webstorm create react project pull data
project right click –> Open in terminal and then type the following command in the terminal
set up taobao image of acceleration: NPM config set registry https://registry.npm.taobao.org
check whether the setting is successful: NPM config get registry
details are as follows:
Microsoft Windows [版本 10.0.17763.615]
(c) 2018 Microsoft Corporation。保留所有权利。
H:\Project\React app\untitled3>npm config set registry https://registry.npm.taobao.org
H:\Project\React app\untitled3>npm config get registry
https://registry.npm.taobao.org/
H:\Project\React app\untitled3>
Failed to set up listener: socketexception: address already in use
error log
2018-06-08T22:25:09.118+0800 E STORAGE [initandlisten] Failed to set up listener: SocketException: Address already in use
2018-06-08T22:25:09.118+0800 I CONTROL [initandlisten] now exiting
2018-06-08T22:25:09.118+0800 I CONTROL [initandlisten] shutting down with code:48error cause
error, error log has been clear, ‘Address already in use’ has a process has been running in the port. So we’re going to find this process and turn it off.
PID(Process Identification) operating system refers to the Process Identification number. Each time the operating system opens a program, it creates a process ID, or PID. Each process has a unique PID number, which is assigned by the process runtime system and does not represent a dedicated process. The PID does not change the identifier at run time, but after the process terminates the PID identifier is retrieved by the system and may be assigned to the newly run program.
solution
find the PID number that was run before mongo, turn it off, and re-enter the start command
songrenqingdeMacBook-Pro:bin songrenqing$ lsof -i :27017
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mongod 61316 songrenqing 11u IPv4 0xacda8b230bc07883 0t0 TCP localhost:27017 (LISTEN)
songrenqingdeMacBook-Pro:bin songrenqing$ kill -9 61316
or use another process ID, previously 27017, now specify 27018, so there will be no conflict
mongod --port 27018
songrenqingdeMacBook-Pro:bin songrenqing$ lsof -i :27017
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mongod 61316 songrenqing 11u IPv4 0xacda8b230bc07883 0t0 TCP localhost:27017 (LISTEN)
songrenqingdeMacBook-Pro:bin songrenqing$ kill -9 61316mongod --port 27018Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
error when installing apk to the phone via adb install -r :
Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
reason:
ndk {
abiFilters "armeabi-v7a"
// abiFilters "x86"
}
:
due to install the APP using the native libraries with the current CPU architecture do not agree, so lead to an error, because the vast majority of smartphones are now using the ARM architecture, while android is support ARM and x86 architecture, but the instruction set is distinct, the APP is used when development ARM of the local library, and we were using the AVD is used when creating the simulator x86 CPU, thus result in an error. So, if the APP is compiled in an x86 architecture we create an emulator for x86CPU, and if the APP is compiled in an ARM architecture we create an emulator for ARMcpu.
is the NDK selected by the packaged apk generation is not compatible with the NDK of the mobile phone system. As long as the NDK type is modified and repackaged,
is ok
Process of checking the error of connection reset by peer reported by reactor netty
article directory
- 1. An error phenomenon
- 2. Screening process
-
-
- 2.1 Connection reset by peer reason
- 2.2 the syscall: read (..) Failed: Connection reset by peer error
-
- 3. Final cause
1. Error reporting
A service in
group switched from spring-webmvc framework to spring-webflux. After running online for some time, the following error log occasionally appeared. L:/10.0.168.212:8805 represents the server IP and port where the local service is located. R:/10.0.168.38:47362 represents the server IP and port where the requested service is located. The common reason for this situation is that the server is busy, while checking the monitoring of the service invocation, it is found that the normal invocation amount is not enough to constitute the condition of service busy
2020-05-110 10:35:38.462 ERROR reactor-http-epoll-1 [] reactor.netty.tcp.TcpServer.error(300) - [id: 0x230261ae, L:/10.0.168.212:8805 - R:/10.0.168.38:47362] onUncaughtException(SimpleConnection{channel=[id: 0x230261ae, L:/10.0.168.212:8805 - R:/10.0.168.38:47362]})
io.netty.channel.unix.Errors$NativeIoException: syscall:read(..) failed: Connection reset by peer
at io.netty.channel.unix.FileDescriptor.readAddress(..)(Unknown Source)
