I recently tried to use Elasticsearch and IK in combination with Logstash to link mysql, and tested Logstash with the following error message.
First enter the command: logstash -e ‘input {stdin{}} output {stdout{}}’
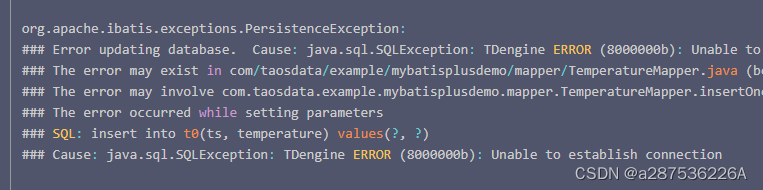
D:\myworkspace\es\logstash-6.4.3\bin>logstash -e 'input {stdin{}} output {stdout{}}'The command is correct, but the result is:
D:\myworkspace\es\logstash-6.4.3\bin>logstash -e 'input {stdin{}} output {stdout{}}'
ERROR: Unknown command '{stdin{}}'
See: 'bin/logstash --help'
[ERROR] 2022-08-23 09:06:42.875 [main] Logstash - java.lang.IllegalStateException: Logstash stopped processing because of an error: (SystemExit) exit
Solution:
You should try the following command first:
logstash -e “”
The result was successful:
D:\myworkspace\es\logstash-6.4.3\bin>logstash -e ""
Sending Logstash logs to D:/myworkspace/es/logstash-6.4.3/logs which is now configured via log4j2.properties
[2022-08-23T09:16:16,950][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"D:/myworkspace/es/logstash-6.4.3/data/queue"}
[2022-08-23T09:16:16,958][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"D:/myworkspace/es/logstash-6.4.3/data/dead_letter_queue"}
[2022-08-23T09:16:17,054][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2022-08-23T09:16:17,164][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"0777ac0f-9efb-463d-8e2c-874bc1dc9feb", :path=>"D:/myworkspace/es/logstash-6.4.3/data/uuid"}
[2022-08-23T09:16:17,592][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.4.3"}
[2022-08-23T09:16:20,129][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2022-08-23T09:16:20,231][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x5fba80a0 run>"}
The stdin plugin is now waiting for input:
[2022-08-23T09:16:20,277][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2022-08-23T09:16:20,611][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2022-08-23T09:16:43,203][WARN ][logstash.runner ] SIGINT received. Shutting down.
[2022-08-23T09:16:43,338][INFO ][logstash.pipeline ] Pipeline has terminated {:pipeline_id=>"main", :thread=>"#<Thread:0x5fba80a0 run>"}
[2022-08-23T09:16:43,340][FATAL][logstash.runner ] SIGINT received. Terminating immediately.Decisively replace with the following command:
logstash -e "input { stdin {} } output {stdout {} }"Done!
D:\myworkspace\es\logstash-6.4.3\bin>logstash -e "input { stdin {} } output {stdout {} }"
Sending Logstash logs to D:/myworkspace/es/logstash-6.4.3/logs which is now configured via log4j2.properties
[2022-08-23T09:17:48,125][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2022-08-23T09:17:48,690][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.4.3"}
[2022-08-23T09:17:50,871][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2022-08-23T09:17:50,964][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x268e4bb5 run>"}
The stdin plugin is now waiting for input:
[2022-08-23T09:17:51,008][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2022-08-23T09:17:51,209][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}