The solution to this problem eventually returns to the problem of version synchronization

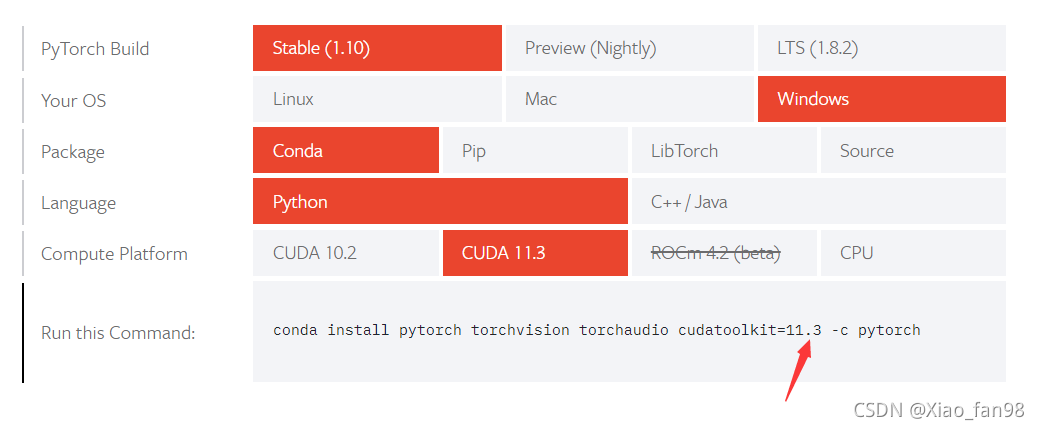 The versions at the two arrows should be consistent.
The versions at the two arrows should be consistent.
The solution to this problem eventually returns to the problem of version synchronization
The versions at the two arrows should be consistent.
Many odoo users have encountered the problem that the backed up database cannot be restored
You can self-check in the following ways
1. Is the odoo version correct? Different versions of odoo cannot be restored directly, for example, odoo13 cannot be restored directly to odoo15
2. Whether the database version is correct, postgres may have problems when it is backward compatible. It is recommended to migrate to the same version.
3. Whether the code is migrated correctly, inconsistent codes on both sides will also cause an error, which is common in the conf file without specifying the code location.
If you confirm that the above content is correct, you can try the following methods
1. Add -d database name -i base when starting odoo through the command line, this method is to select the database to force the update of the base module; because all odoo modules are dependent on this, the mandatory update will be all the modules installed in the database after the base Will be upgraded.
2. Enter postgres, enter the following command
su postgres; # Switch postgres users
psql; # Enter the postgres command line
\c; database name # specify database instance
DELETE FROM ir_attachment WHERE url LIKE '/web/content/%'; # Delete the front-end files cached in the data tableGenerally, most problems can be solved through the above two steps.
conda report errorCollecting package metadata
Error detailed
Collecting package metadata (current_repodata.json): failed
CondaHTTPError: HTTP 000 CONNECTION FAILED for urlhttps://repo.anaconda.com/pkgs/main/win-64/current_repodata.json Elapsed: –
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent,
If your current network hashttps://www.anaconda.com Blocked, please file a support request with your network engineering team.
‘https://repo.anaconda.com/pkgs/main/win-64’
Solution:
Put the C:\ProgramData\Anaconda3\Library\bin directory under the
(or install in its disk, ProgramData folder is hidden by default status)
libcrypto-1_1-x64.*
libssl-1_1-x64.*
A total of four files
Copy and paste them into the C:\ProgramData\Anaconda3\DLLs directory to solve the problem.
Error:
import cv2
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
Solution:
pip install opencv-python pip install opencv-python-headless
Usually the red report after import is because there is no module, use pip install cv2 to download the module, it will appear:
Could not find a version that satisfies the requirement cv2 (from versions: )
No matching distribution found for cv2
You are using pip version 18.1, however version 19.0.2 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
At this point you need to type python -m pip install –upgrade pip
When the installation is complete, run this line “pip install opencv-python”, this line is to install the cv2 module, wait until the download is complete
To install the numpy module, you only need to pip install numpy
The summary is as follows:
python -m pip install --upgrade pip
pip install opencv-python
pip install numpypip3 install –upgrade pip3 execution error after pip upgrade
Description
Traceback (most recent call last):
File “/home/brian/.local/bin/pip3”, line 7, in
from pip._internal.cli.main import main
File “/home/brian/.local/lib/python3.5/site-packages/pip/_internal/cli/main.py”, line 60
sys.stderr.write(f”ERROR: {exc}”)
^
SyntaxError: invalid syntax
Solution
Execute python3 –version to determine the python3 version visit https://bootstrap.pypa.io/pip/ Find the get-pip.py file for the corresponding python version at this URL and execute wget in the terminal https://bootstrap.pypa.io/pip/3.8/get-pip.pypython3 get-pip.py
Error no module “Tkinter”
Principle:
Import Tkinter in python3 import Tkinter in python2
It’s just the difference in the case of the beginning in the python version.