2. Screening
2.1 Connection reset by peer
The
error is rarely encountered. The first thing that comes to mind is, of course, searching for the wrong keyword on the Internet and finding the following. It is clear that Connection reset by peer is caused by the server transmitting data to the opposite Socket Connection closed, but the reason for closing the Connection to the opposite end is unknown
| abnormal reason | |||||||||
|---|---|---|---|---|---|---|---|---|---|
java.net.BindException:Address already in use: JVM_Bind |
this exception occurs when the server side is operating new ServerSocket(port), because the port has been started and is listening. At this point with the netstat - an command, you can see the local has been in the use of state of the port, you just need to find a not occupied ports can solve the problem
|
will be thrown
2.2 the syscall: read (...). Failed: Connection reset by peer error
continues searching for other keywords and then goes around and finds the issue of reactor-netty on github. github posted by other developers is almost exactly the same as what I encountered. After careful reading, I found that other developers encountered this problem mainly in the following two ways:
- disabled long connections
- modify the load balancing strategy to the minimum number of connections strategy
From the perspective of comment, this is mainly involved in the connection pooling mechanism of reactor-netty. We know that netty is a framework based on nio (see the Java IO model and examples), which USES a connection pool to ensure concurrent throughput when handling connection requests. By customizing the ClientHttpConnector with a long connection attribute of false, the connection pool thread is guaranteed not to be held for long periods of time, which seems to be an effective solution for this error
in scenarios used by other developers
3. Final cause
check the comment on github, I always feel that the scene of other developers is not exactly the same as ours, but I have no idea for the moment. The leader shouted in the internal group. In the evening, a colleague finally found the clue from the log.
>
>
>
>
>
>
>
- connection pool allocates threads
reactor-http-epoll-1to process A request A. During the processing ofreactor-http-epoll-1, due to the slow SQL blocking all the time, the same interface was accessed with high frequency during this period, and other threads in the connection pool were also allocated to process the same type of request. Then it also blocks because of slow SQL. in the connection pool threads are blocked, a new request to come over, connection pool has no thread can carries on the processing, therefore has been hold request end, closed until after the timeout active Socket . After that, the server Connection pool thread finally finished processing the slow SQL request, and then processed the backlog of requests. When it finished, it sent the data to the request side, only to find that the Connection had been closed, so the errorConnection reset by peerwas reported. As a rule of thumb, if the service reports a Connection reset by peer error, first check to see if there is a particularly slow action in the service blocking the thread
analysis of slow SQL found that the reason why the statement took so Long to execute was that the MySQL database field of data type VARCAHR accepted the condition of Long data type, resulting in implicit type conversion, unable to use the index, and thus triggering the full table scan.
On the problem of NAC signature error when switch installs the game
is an error because the installed game has been modified or converted from xci to install the latest tinfoil that resolves
steps:
1. Download tinfoil. IO from tinfoil.nro and put it in the switch directory;
2. Install any game that can be installed in the switch, then press r to enter the game
3. Open tinfoil and open “install unsigned code” in option, which requires the password
up up down down left right left right B A +
is up, down, left, right, BA+
Error: pngquant failed to build, make sure that libpng-dev is installed
1, describe
execute NPM install on the window, reporting the following error
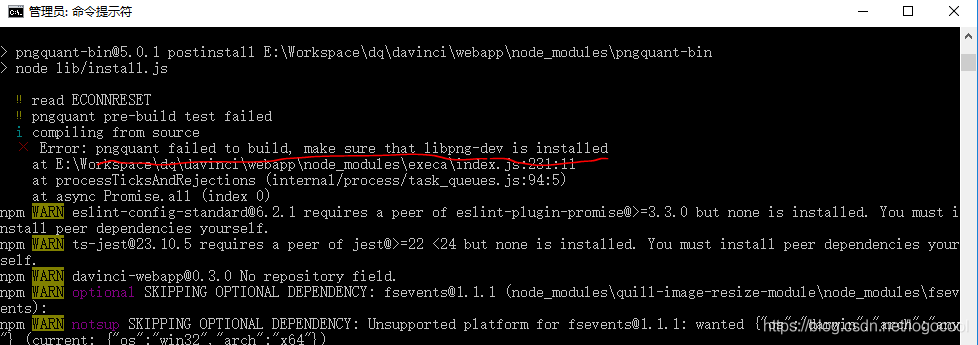
second, the solution
on Windows, use the NPM install -g windows-build-tools command . Note that run
with the administrator identity
PySpark ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
after terminal input PySpark, the following error occurs:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable C:\ hadox-3.1.2 \bin\winutils. Exe in the hadoop binaries.

