directory
Install Xen Virtual Machine with Virt-Manager Install Xen Virtualization Install Virt-Manager check libvirtd service status Create Xen Virtual machine view issues encountered with virtual machine status
Install the Xen virtual machine using virt-Manager
This article focuses on how to install the Xen virtual machine on CentOS 7 using Virt-Manager. The following environments need to be prepared:
CentOS 7Xen virtualization Virt-managerVMware Workstation 12
Note: The desktop version of CentOS7 is installed on the same host as Xen virtualization and Virt-Manager for this environment
Install Xen virtualization
See my post on Installing Xen virtualization under CentOS 7 for details
Install the virt – manager
Use the following command to install
yum install -y virt-manager
Check the status of the libvirtd service
Use the following command to see that the service starts properly
systemctl status libvirtd
Create the Xen virtual machine
Open the virt-Manager interface
virt-manager
To connect to Xen virtualization, click File-> Add Connection, select Xen, where Hostname fill in Xen virtualization server IP create virtual machine, right click Xen:localhost-> New opens the create page and selects the installation method specified. input Network Install Network Install installation address select the virtual machine memory and CPU configuration, the image installed in this paper is centos6.5-minnal version select the virtual machine disk size confirm the installation information (including the selection of Network configuration, whether to customize the configuration information), Check the first red box in the figure below if there is a custom requirement. click Finish to enter the installation interface. Installation steps are not described in this article, but you can find the installation tutorial by yourself
View virtual machine status
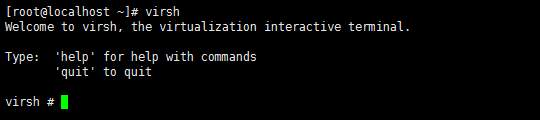
can be viewed through the virt-manager to enter the virtual machine command line by entering the following command
virsh
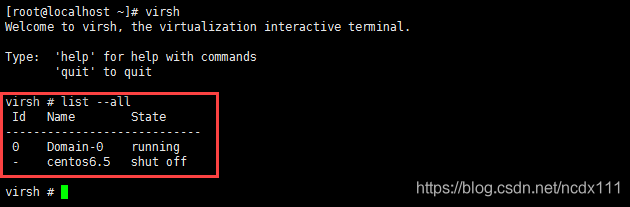
You can use help to view relevant commands. For example, enter the following command to see the virtual list and its status
list --all
Problems encountered