Therefore, we can modify the startup version of Python. One is to directly modify the system version, and the other is to modify the specified version of Python file
here we mainly talk about how to modify the specified version of Python files.
Add the following two lines at the beginning of the .Py file:
#! /usr/bin/python2.7
# -*- coding utf-8 -*-QGIS installation paddy GPU error
Error content
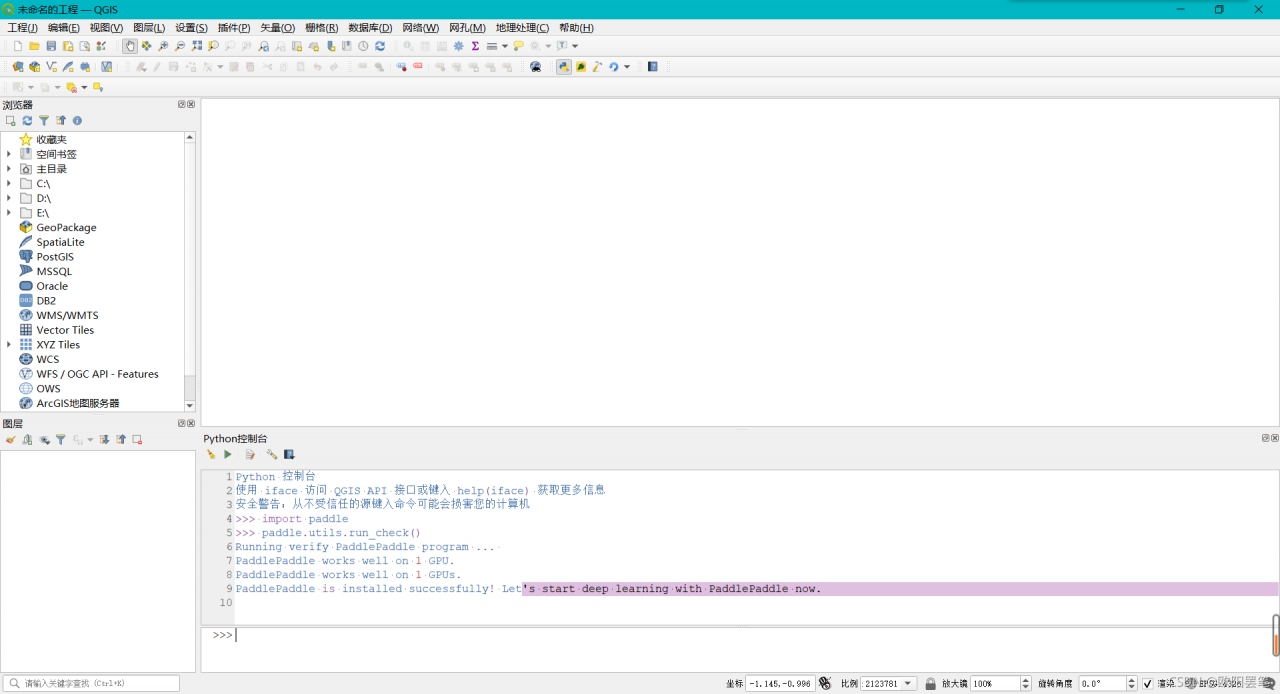
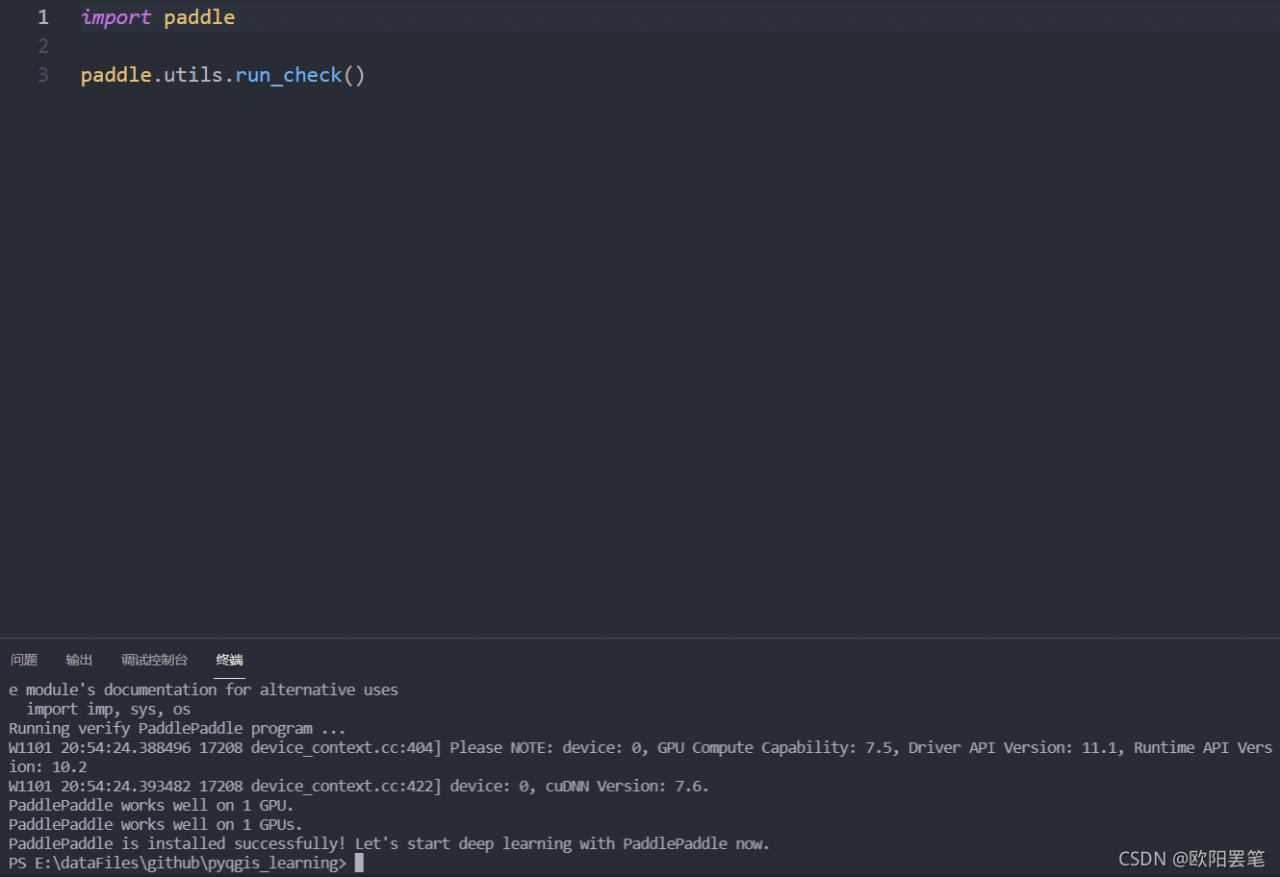
Use the following code to check whether the paddle GPU is installed successfully
import paddle
paddle.utils.run_check()Get the following error reports
RuntimeError: (PreconditionNotMet) The third-party dynamic library (cublas64_102.dll;cublas64_10.dll) that Paddle depends on is not configured correctly. (error code is 126)
Suggestions:
1. Check if the third-party dynamic library (e.g. CUDA, CUDNN) is installed correctly and its version is matched with paddlepaddle you installed.
2. Configure third-party dynamic library environment variables as follows:
- Linux: set LD_LIBRARY_PATH by `export LD_LIBRARY_PATH=...`
- Windows: set PATH by `set PATH=XXX; (at C:\home\workspace\Paddle_release\paddle\fluid\platform\dynload\dynamic_loader.cc:265)It is found that other CONDA environments can be used normally, CUDA installation and environment variable configuration are correct, and the environment variable is checked in QGIS. It is found that there is no C: \program files\NVIDIA GPU computing toolkit\CUDA\v10.2\bin in path.
