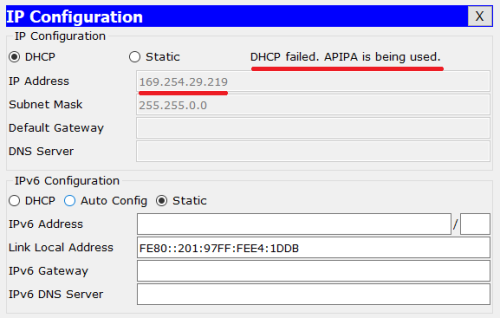
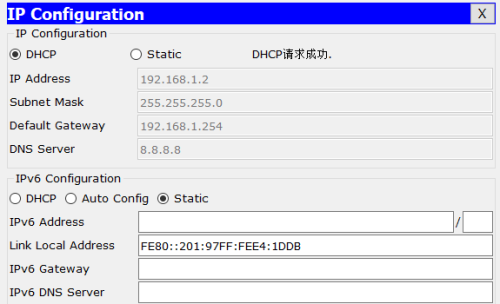
swap partition closes
is ready to adjust the utilization of the swap partition under Linux.
executing swapoff-a-v under Linux reports the following error:
swapoff: /dev/mapper/cryptswap1: swapoff failed: Cannot allocate memory
error cause analysis:
can be seen from the above information, the current Linux/dev/mapper/cryptswap1 this device as a swap partition, if the current swap partition instead of the current remaining capacity is greater than the system memory, will quote this mistake, because at the time of closing swap partition, all need to partition data written to the memory, if the memory capacity is insufficient, will cause the error.
resolved:
method 1: free memory cache
# sync ; echo 3 > /proc/sys/vm/drop_caches #先把内存数据回写到磁盘,然后释放内存缓存
drop_caches accepted parameters are 1, 2, 3, empting pagecache, slab object, pagecahce, and slab object
, respectively
parameters explanation to this file can be found from https://github.com/torvalds/linux/blob/master/Documentation/sysctl/vm.txt:
drop_caches
Writing to this will cause the kernel to drop clean caches, as well as
reclaimable slab objects like dentries and inodes. Once dropped, their
memory becomes free.
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free reclaimable slab objects (includes dentries and inodes):
echo 2 > /proc/sys/vm/drop_caches
To free slab objects and pagecache:
echo 3 > /proc/sys/vm/drop_caches
dirty state memory cache will not be freed. To free as much memory cache as possible, first execute the command sync to reduce memory cache in the dirty state. If disable, the input parameter 4, note that 0 is not acceptable:
the above method may not work if you use too much swap partition.
method 2: allows memory overcommit
overcommit_memory controls “when user space requests memory, overcommit and approve:
When this flag is 0, the kernel attempts to estimate the amount
of free memory left when userspace requests more memory.
When this flag is 1, the kernel pretends there is always enough
memory until it actually runs out.
When this flag is 2, the kernel uses a "never overcommit"
policy that attempts to prevent any overcommit of memory.
Note that user_reserve_kbytes affects this policy.
2 means overcommit is not allowed. At this point, if swap is stopped, the available memory is reduced and the user space memory request may trigger overcommit to be rejected.
Reference
https://www.lijiaocn.com/%E9%97%AE%E9%A2%98/2019/02/27/linux-swap-off-fail.html
reproduced in: https://www.cnblogs.com/yjt1993/p/11163679.html
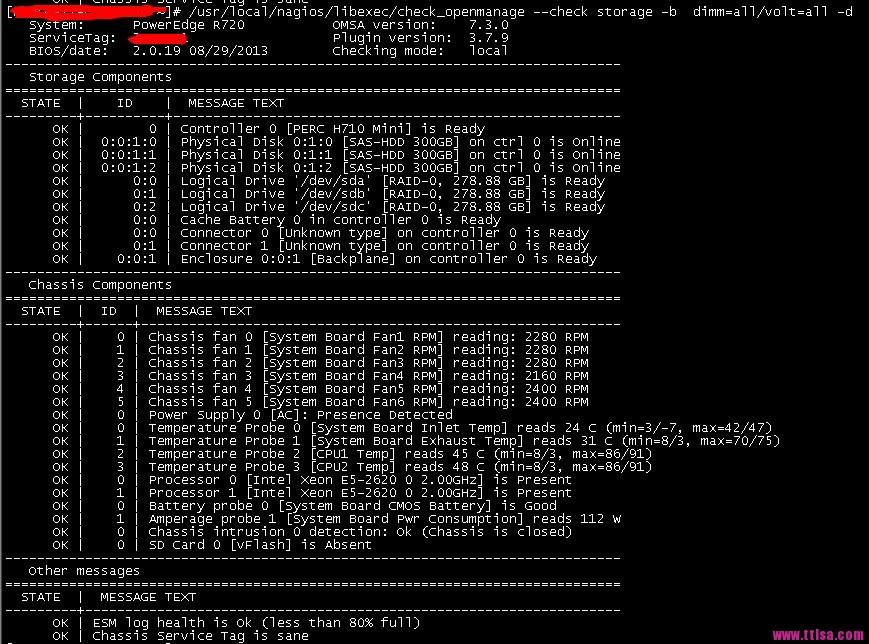 can see that the memory and Voltage are not tested. Memory will be detected without dimm=all.
can see that the memory and Voltage are not tested. Memory will be detected without dimm=all.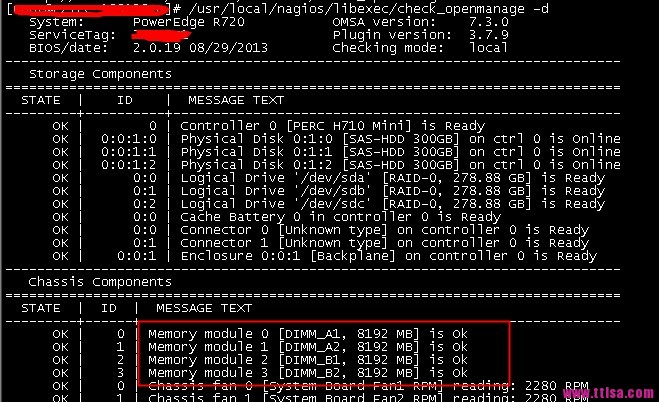 is able to block the detection of relevant hardware. Such as temperature detection and so on. Such as:
is able to block the detection of relevant hardware. Such as temperature detection and so on. Such as: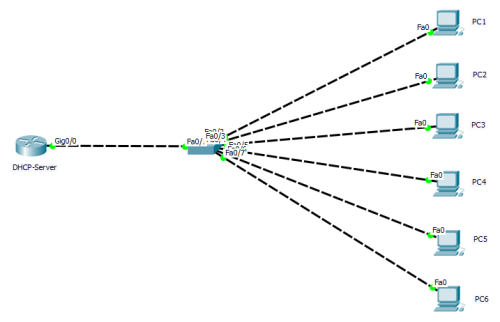 diagram, routers were dhCP-server and switches were two-layer devices (switch ports connected to PC1-6 hosts were all in the default VLAN 1).
diagram, routers were dhCP-server and switches were two-layer devices (switch ports connected to PC1-6 hosts were all in the default VLAN 1).