In the process of creating virtual machines using Virt-Manager, the following problems are encountered, and the solutions are attached for your reference. :'internal error:process exited while connecting to monitor:qemu:could not load PC BIOS 'bs-256k.bin ' Unable to complete install:’internal error:process exited while connecting to monitor:qemu:could not load PC BIOS’ bs-256k.bin ‘ Just create a BIOS -256k.bin file under seabios directory
incapable to complete install:'interbal error:libxenlight failed to create new domain 'centos6.5' 1. There is a centos6.5 virtual machine in the current virtual machine list. Rename the currently created virtual machine or delete the existing virtual machine to 2. Use the command yum update qemu-img to update the file 3. Determine if the memory and CPU of the virtual machine being created is greater than the memory and CPU of the host, and ensure that the virtual machine’s resources are smaller than those of the host
The Path cannot be found because the Samba Shared server is inaccessible
First blog post: P
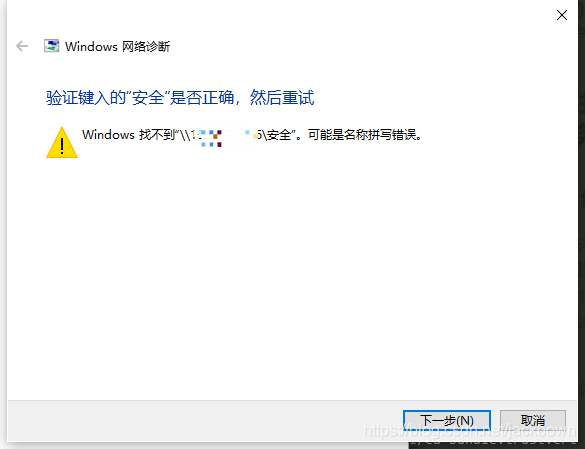
Windows access can only go to the root directory, opening the Shared subdirectory indicates that the path could not be found, spelling error may occur, and the server appears “make_connection_SNum: canonicalize_connect_Path Fail…”
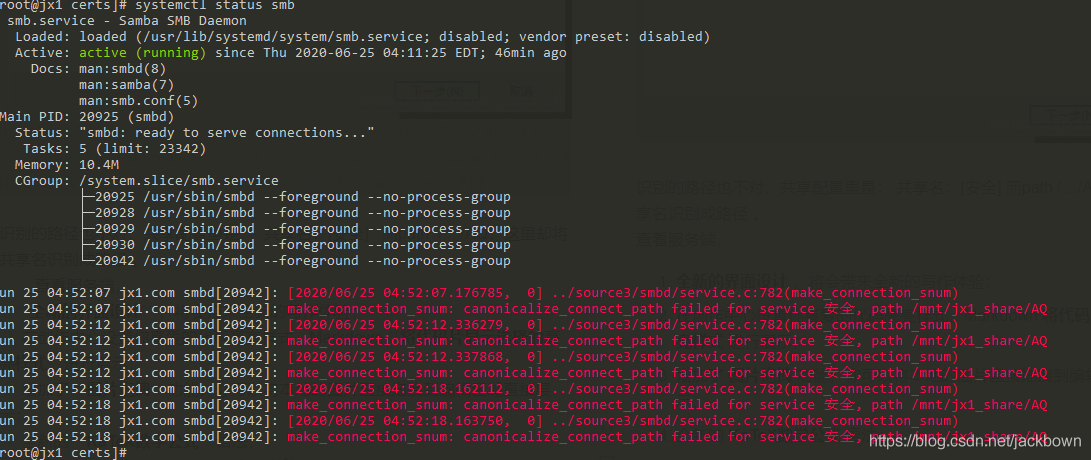
As an amateur, recently tried to built a Shared server, using the virtual machine to do the test before, run successfully, permissions can be implemented, the day before yesterday with a spare industrial control server, reinstall the Samba server, configuration files, and access configuration is copied, is unable to access, the same Windows, access to the original virtual machine SMB, completely normal, and access to the physical machine SMB, input \ IP address, a successful connection, input user name and password, is normal to list the Shared directory, but want to get into Shared subdirectory, have been tip don’t have access to: recognized the wrong path, the Shared configuration is: share name: [security] and path /… /AQ, which identifies the Shared name as a path. looks at the server and prompts “make_connection_snum: canonicalize_connect_path fails for service security, path/MNT /jx1_share/AQ”, the same is true for logging.
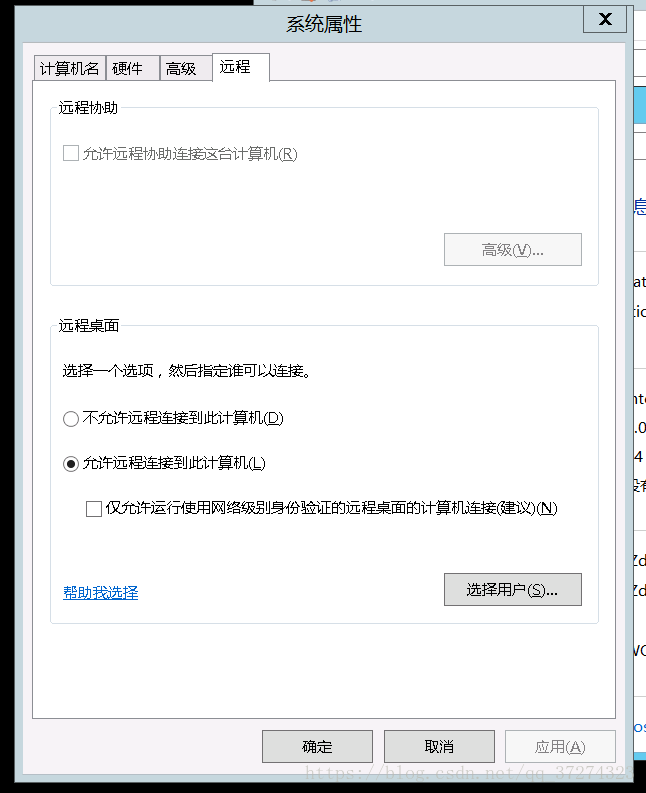
CredSSP Required by Server fails to connect when Liunx connects to Window server.