Solution:
For the desktop, you can add C:\program files\NVIDIA GPU computing toolkit\CUDA\v10.2\bin
 after the path in QGIS\bin\qgis-ltr-bin.env. For plug-ins developed in vscode, you can add o4w in the same folder, Change set path to
after the path in QGIS\bin\qgis-ltr-bin.env. For plug-ins developed in vscode, you can add o4w in the same folder, Change set path to set path =% osgeo4w in env.bat_ROOT%\bin;% WINDIR%\system32;% WINDIR%;% WINDIR%\system32\WBem;% CUDA_BIN_PATH%
Use the command easy_ Install install pip
Use the command sudo easy_Install PIP installing PIP failed. The information of executing the command is as follows:
➜ ~ sudo easy_install pip
Password:
Searching for pip
Reading https://pypi.org/simple/pip/
Downloading https://files.pythonhosted.org/packages/da/f6/c83229dcc3635cdeb51874184241a9508ada15d8baa337a41093fab58011/pip-21.3.1.tar.gz#sha256=fd11ba3d0fdb4c07fbc5ecbba0b1b719809420f25038f8ee3cd913d3faa3033a
Best match: pip 21.3.1
Processing pip-21.3.1.tar.gz
Writing /tmp/easy_install-8XXfb1/pip-21.3.1/setup.cfg
Running pip-21.3.1/setup.py -q bdist_egg --dist-dir /tmp/easy_install-8XXfb1/pip-21.3.1/egg-dist-tmp-5cqtMF
Traceback (most recent call last):
# ...
File "/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/setuptools/sandbox.py", line 44, in _execfile
code = compile(script, filename, 'exec')
File "/tmp/easy_install-8XXfb1/pip-21.3.1/setup.py", line 7
def read(rel_path: str) -> str:
^
SyntaxError: invalid syntaxSolution
Download the script file get-pip.py:
curl 'https://bootstrap.pypa.io/get-pip.py' > get-pip.pyThen execute the script file get-pip.py with the command python3:
sudo python3 get-pip.pyThis completes the installation.
The process information of executing the command is as follows:
➜ ~ curl 'https://bootstrap.pypa.io/get-pip.py' > get-pip.py
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2108k 100 2108k 0 0 2571k 0 --:--:-- --:--:-- --:--:-- 2568k
➜ ~ sudo python3 get-pip.py
Password:
WARNING: The directory '/Users/liaowenxiong/Library/Caches/pip' or its parent directory is not owned or is not writable by the current user. The cache has been disabled. Check the permissions and owner of that directory. If executing pip with sudo, you should use sudo's -H flag.
DEPRECATION: Configuring installation scheme with distutils config files is deprecated and will no longer work in the near future. If you are using a Homebrew or Linuxbrew Python, please see discussion at https://github.com/Homebrew/homebrew-core/issues/76621
Collecting pip
Downloading pip-21.3.1-py3-none-any.whl (1.7 MB)
|████████████████████████████████| 1.7 MB 1.0 MB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 21.2.4
Uninstalling pip-21.2.4:
Successfully uninstalled pip-21.2.4
DEPRECATION: Configuring installation scheme with distutils config files is deprecated and will no longer work in the near future. If you are using a Homebrew or Linuxbrew Python, please see discussion at https://github.com/Homebrew/homebrew-core/issues/76621
Successfully installed pip-21.3.1
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
➜ ~ pip --version
pip 21.3.1 from /usr/local/lib/python3.9/site-packages/pip (python 3.9)A simpler command to execute is as follows:
curl https://bootstrap.pypa.io/get-pip.py | python3Uninstall pip
sudo pip uninstall pip 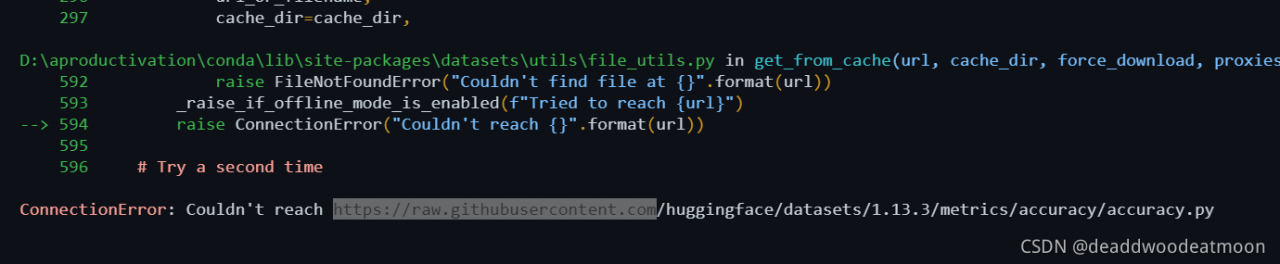
1. Log in to the website and enter raw.githubusercontent.com to query IPv4 address
2. Find the windows directory C:/Windows/systen32/Drives/etc/hosts file, open with Notepad:
3. Add last line 185.199.108.133 raw.githubusercontent.com
4. After saving and exiting, the operation does not report an error
pytorch error: RuntimeError: value cannot be converted to type float without overflow: (0.00655336,-0.00…
Solution:
initialize network layers such as conv2d.
