 [-1, 2048, 14, 14] 2,097,152
BatchNorm2d-150 [-1, 2048, 14, 14] 4,096
ReLU-151 [-1, 2048, 14, 14] 0
Bottleneck-152 [-1, 2048, 14, 14] 0
Conv2d-153 [-1, 512, 14, 14] 1,048,576
BatchNorm2d-154 [-1, 512, 14, 14] 1,024
ReLU-155 [-1, 512, 14, 14] 0
Conv2d-156 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-157 [-1, 512, 14, 14] 1,024
ReLU-158 [-1, 512, 14, 14] 0
Conv2d-159 [-1, 2048, 14, 14] 1,048,576
BatchNorm2d-160 [-1, 2048, 14, 14] 4,096
ReLU-161 [-1, 2048, 14, 14] 0
Bottleneck-162 [-1, 2048, 14, 14] 0
Conv2d-163 [-1, 512, 14, 14] 1,048,576
BatchNorm2d-164 [-1, 512, 14, 14] 1,024
ReLU-165 [-1, 512, 14, 14] 0
Conv2d-166 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-167 [-1, 512, 14, 14] 1,024
ReLU-168 [-1, 512, 14, 14] 0
Conv2d-169 [-1, 2048, 14, 14] 1,048,576
BatchNorm2d-170 [-1, 2048, 14, 14] 4,096
ReLU-171 [-1, 2048, 14, 14] 0
Bottleneck-172 [-1, 2048, 14, 14] 0
Conv2d-173 [-1, 256, 14, 14] 524,288
BatchNorm2d-174 [-1, 256, 14, 14] 512
Conv2d-175 [-1, 256, 14, 14] 589,824
BatchNorm2d-176 [-1, 256, 14, 14] 512
Conv2d-177 [-1, 256, 14, 14] 65,536
BatchNorm2d-178 [-1, 256, 14, 14] 512
Conv2d-179 [-1, 256, 14, 14] 524,288
BatchNorm2d-180 [-1, 256, 14, 14] 512
detnet_bottleneck-181 [-1, 256, 14, 14] 0
Conv2d-182 [-1, 256, 14, 14] 65,536
BatchNorm2d-183 [-1, 256, 14, 14] 512
Conv2d-184 [-1, 256, 14, 14] 589,824
BatchNorm2d-185 [-1, 256, 14, 14] 512
BatchNorm2d-197 [-1, 30, 14, 14] 60
================================================================
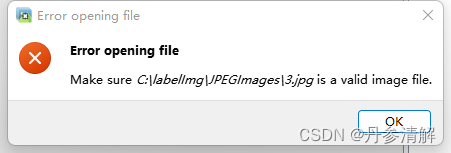
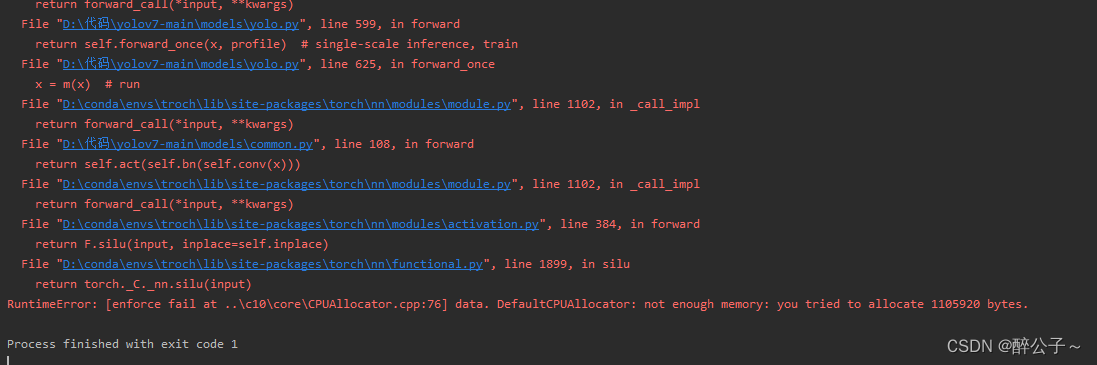
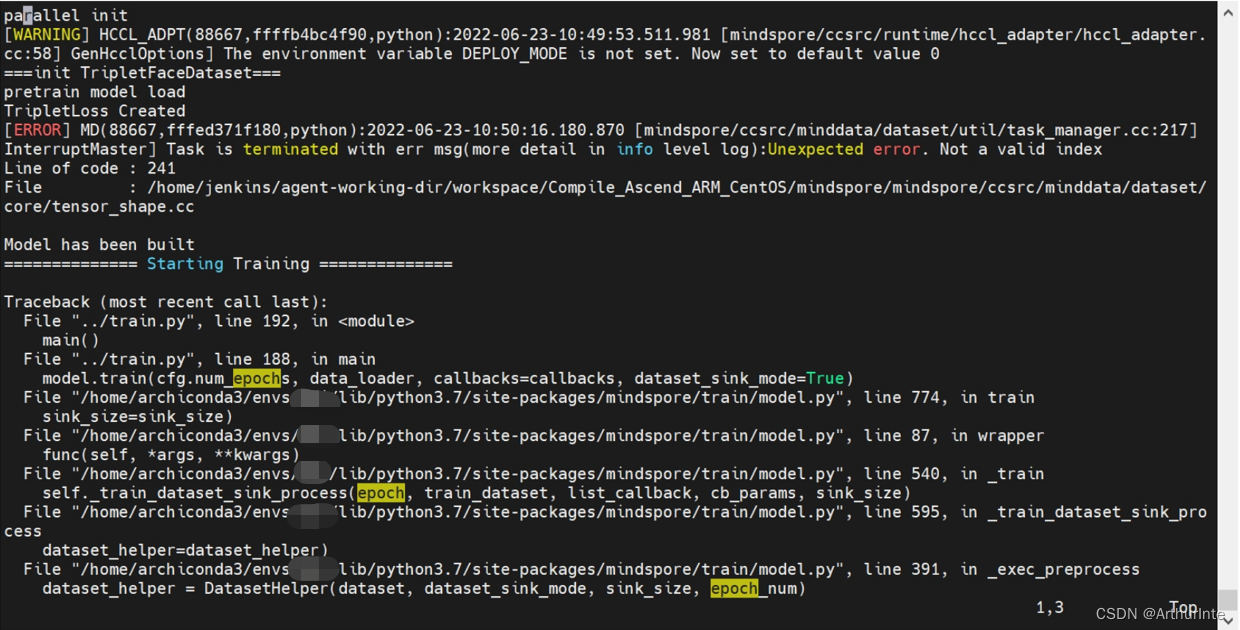
Error reported:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
Run the model in the graphics card:
from torchsummary import summary
summary(net.cuda(), (3, 448, 448))