1. Connect to the server remotely on the web side. 2. Right click on my computer -> Property – & gt; Remote setting -& GT; 3. Uncheck computer connections that allow running remote desktops using network sector authentication only (recommended)(N)
The exact reason is not clear, but this operation successfully connected to the Aliyun server. Note: the image of ali cloud Server system is: Windows Server 2012 D2 Datacenter
Write in the last
I am a pure white, and the blog I write is also written because of the problems encountered in learning to use to find information and then solve the problem. If there are some mistakes, or involving infringement, please contact me.
QQ: 994961015 E-mail: [email protected] WeChat: this can not be given.
the new server version has arrived at CentOS8 today, but SSH Secure Shell is still 3.2.9 years ago, so I encountered an error in the title when connecting to the server. This question is a tragic waste of my time.
there are many, many posts on the web that address this problem, and they all go like this:
Sshd_config sudo vim /etc/ssh/sshd_config
2. at the end of the file add the following information Ciphers either aes128 – CBC, aes192 – CBC, aes256 – CBC, either aes128 – CTR, aes192 – CTR, aes256 – CTR, 3 des – CBC, arcfour128, arcfour256, arcfour, blowfish – CBC, cast128 – CBC MACs Hmac – md5, hmac – sha1, [email protected], hmac – ripemd160 digest, hmac – sha1-96, hmac – md5-96 KexAlgorithms diffie-hellman-group1-sha1,diffie-hellman-group14-sha1,diffie-hellman-group-exchange-sha1,diffie-hellman-group-exchange-sha256,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-g roup1-sha1,[email protected]
3. after saving SSH service sudo /etc/init.d/ SSH restart
everyone said it was good, but after I tried it, it was tragic. After I added the configuration, I could not restart SSH and it would report an error.
these two articles explain the real reason and offer a solution:
, however, I still failed to solve the problem, and finally decided to abandon the outdated SSH Secure Shell Client and replace it with FileZilla to solve the problem: FileZilla also supports SSH protocol to transfer files, and its operation is slightly more humane than SSH Secure Shell Client
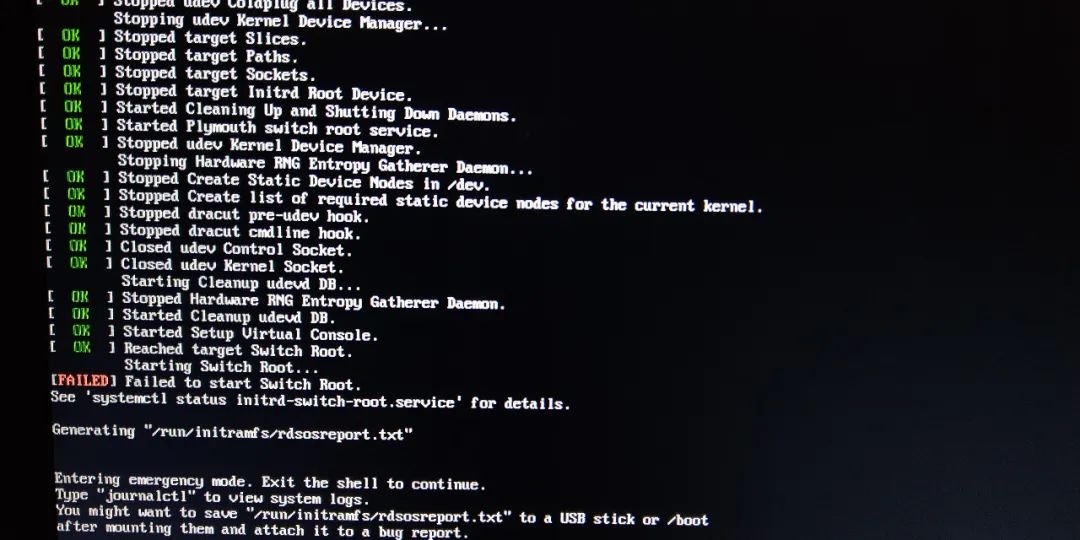
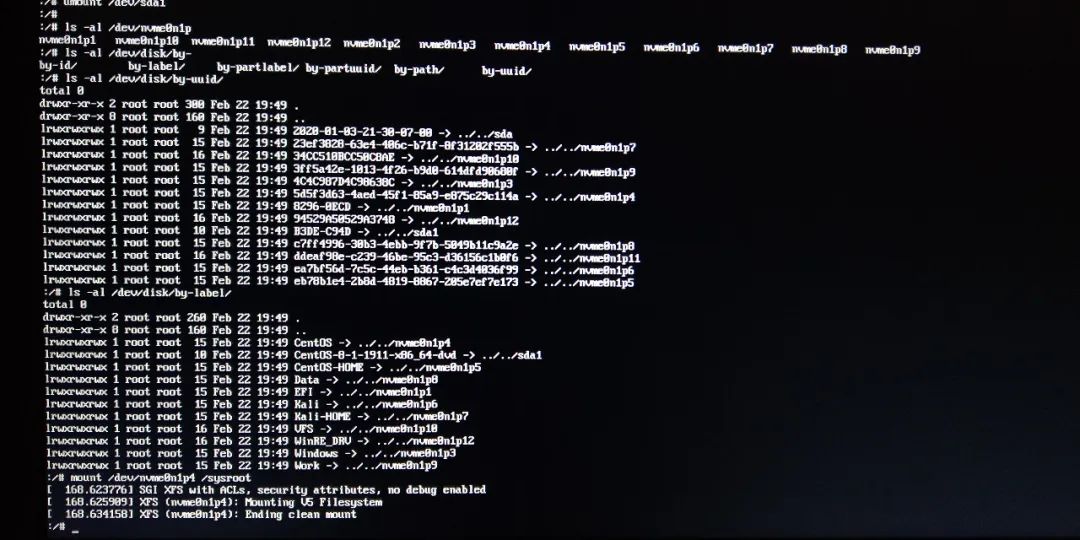
boot today found CentOS8.1 system can not boot!! I recall that I updated some system packages yesterday. At that time, the updated system was not restarted, and the updated system was not detected. It was an oversight!
take a closer look at the log and it turns out that the Switch Root is wrong, as shown below:
prompt error log generation, a simple look, want to get the U disk first, then follow up.