# Default Method
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.xavier_uniform_(m.weight)ParserError: NULL byte detected. This byte cannot be processed in Python’s native csv library at the moment, so please pass in engine=’c’ instead
Error:
file_name = os.listdir(base_dir)[0]
col_list = [feature list]
col = col_list
#encoding
#data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding="GBK",usecols=range(len(col)))
data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'unicode_escape', engine ='python')
#data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'utf-8', engine ='python')
path = "D:\\test\\repo\\data.csv"Solution:
engine =’c’
file_name = os.listdir(base_dir)[0]
#encoding
#data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding="GBK",usecols=range(len(col)))
data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'unicode_escape', engine ='c')
#data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'utf-8', engine ='python')
path = "D:\\test\\repo\\data.csv"Full Error Messages:
—————————————————————————
Error Traceback (most recent call last) D:\anaconda\lib\site-packages\pandas\io\parsers.py in _next_iter_line(self, row_num) 2967 assert self.data is not None -> 2968 return next(self.data) 2969 except csv.Error as e: Error: line contains NULL byte During handling of the above exception, another exception occurred: ParserError Traceback (most recent call last) <ipython-input-12-c5d0c651c50e> in <module> 85 ] 86 ---> 87 data = inference_process(data_dir) 88 #print(data.head()) 89 f=open("break_model1.pkl",'rb') <ipython-input-12-c5d0c651c50e> in inference_process(base_dir) 18 #encoding 19 # data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding="GBK",usecols=range(len(col))) ---> 20 data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'unicode_escape', engine ='python') 21 # data = pd.read_csv("D:\\test\\repo\\data.csv",sep = ',',encoding = 'utf-8', engine ='python') 22 D:\anaconda\lib\site-packages\pandas\io\parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options) 608 kwds.update(kwds_defaults) 609 --> 610 return _read(filepath_or_buffer, kwds) 611 612 D:\anaconda\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds) 460 461 # Create the parser. --> 462 parser = TextFileReader(filepath_or_buffer, **kwds) 463 464 if chunksize or iterator: D:\anaconda\lib\site-packages\pandas\io\parsers.py in __init__(self, f, engine, **kwds) 817 self.options["has_index_names"] = kwds["has_index_names"] 818 --> 819 self._engine = self._make_engine(self.engine) 820 821 def close(self): D:\anaconda\lib\site-packages\pandas\io\parsers.py in _make_engine(self, engine) 1048 ) 1049 # error: Too many arguments for "ParserBase" -> 1050 return mapping[engine](self.f, **self.options) # type: ignore[call-arg] 1051 1052 def _failover_to_python(self): D:\anaconda\lib\site-packages\pandas\io\parsers.py in __init__(self, f, **kwds) 2308 self.num_original_columns, 2309 self.unnamed_cols, -> 2310 ) = self._infer_columns() 2311 except (TypeError, ValueError): 2312 self.close() D:\anaconda\lib\site-packages\pandas\io\parsers.py in _infer_columns(self) 2615 for level, hr in enumerate(header): 2616 try: -> 2617 line = self._buffered_line() 2618 2619 while self.line_pos <= hr: D:\anaconda\lib\site-packages\pandas\io\parsers.py in _buffered_line(self) 2809 return self.buf[0] 2810 else: -> 2811 return self._next_line() 2812 2813 def _check_for_bom(self, first_row): D:\anaconda\lib\site-packages\pandas\io\parsers.py in _next_line(self) 2906 2907 while True: -> 2908 orig_line = self._next_iter_line(row_num=self.pos + 1) 2909 self.pos += 1 2910 D:\anaconda\lib\site-packages\pandas\io\parsers.py in _next_iter_line(self, row_num) 2989 msg += ". " + reason 2990 -> 2991 self._alert_malformed(msg, row_num) 2992 return None 2993 D:\anaconda\lib\site-packages\pandas\io\parsers.py in _alert_malformed(self, msg, row_num) 2946 """ 2947 if self.error_bad_lines: -> 2948 raise ParserError(msg) 2949 elif self.warn_bad_lines: 2950 base = f"Skipping line {row_num}: " ParserError: NULL byte detected. This byte cannot be processed in Python's native csv library at the moment, so please pass in engine='c' instea