Sparkcontext: error initializing sparkcontext workaround
Spark reports an error when configuring a highly available cluster
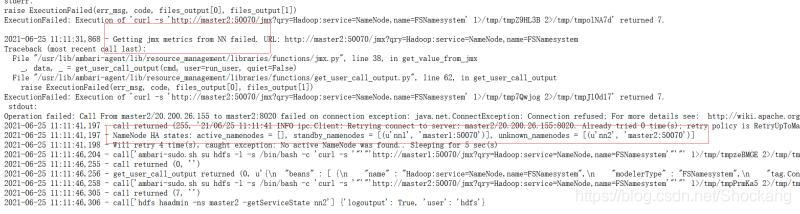
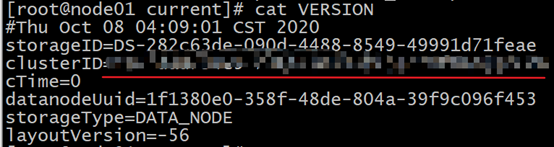
error sparkcontext: error initializing sparkcontext. Java.net.connectexception: call from Hadoop 102/192.168.10.102 to Hadoop 102: 8020 failed on connection exception: java.net.connectexception: connection rejected
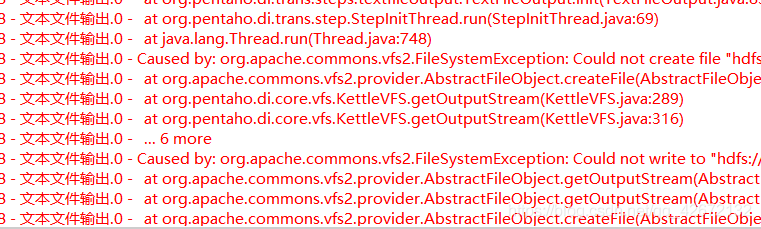
This is because we configured spark logs to be stored in HDFS, but Hadoop was not opened after the spark cluster was started, resulting in an error when submitting tasks.
Solution:
- no longer store the event log
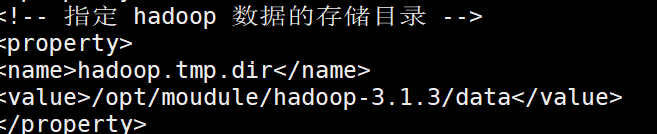
find the spark installation directory/conf/spark-defaults.conf file, as shown in the figure, and comment out the corresponding event log part
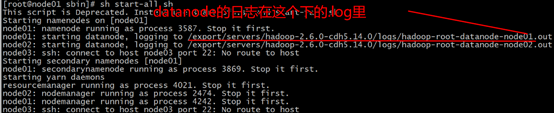
replace the directory in the second line in the figure above with the Linux local directory to start the Hadoop cluster (i.e. HDFS service)
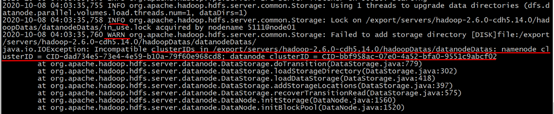
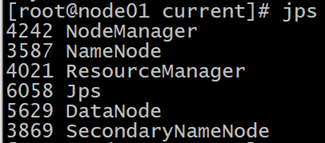
investigate the cause of the error, Or we configured the spark log to be stored in HDFS, but did not open HDFS, so start the Hadoop cluster
 under this directory
under this directory