problem analysis: the winutils.exe file is missing in the hadoop/bin folder.
solution:
1. Check the hadoop/bin folder, and find that there is really no winutils.exe file.
my Hadoop version is 3.1.2 binary, downloaded from the website: https://hadoop.apache.org/releases.html.
2, download the file winutils.exe. Download address is https://github.com/steveloughran/winutils.
my Hadoop version is 3.1.2. Select the file winutils. Exe in hadoop-3.0.0/bin in the webpage and download it and put it into the Hadoop /bin folder.
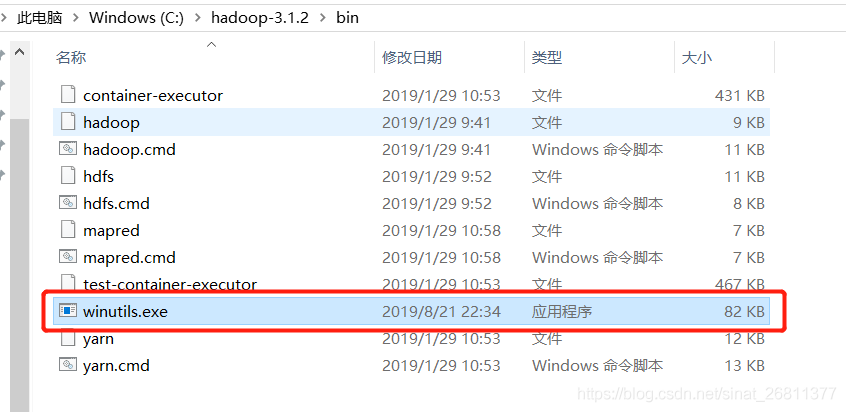
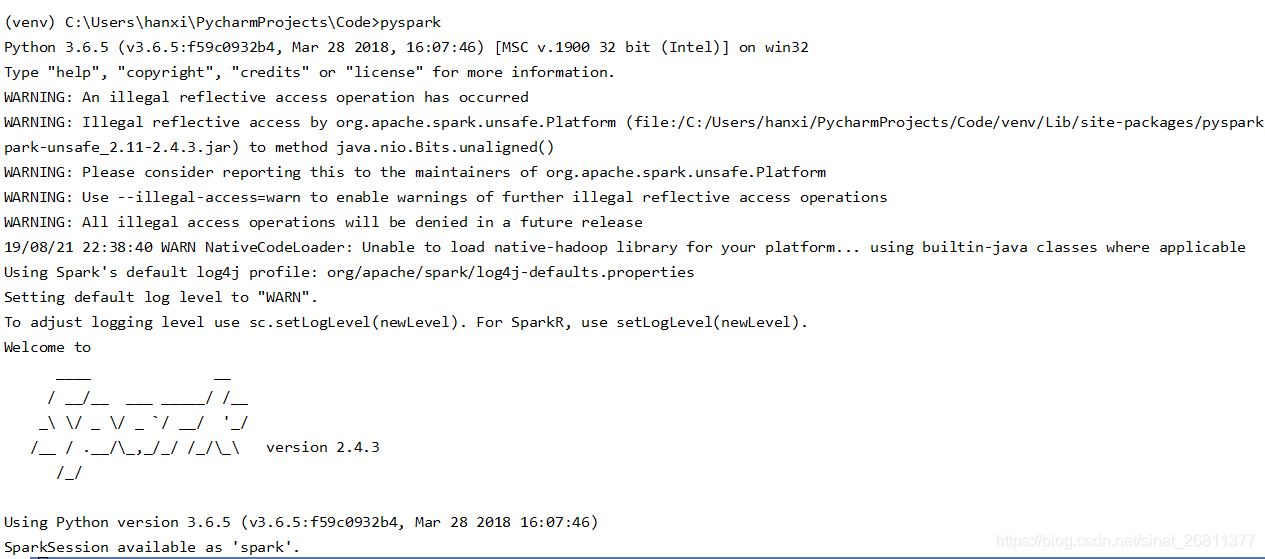
3, re-enter pyspark on the terminal. Success!
