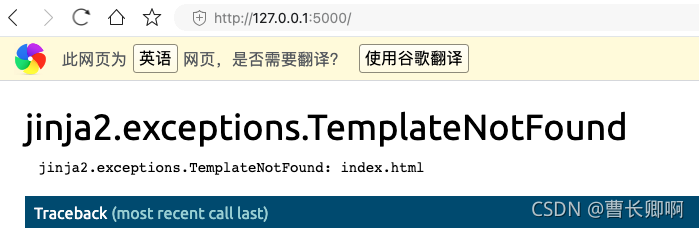
reason:
reder_template directory is to find the folder templates in the current directory. The index.html file should be placed in the folder templates.
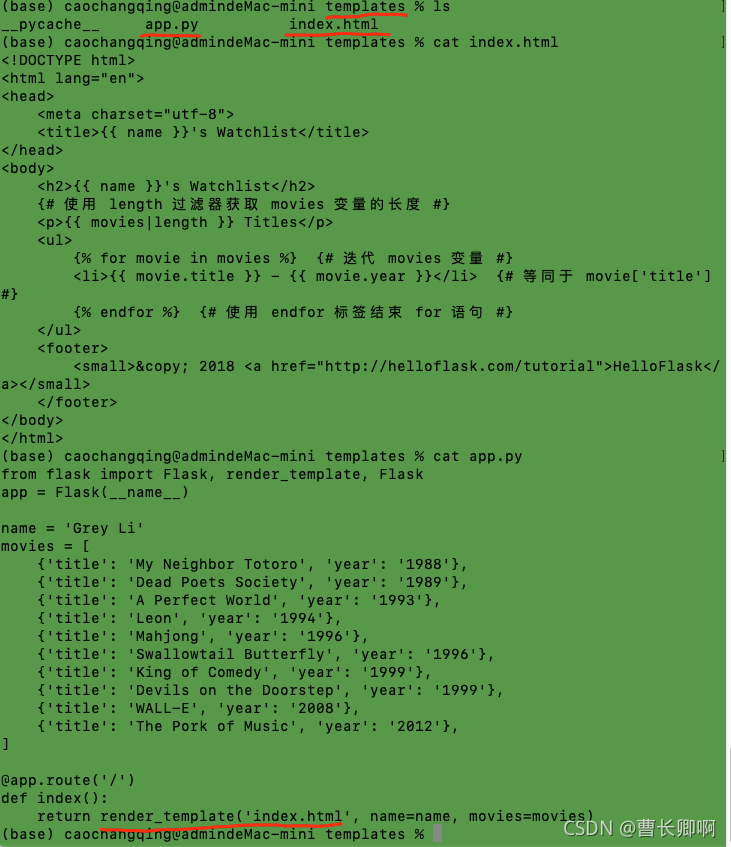
Solution:
Put app.py in the Templates folder outside the folder.
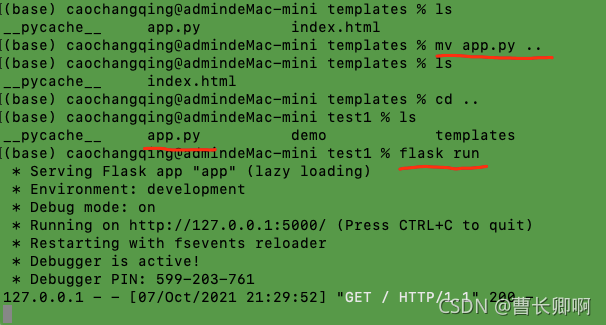
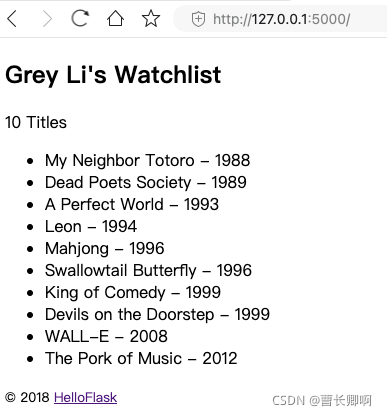
reason:
reder_template directory is to find the folder templates in the current directory. The index.html file should be placed in the folder templates.
Solution:
Put app.py in the Templates folder outside the folder.