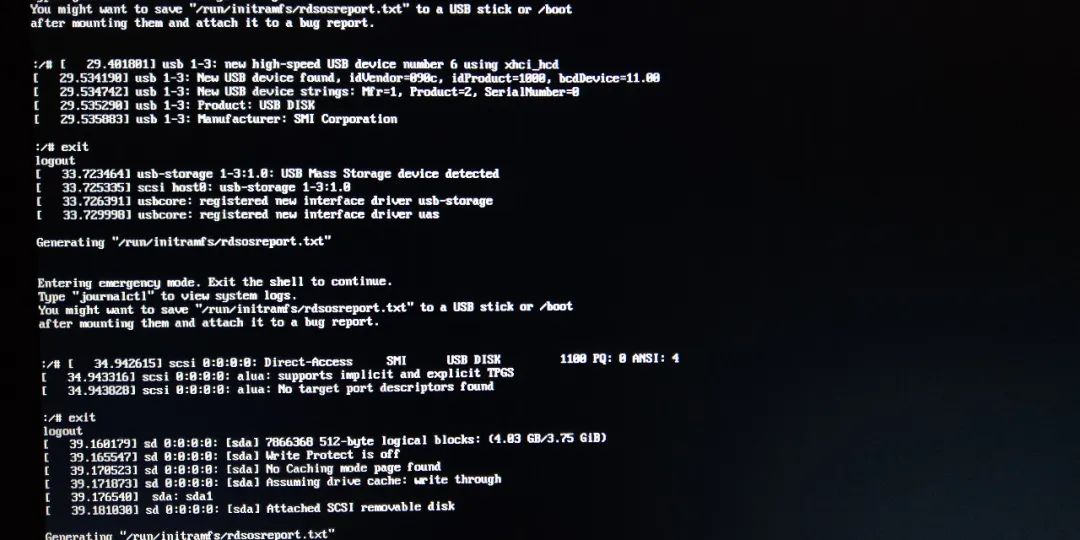
is inserted into the U disk, no device is detected, exit is performed, and sda is identified after repeated twice. As shown below:
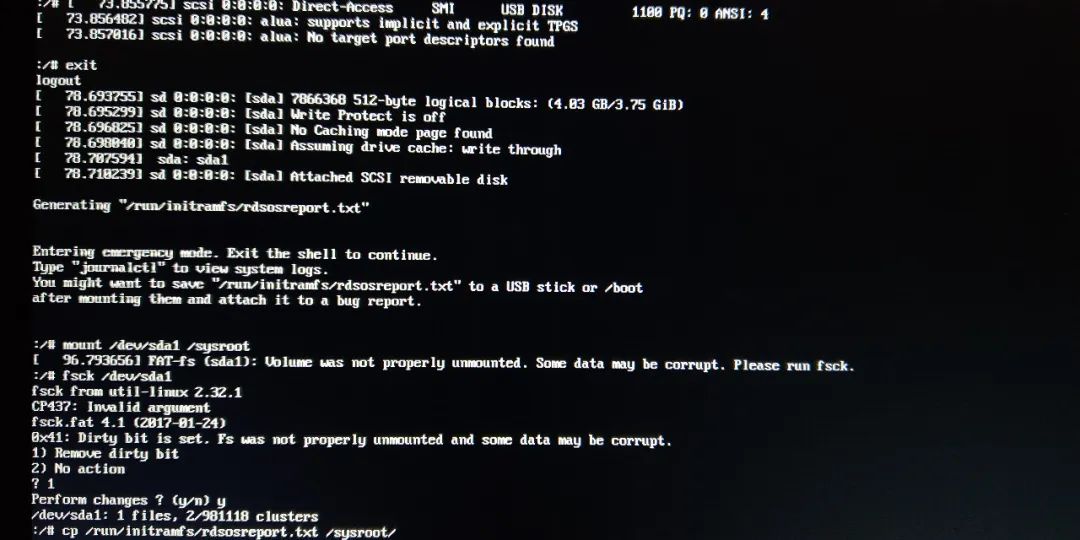
then U disk mounted to/sysroot, prompt data to test with U disk,, FSCK detection, the log file/run/initramfs/rdsosreport. TXT is copied to the U disk, and then uninstall U disk. As shown below:
try manually mounting CentOS8 system disk to /sysroot and find the partition mount corresponding to CentOS8. As shown below:
then exit and the system starts normally! Fortunately, it’s not a big problem.
come in the system, think under the analysis of the cause, to fundamentally solve it…
open the log file rdsosreport.txt in the U disk, find the error fragment log analysis:
[ 79.300190] xxx systemd[1]: Reached target Switch Root.[ 79.300600] xxx systemd[1]: Starting Switch Root...[ 79.304948] xxx systemctl[2113]: Failed to switch root: Specified switch root path '/sysroot' does not seem to be an OS tree. os-release file is missing.[ 79.305456] xxx systemd[1]: initrd-switch-root.service: Main process exited, code=exited, status=1/FAILURE[ 79.305593] xxx systemd[1]: initrd-switch-root.service: Failed with result 'exit-code'.[ 79.305789] xxx systemd[1]: Failed to start Switch Root.[ 79.305811] xxx systemd[1]: initrd-switch-root.service: Triggering OnFailure= dependencies.[ 79.306342] xxx systemd[1]: Starting Setup Virtual Console...[ 79.364641] xxx systemd[1]: Started Setup Virtual Console.[ 79.365205] xxx systemd[1]: Started Emergency Shell.[ 79.365348] xxx systemd[1]: Reached target Emergency Mode.[ 79.380910] xxx systemd[1]: Received SIGRTMIN+21 from PID 1675 (plymouthd).
