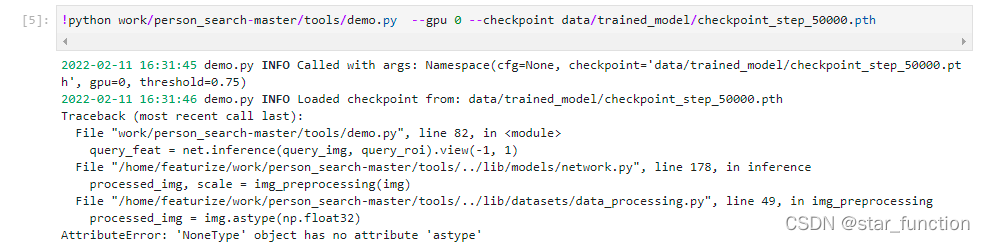
RuntimeError: unexpected EOF, expected 73963 more bytes. The file might be corrupted.
Problem Description:
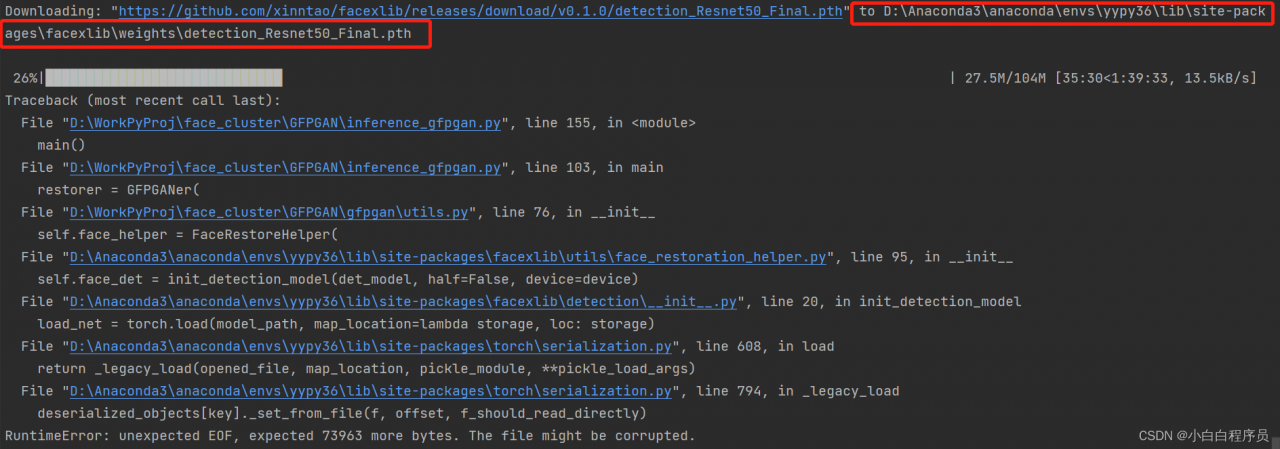
When the project executes Python script, when downloading the pre training model weight of pytorch, if the weight is not downloaded due to network instability and other reasons, an error will be reported runtimeerror: unexpected EOF, expected xxxxx more bytes The file might be corrupted.
Cause analysis:
This error indicates that the downloaded weight file may be damaged. You need to delete the damaged weight file and execute the code to download again.
Solution:
To find the location where the downloaded weight file is saved, this paper analyzes three situations:
1. Windows System & Anaconda Environment
The path of download is D:\Anaconda3\anaconda\envs\yypy36\Lib\site-packages\facexlib\weightsdetection_Resnet50_Final.pt, so you need go to this folder and delete the weight file as the screenshot below:
 2. Windows system & Python environment:
2. Windows system & Python environment:
The code automatically downloads the model weights file and saves it to the C:\Users\username/.cache\torch\checkpoints folder. Note that .cache may be a hidden file, you need to view the hidden file to see it, just delete the weight file.
3. Linux systems:
Linux system weights files are usually saved under: \home\username\.cache\torch. Note that .cache is a hidden folder and will only be shown if you press ctrl+Alt+H in winSCP; or, in the home directory, use ls -a to show it. root mode, the default path for downloaded weight files is under: /root/.cache/torch/checkpoints. Just delete the weight file.
In the above three cases, after deleting the weight file, execute the code again to download again.
Additional:
If the execution program downloads the code too slowly or the network stability is not good, we can directly download it manually from the website where the weight file is located and put it in the specified location. The Linux system can adopt WGet method.
wget -P Local path where the weights are saved Address of the weights
If the download is interrupted, WGet supports continuous transmission at breakpoints. Add a parameter - C :
wget -P Local path where weights are saved -c Address of weights
eg:
wget -P /home/20220222Proj/pretrained_models -c https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth