1. Error environment
1. System version: CentOS7.7
2. IPA version: 4.6.8
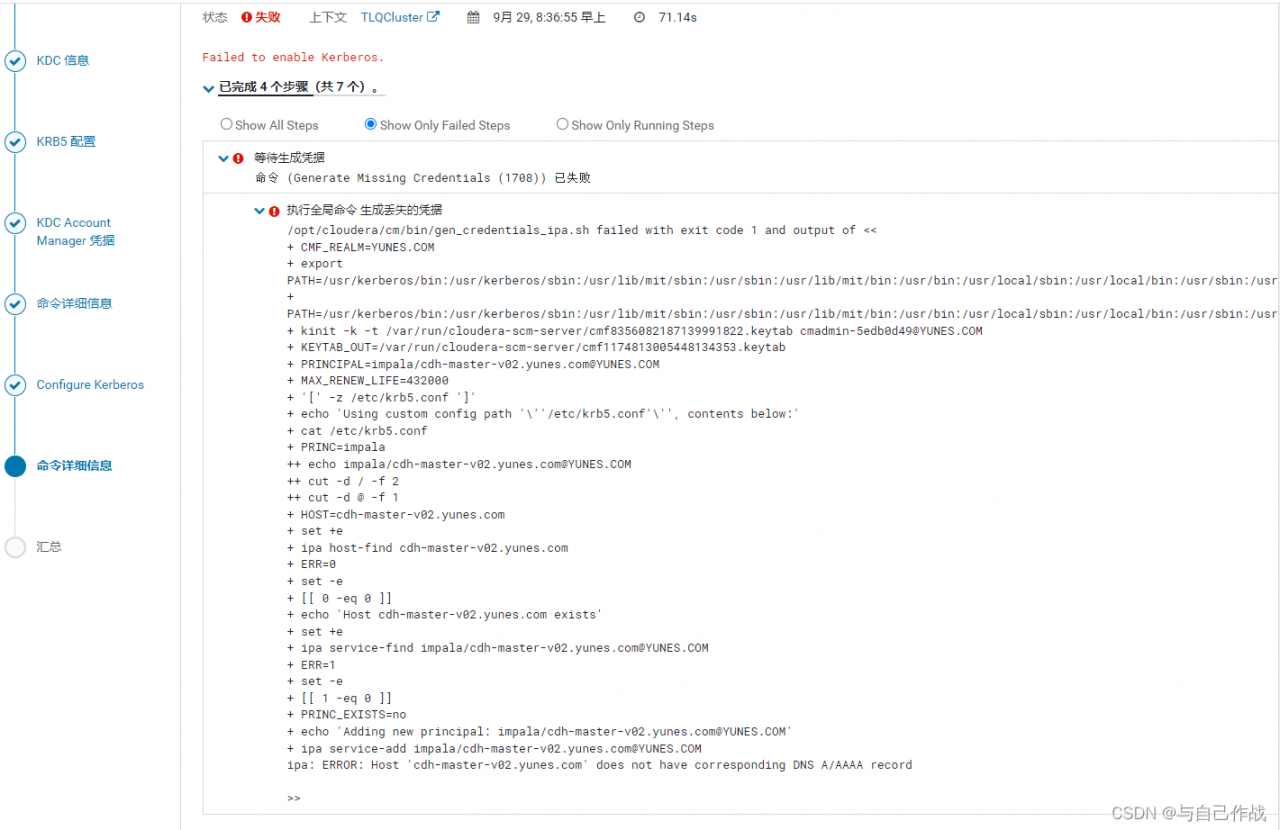
2. Error occurred when installing Kerberos
1. Error description:
Execute global command Generate lost credentials
/opt/cloudera/cm/bin/gen_credentials_ipa.sh failed with exit code 1 and output of <<
+ CMF_REALM=YUNES.COM
+ export PATH=/usr/kerberos/bin:/usr/kerberos/sbin:/usr/lib/mit/sbin:/usr/sbin:/usr/lib/mit/bin:/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
+ PATH=/usr/kerberos/bin:/usr/kerberos/sbin:/usr/lib/mit/sbin:/usr/sbin:/usr/lib/mit/bin:/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
+ kinit -k -t /var/run/cloudera-scm-server/cmf8356082187139991822.keytab [email protected]
+ KEYTAB_OUT=/var/run/cloudera-scm-server/cmf1174813005448134353.keytab
+ PRINCIPAL=impala/[email protected]
+ MAX_RENEW_LIFE=432000
+ '[' -z /etc/krb5.conf ']'
+ echo 'Using custom config path '\''/etc/krb5.conf'\'', contents below:'
+ cat /etc/krb5.conf
+ PRINC=impala
++ echo impala/[email protected]
++ cut -d/-f 2
++ cut -d @ -f 1
+ HOST=cdh-master-v02.yunes.com
+ set +e
+ ipa host-find cdh-master-v02.yunes.com
+ ERR=0
+ set -e
+ [[ 0 -eq 0 ]]
+ echo 'Host cdh-master-v02.yunes.com exists'
+ set +e
+ ipa service-find impala/[email protected]
+ ERR=1
+ set -e
+ [[ 1 -eq 0 ]]
+ PRINC_EXISTS=no
+ echo 'Adding new principal: impala/[email protected]'
+ ipa service-add impala/[email protected]
ipa: ERROR: Host 'cdh-master-v02.yunes.com' does not have corresponding DNS A/AAAA record
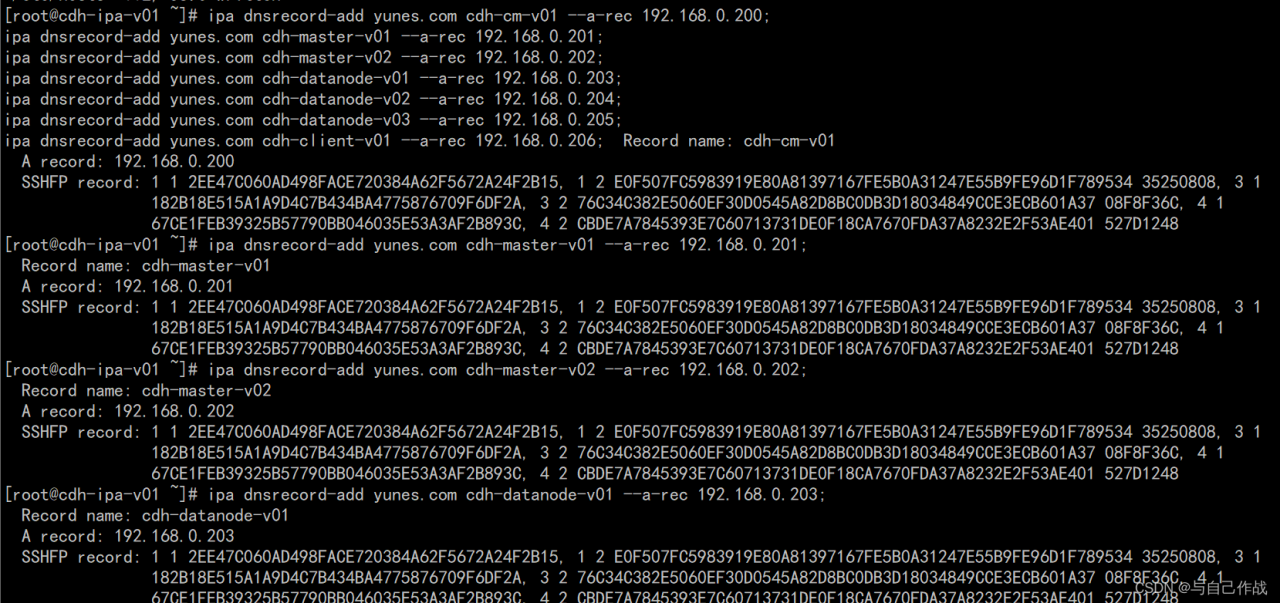
2, the solution (may be version differences in their own choice of test)
1)
ipa dnsrecord-add yunes.com cdh-cm-v01 –a-rec 192.168.0.200;
ipa dnsrecord-add yunes.com cdh-master-v01 –a-rec 192.168.0.201;
ipa dnsrecord-add yunes.com cdh-master-v02 –a-rec 192.168.0.202;
ipa dnsrecord-add yunes.com cdh-datanode-v01 –a-rec 192.168.0.203;
ipa dnsrecord-add yunes.com cdh-datanode-v02 –a-rec 192.168.0.204;
ipa dnsrecord-add yunes.com cdh-datanode-v03 –a-rec 192.168.0.205;
ipa dnsrecord-add yunes.com cdh-client-v01 –a-rec 192.168.0.206;
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-cm-v01 --a-rec 192.168.0.200;
ipa dnsrecord-add yunes.com cdh-master-v01 --a-rec 192.168.0.201;
ipa dnsrecord-add yunes.com cdh-master-v02 --a-rec 192.168.0.202;
ipa dnsrecord-add yunes.com cdh-datanode-v01 --a-rec 192.168.0.203;
ipa dnsrecord-add yunes.com cdh-datanode-v02 --a-rec 192.168.0.204;
ipa dnsrecord-add yunes.com cdh-datanode-v03 --a-rec 192.168.0.205;
ipa dnsrecord-add yunes.com cdh-client-v01 --a-rec 192.168.0.206; Record name: cdh-cm-v01
A record: 192.168.0.200
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-master-v01 --a-rec 192.168.0.201;
Record name: cdh-master-v01
A record: 192.168.0.201
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-master-v02 --a-rec 192.168.0.202;
Record name: cdh-master-v02
A record: 192.168.0.202
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-datanode-v01 --a-rec 192.168.0.203;
Record name: cdh-datanode-v01
A record: 192.168.0.203
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-datanode-v02 --a-rec 192.168.0.204;
Record name: cdh-datanode-v02
A record: 192.168.0.204
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-datanode-v03 --a-rec 192.168.0.205;
Record name: cdh-datanode-v03
A record: 192.168.0.205
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]# ipa dnsrecord-add yunes.com cdh-client-v01 --a-rec 192.168.0.206;
Record name: cdh-client-v01
A record: 192.168.0.206
SSHFP record: 1 1 2EE47C060AD498FACE720384A62F5672A24F2B15, 1 2 E0F507FC5983919E80A81397167FE5B0A31247E55B9FE96D1F789534 35250808, 3 1
182B18E515A1A9D4C7B434BA4775876709F6DF2A, 3 2 76C34C382E5060EF30D0545A82D8BC0DB3D18034849CCE3ECB601A37 08F8F36C, 4 1
67CE1FEB39325B57790BB046035E53A3AF2B893C, 4 2 CBDE7A7845393E7C60713731DE0F18CA7670FDA37A8232E2F53AE401 527D1248
[root@cdh-ipa-v01 ~]#
2)
ipa dnsrecord-add 0.168.192.in-addr.arpa 200 –ptr-rec cdh-cm-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 201 –ptr-rec cdh-master-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 202 –ptr-rec cdh-master-v02.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 203 –ptr-rec cdh-datanode-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 204 –ptr-rec cdh-datanode-v02.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 205 –ptr-rec cdh-datanode-v03.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 206 –ptr-rec cdh-client-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 200 --ptr-rec cdh-cm-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 201 --ptr-rec cdh-master-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 202 --ptr-rec cdh-master-v02.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 203 --ptr-rec cdh-datanode-v01.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 204 --ptr-rec cdh-datanode-v02.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 205 --ptr-rec cdh-datanode-v03.yunes.com.
ipa dnsrecord-add 0.168.192.in-addr.arpa 206 --ptr-rec cdh-client-v01.yunes.com.