Problem Description:
After installing Anaconda 3, open the Jupiter notebook to create a new one. When you click Python 3, the kernel error is always displayed. It has been tried several times. I believe many people have such a problem. No matter uninstalling and reloading Anaconda or rebuilding an environment, it has not been solved. Until later, it was found that the nuclear was not cleaned up. Here I share a solution to this problem. Successfully solved my problem.
solve:
1. Open the anaconda prompt window and enter Jupiter kernelspec list to see the location of the current kernel. Note that this is the wrong kernel, 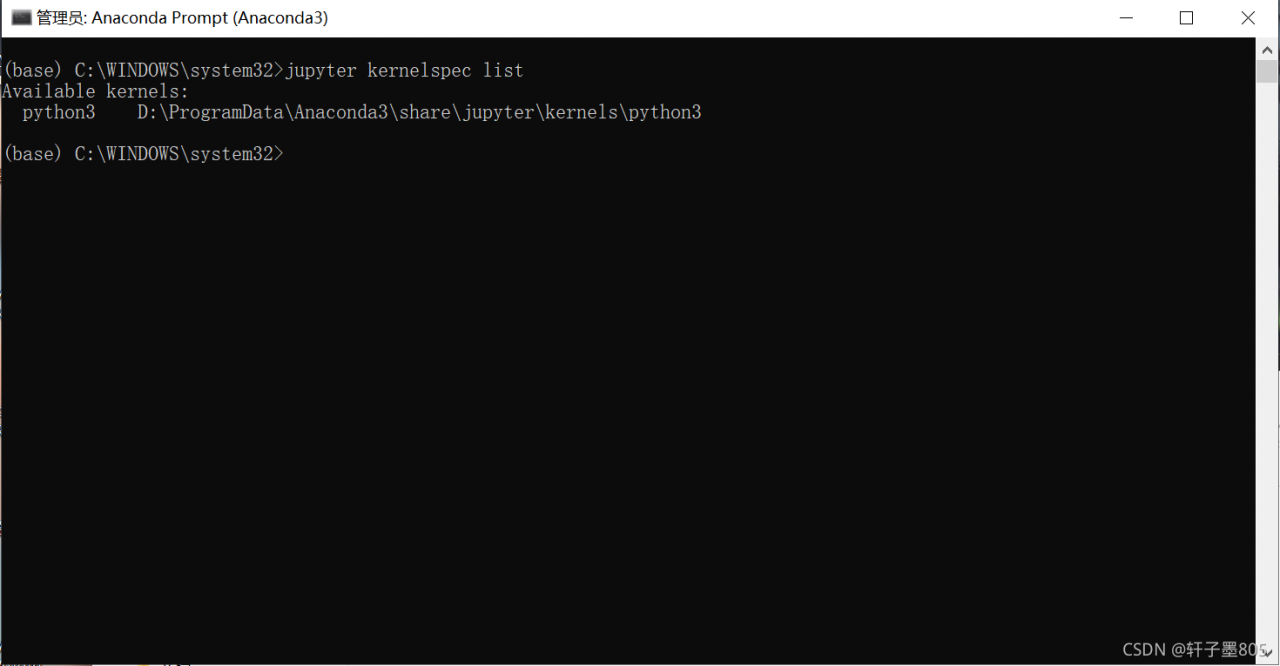
2. Copy this address and uninstall the current anaconda
3. Find the address just now and delete the jupyter folder
4. Reinstall Anaconda
It can be solved!!