Administrator@ecs -9970 MINGW64 /c/harmonyohos/exoplayer
$ git clone https://gitee.com/xxxxx/xxxxx.git
Cloning into ‘exo-player_ ohos’…
remote: Access denied
fatal: unable to access ‘ https://gitee.com/xxxxx/xxxxx.git/ ‘: The requested URL returned error: 403
First, through Git Config — global — list check whether the current git global information is the logged in gitee account. If the information is incorrect, reset it
git config –global user.name “xxxxx”
git config –global user.email “xxxxx”
git config –global user.password “xxxxx”
Then check whether the windows credential information is consistent with the logged in gitee account information
Control panel\all control panel items\credential manager\windows credentials, modify account
The environment configuration is Ubuntu 16.04, tensorflow 1.13.1, cuda10, cudnn7.6.4.
Error when running tensorflow code
UnknownError (see above for traceback): Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
With the tensorflow, cuda, and cudnn versions corresponding correctly, add the following code to the code.
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
config = tf.ConfigProto()
config.allow_soft_placement=True # If the device you specify does not exist, allow TF to allocate the device automatically
config.gpu_options.per_process_gpu_memory_fraction = 0.9 #Allocate a portion of the video memory to the program to avoid memory overflow
config.gpu_options.allow_growth = True #Allocate video memory on demand
with tf.Session(config=config) as sess:
#Your Codes
Modify grub to solve computer startup error: error 17
The original computer has C, D, e, F, G. C disk, windows system disk and G disk are installed with CentOS. Later, due to the need to compress the volume of the way from the D disk compressed out of an H disk. Then when I started the computer again, I encountered an error: error 17
The reason:
is that windows is installed first and then Linux is installed. In this way, grub is booted by CentOS on disk g. now a new logical partition is divided before the partition, which causes the disk system symbol to move backward by one bit. Therefore, grub fails.
Solution:
1, burn a Linux Installation U disk, enter BIOS, modify boot items, and boot from U disk.
2. I use RedHat 7.0. After the U disk is started, enter the troubleshooting option, and then enter the rescue a @ #% $%. Enter all the way to shell mode.
3. In shell mode, use fdisk – L to view all partitions of the computer, and find that the original CentOS partition is sdb9. Grub command enters grub, root (hd1,8) command specifies partition, setup (HD1) installs grub to corresponding partition, and quit grub.
At this time, boot the hard disk again, and you can already see grub. But only windows can start, CentOS will report error, error 17, cannot mount
4. Start the U disk again and enter the shell mode under rescue. Check the grub configuration file of Linux system to see if there is any problem. I have a look, and there is no problem.
#mkdir linux
#mount /dev/sdb9 linux
#cd linux
#cd grub
#vi grub.conf5. Start the hard disk, enter grub interface, move the cursor to the startup option of Linux, press e key to modify the startup sequence. Change the root (hd0,7) option to root (hd0,8) and enter. It’s ready to start.
New skills get!
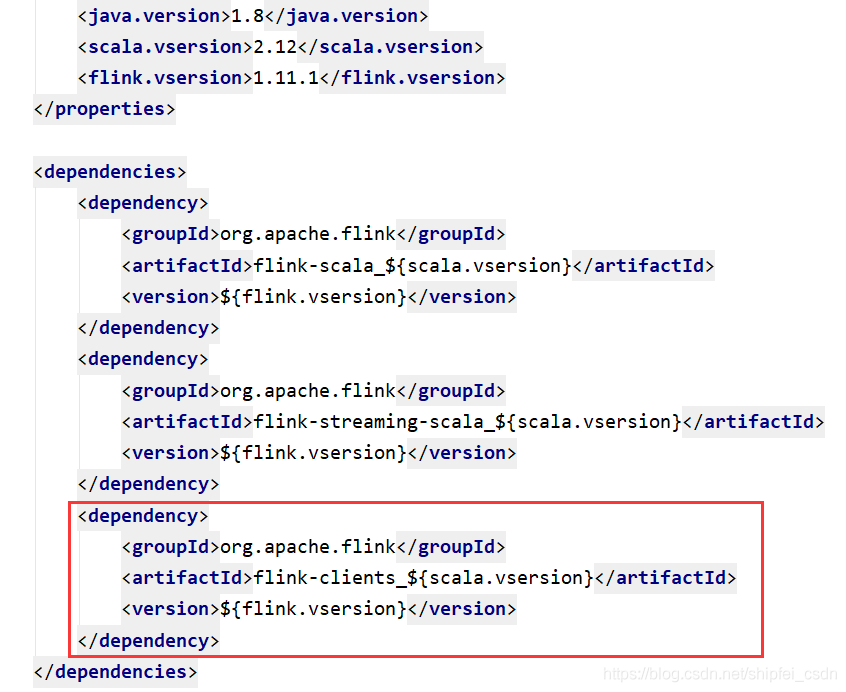
Error reported when migrating Flink to 1.1:
No ExecutorFactory found to execute the application
After investigation, the reason is: starting from flink1.11, the Flink streaming Java dependency on Flink clients has been removed, and the clients dependency needs to be added manually.