see the key record:
Failed to switch root: Specified switch root path '/sysroot' does not seem to be an OS tree. os-release file is missing.
because the root path was not mounted successfully, /sysroot had no content, and the os-release file was not found.
, can you imagine if the os-release file for the system is gone?Open the /etc/cenos-release file and find the content, that’s not the problem with this file!
to calmly analyze problems, to learn to analyze and solve problems, this ability is very important.
systematically study, master the knowledge of a field is very necessary. The idea and process of solving the problem depends on your understanding of the system!
note: this article is original and shall not be reproduced on any platform without permission. For reprint, contact the author ~
Introduction: there are many problems about hosts on the Internet. After testing, I found out that it is not. After testing by myself, I introduced three solutions to most problems:
1. Firewall port not opened or closed
firewall generally local test will be closed, the line is generally open, it is recommended to add port
#开启防火墙 service firewalld start
#启用防火墙 service firewalld enable(永久生效)#关闭防火墙 service firewalld stop (重启后失效)
#禁用防火墙 service firewalld disable (永久生效)#重启防火墙 service firewalld restart
#查看状态 service firewalld status
2. Kafka service entry address not specified
edit the server.properties in the config directory of kafka, and add the address of the service entry to the external service:
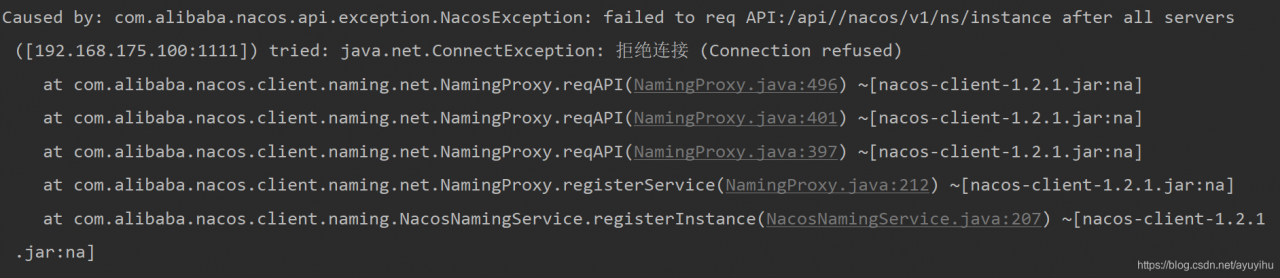
service registry to nacos error: com. Alibaba. Nacos. API. Exception. NacosException: failed to the req API:/API// nacos/v1/ns/instance after all the servers ([192.168.175.100:1111]) tried: java.net.ConnectException: Refuse a Connection (Connection union)
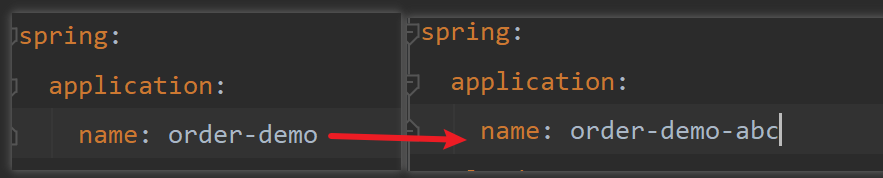
after looking for a long time without finding the reason, it turns out that as long as you modify spring.application.name, it can be restored to normal: so that it can start normally, which is very strange.
sometimes stops the service, restarts it and can’t be registered, and then changes the service name again.
each three lines defines a route ADDRESS0=TARGET NETMASK0=MASK GATEWAY0=GW
Blockquote>
route command
route add -net 192.168.235.0 netmask 255.255.255.0 gw 192.168.235.2 dev ens33
IP command
ip route add 192.168.80.0/24 via 192.168.80.2 dev ens33 # 添加网络路由
ip route add 192.168.80.100 via 192.168.80.0 dev ens33 #添加主机路由
ip route add default via 192.168.80.2 dev ens33 # 添加默认路由
modify routing
modify the configuration file
/etc/sysconfig/network-scripts/route-ens33
The
way
target via gw 220.181.38.148 via 192.168.80.2
each three lines defines a route ADDRESS0=TARGET NETMASK0=MASK GATEWAY0=GW
Blockquote>
IP command
ip route change # 如果路由本身不存在则报错显示不存在
ip route replace # 如果路由本身不存在则会直接创建该路由信息
delete route
delete the configuration file
/etc/sysconfig/network-scripts/route-ens33
the route command
route del -net 192.168.235.0 netmask 255.255.255.0 gw 192.168.235.2 dev ens33
IP command
ip route del 192.168.80.0/24 via 192.168.80.2 dev ens33

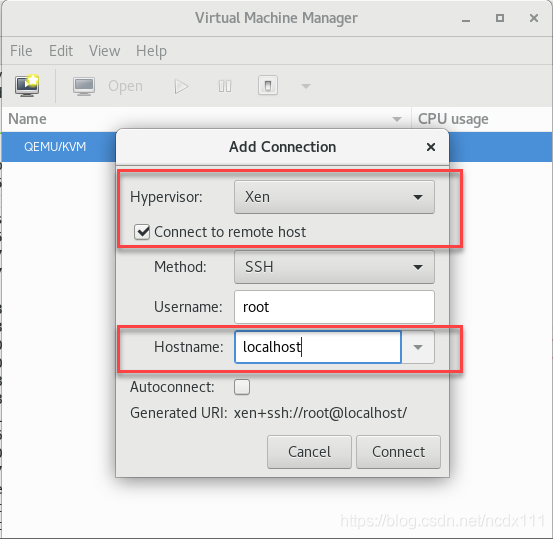 create virtual machine, right click
create virtual machine, right click 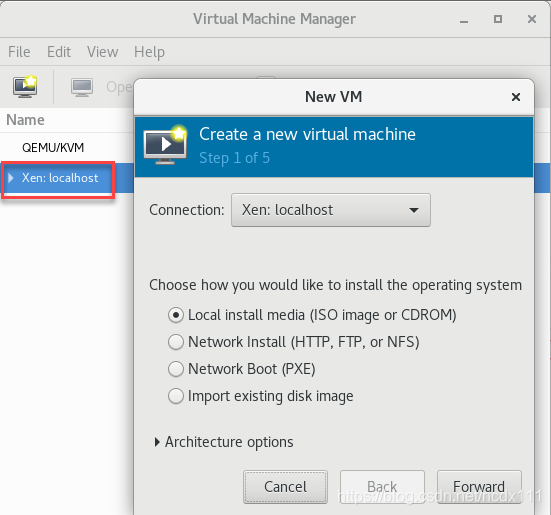 input