Notes on unity project_ Unity webplayer failed to update unity web player
after unity packages webplayer, four files
will be generated

opens the.html file in the following position
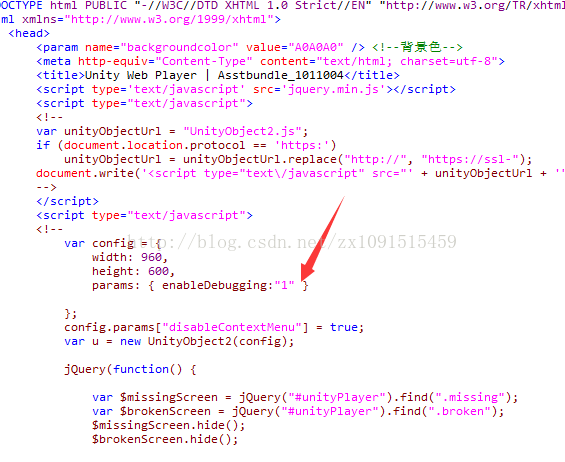
inserts the following code
baseDownloadUrl: "http://wp-china.unity3d.com/download_webplayer-3.x/",
autoupdateURL : "http://wp-china.unity3d.com/autodownload_webplugin-3.x",
autoupdateURLSignature : "02a5f78b3066d7d31fb063186a2eec36fdf1205d49c6b0808eb37ef85ed9902e2e1904d87f599238a802ba0abbfe4f18aa82dd2eb5171e99ba839a5cea9e6ea9c1be9eae505937b56fe4a5fd254cffe08958d961f42d970136b5eab9e6c2cd08b81bc8a11e5ade57dc63dcfef2248d89689e4d4feed3cdfe7374c848fd57ebd4"
is what this code does to let webplayer download
ChinaCache latest version, cause:
Unity works with ChinaCache :CDN acceleration plug-in download
Ansible Failed – apt lock
Environment
- On Ubuntu 16.04/Ubuntu 14.04
- Ansible 2.3.2.0
updateApt.yml
- name: APT Update
hosts: webservers
become: True
tasks:
- name: Update apt
apt:
update_cache: yes错误:
fatal: [testserver2]: FAILED! => {"changed": false, "failed": true, "msg": "Failed to lock apt for exclusive operation"}- name: APT Update
hosts: webservers
become: True
tasks:
- name: Update apt
apt:
update_cache: yes
cache_valid_time: 3600
,并在目标机上执行此操作
sudo apt-get clean
sudo apt-get update这为我解决了它,运行它在目标机器上
Solution to “550 create directory operation failed” in FTP operation file
in etc/vsftpd.conf, modify,
anonymous_enable=NO
local_enable=YES
write_enable=YES
chroot_local_user=NO
chroot_list_enable=NO
listen=YES
listen_port=21
local_root=/
to
E667: Fsync failed
edit file /proc/sys/kernel/core_pattern by vim, save E667: Fsync failed
echo “core-%e-%p-%t” | sudo dd of=/proc/sys/kernel/core_pattern
reference: https://askubuntu.com/questions/167819/im-getting-fsync-failed-error-why
Failure: waiting for status update. MMC read failed
configuration :
scp-2G/16G
question :
previously installed message is the provided qte4.7 system, the system runs normally, but recently need to install qt5.7 version, found that message is provided with a good image, use otg way to burn, the first time successful, but the second time burning prompted “FAIL: waiting for status update.mmc read failed”, so repartition, error “FAIL again: Waiting for status update. MMC read failed “, suspected that uboot burned down, then burned it through TF card, and when partitioning emmc through TF uboot, it was prompted with “FAIL: waiting for status update. MMC read failed”, and the system printing information showed that the emmc capacity was only 1G (normally 16G), suspected that the core flash was broken
solution :
did not find a solution on the Internet, and went to find the official document, in a document to introduce EMMC stressed that pop, scp-1g and scp-2g uboot is different, see here suddenly realized, check the use of uboot, is indeed the version of scp-1g, and then replace the scp-2g uboot, through TF card partition and burned successfully.