The POM file is as follows, add Flink clients_ 2.12, problem solving.
This article records the solutions for bloggers to report errors in Import torch in Python. Updated on March 20, 2019.
This error is due to the current version of numpy does not meet the requirements.
First, run on the terminal:
python
import numpy
numpy.version
View the current version of numpy. Run after
pip3 install –upgrade numpy
Just update the numpy version. If it’s python2, use PIP .
More, welcome to the planet discussion.

Ansoft :Com Engine Non-responsive since 17:23:04, October 18, 2015.If Persisting for Long, Functional Testing kills the Com Engine Process and Restart Analysis.
When this situation occurs in Ansoft simulation, the progress bar is 0 and unchanged. Many methods have been tried on the Internet, but the software crashed and was closed and then opened, which can be simulated normally.
Six ways:
Absolute plus margin solution fixed plus margin solution display:table solution line-height solution flex layout solution transform unknown element width and height solution
Absolute + margin scheme
div{
position: absolute;
width: 100px;
height: 100px;
left: 50%;
top: 50%:
margin-top: -50px;
margin-left: -50px;
}
Fixed plus margin scheme
div{
position: fixed;
width: 100px;
height: 100px;
top: 0;
right:0;
left: 0;
bottom: 0;
margin: auto;
}
Display: table scheme
div{
display: table-cell;
vertical-align: middle;
text-align: center;
width: 100px;
height: 100px;
}
The line-height scheme for the inline element
div{
text-align: center;
line-height: 100px;
}
Flex Flexible Layout Solution
div{
display: flex;
align-items: center;
justify-content:center
}
Transform unknown element width and height solution
div{
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%)
}
Problem orientation
In fact, the specific issue of the official seven years ago (reference), but the more pit is that the official has not solved the problem. Simply put, a bug in the JRE running environment of IDEA causes the input method to be unable to locate the mouse position. Therefore, we need to modify the running code of JetBrainsRuntime to fix this problem.
The solution
Modify JetBrainsRuntime
Change your own JRE directory
/home/ XXX /idea-2020.1/bin/idea.shhome/XXX /idea-2020.1/bin/idea.sh
port IDEA_JDK=/home/ XXX /idea-2020.1/java-11.0.7-jetbrain.>r> export IDEA_JDK=/home/ XXX /idea-2020.1/java-11.0.7-jetbrain
Appendix:
JetBrainsRuntime
In terminal use of VSCode, using NPM run dev causes an error
Error: Cannot find module 'webpack/bin/config-yargs
It is possible that the webpack-dev-server version number is too low
The solution
Uninstall webpack-dev-server globally first
npm uninstall webpack-dev-server -g
Then install the latest version
npm install webpack-dev-server@latest
Question:
Install CNPM on the new computer. When running CNPM-V in VSCODE terminal, the following error will be reported:
CNPM: Unable to load file
C:\Users\Administrator\AppData\ NPM \cnpm.ps1 because script is not allowed to run on this system. For more information, please refer to the
https:/go.microsoft.com/fwlink/?
about_Execution_Policies in LinkID=135170. Position line :1 character :1
cnpm -v+ CategoryInfo : SecurityError: (:) [],PSSecurityException + FullyQualifiedErrorId : UnauthorizedAccess
Solution:
(1) Run VS Code as an administrator and open a terminal in VS Code
(2) Execute Get-ExecutionPolicy at the terminal, displaying Restricted
(3) Update the PowerShell policy and execute it on the terminal: set-executionpolicy RemoteSigned
(4) Examine the status of the policy again and execute: GET-EXECUTIONPOLICY at the terminal to show the RemoteSigned igned
(5) Re-input CNPM-V problem successfully solved
Just taking notes.
Ssl. syscallError :(-1,’Unexpected EOF’)
Verify = False: verify = False: verify = False: verify = False
Request, when using a proxy to crawl a web page
Verify = False; verify = False
code
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True )
Verify = False
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True, verify = False )