input 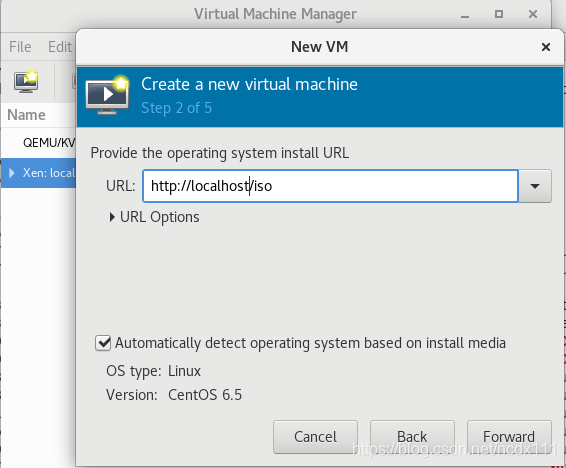 select the virtual machine memory and CPU configuration, the image installed in this paper is centos6.5-minnal version
select the virtual machine memory and CPU configuration, the image installed in this paper is centos6.5-minnal version 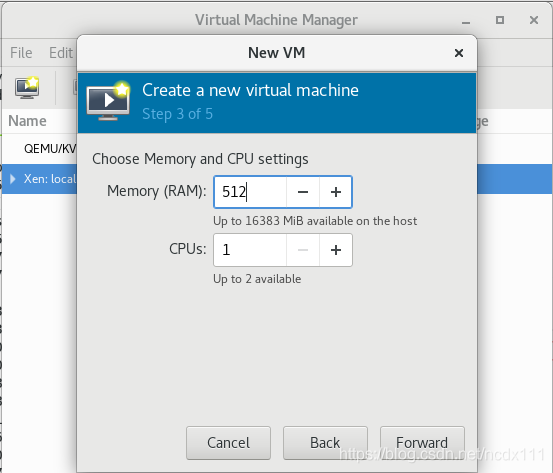 select the virtual machine disk size
select the virtual machine disk size 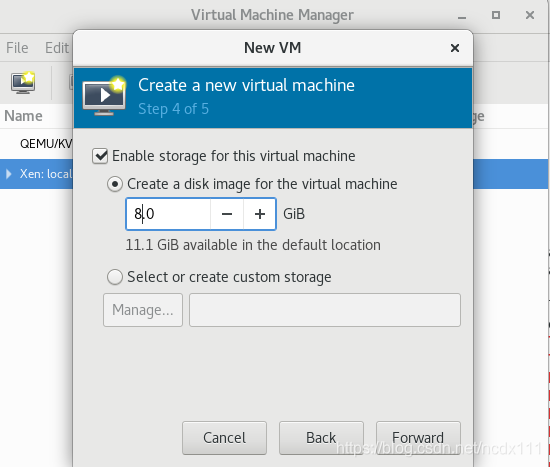 confirm the installation information (including the selection of Network configuration, whether to customize the configuration information), Check the first red box in the figure below if there is a custom requirement.
confirm the installation information (including the selection of Network configuration, whether to customize the configuration information), Check the first red box in the figure below if there is a custom requirement. 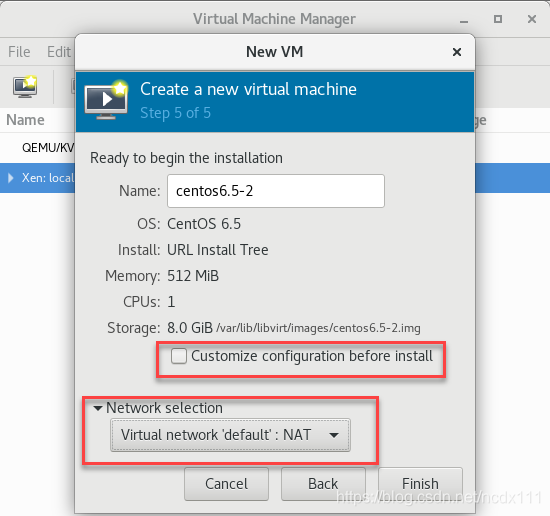 click
click 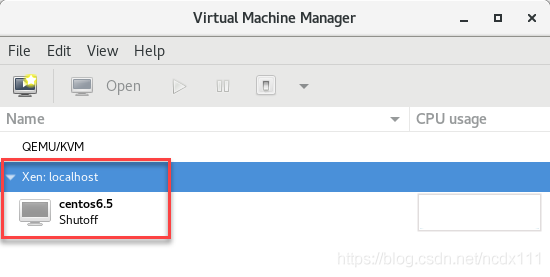 can be viewed through the virt-manager to enter the virtual machine command line by entering the following command
can be viewed through the virt-manager to enter the virtual machine command line by entering the following command