Tensorflow failed to create cublas handle: cublas_ STATUS_ ALLOC_ FAILED
Foreword problem description problem solving reference link
preface
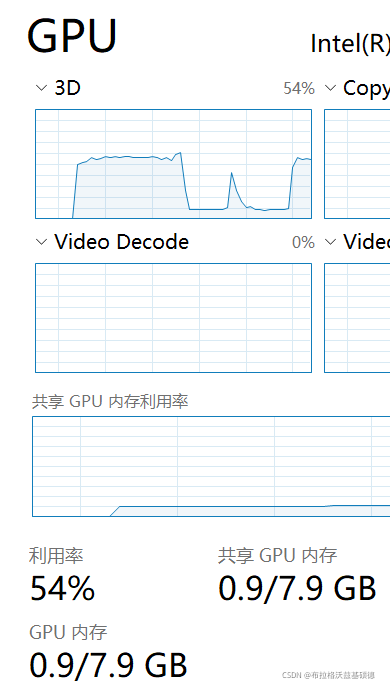
After many days of in-depth learning, I finally learned to use GPU. I was very happy, but I chatted with my classmates and learned that my 1660ti running in-depth learning is nothing. Dunton doesn’t hold any hope. It’s good to use notebooks for learning. If you really run in-depth learning, you have to use laboratory computers. Alas, there’s still no money
Problem description
An error occurred while using GPU
2021-11-09 20:43:26.114720: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll
2021-11-09 20:43:26.386261: E tensorflow/stream_executor/cuda/cuda_blas.cc:238] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2021-11-09 20:43:26.386617: E tensorflow/stream_executor/cuda/cuda_blas.cc:238] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2021-11-09 20:43:26.386735: W tensorflow/stream_executor/stream.cc:1919] attempting to perform BLAS operation using StreamExecutor without BLAS support
Traceback (most recent call last):
File "first.py", line 30, in <module>
gpu_time = timeit.timeit(gpu_run,number=10)
File "D:\Anaconda\Anaconda3\envs\tensorflow2_0_0_gpu\lib\timeit.py", line 233, in timeit
return Timer(stmt, setup, timer, globals).timeit(number)
File "D:\Anaconda\Anaconda3\envs\tensorflow2_0_0_gpu\lib\timeit.py", line 177, in timeit
timing = self.inner(it, self.timer)
File "<timeit-src>", line 6, in inner
File "first.py", line 21, in gpu_run
c = tf.matmul(gpu_a,gpu_b)
File "D:\Anaconda\Anaconda3\envs\tensorflow2_0_0_gpu\lib\site-packages\tensorflow_core\python\util\dispatch.py", line 180, in wrapper
return target(*args, **kwargs)
File "D:\Anaconda\Anaconda3\envs\tensorflow2_0_0_gpu\lib\site-packages\tensorflow_core\python\ops\math_ops.py", line 2765, in matmul
a, b, transpose_a=transpose_a, transpose_b=transpose_b, name=name)
File "D:\Anaconda\Anaconda3\envs\tensorflow2_0_0_gpu\lib\site-packages\tensorflow_core\python\ops\gen_math_ops.py", line 6126, in mat_mul
_six.raise_from(_core._status_to_exception(e.code, message), None)
File "<string>", line 3, in raise_from
tensorflow.python.framework.errors_impl.InternalError: Blas GEMM launch failed : a.shape=(10000, 1000), b.shape=(1000, 2000), m=10000, n=2000, k=1000 [Op:MatMul] name: MatMul/
I was in a hurry to find out the reason. I didn’t have enough video memory, and the GPU didn’t run full
Solution:
There are two main reasons
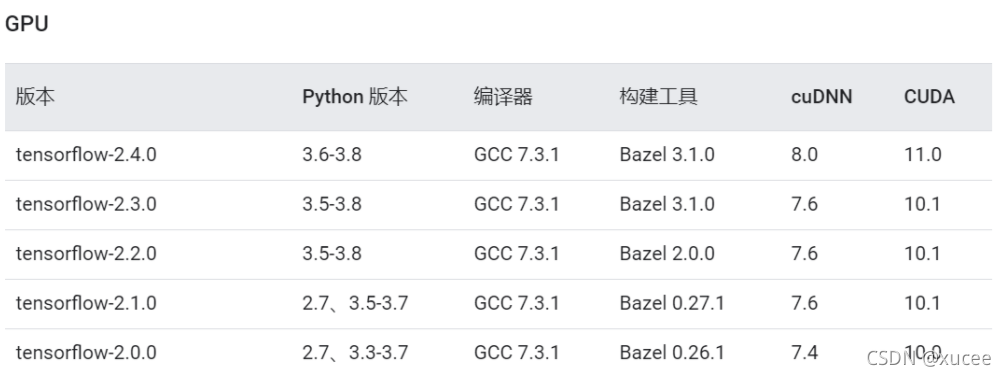
1. The versions of cudnn and CUDA and tensorflow are not applicable, but mine are based on the tutorial and confirmed several times to ensure that they are OK. This excludes the shortage of GPU video memory. It can be solved through the method on the official website: t because ensorflow 2.0 supports two GPU computing methods:
(1) dynamically allocate video memory
(2) set hard video memory (for example, only 1g video memory can be used, and others can play games
set the mode to (1) dynamic allocation, and the code is;
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)