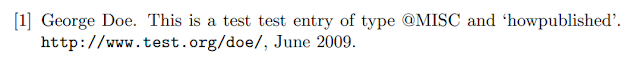BibTeX: How to cite a website
With the increasing importance of the internet for scientific research, need increases for properly citing online resources. Unfortunately, when the main LaTeX citation machinery
BibTeX was created, this was not to be foreseen; this is why there is to date no canonical way to cite, say, a website. Different workarounds have emerged, using for example some trickery with the
@MISC type (see below), but the right way™ hasn’t been found yet.
This could change with the advent of
biblatex. Its new entry type
@ONLINE is supposed to contain references to web resources and doesn’t give room for confusion anymore.
With the BibTeX entry
@ONLINE{Doe:2009:Online,
author = {Doe, Ringo},
title = {This is a test entry of type {@ONLINE}},
month = jun,
year = {2009},
url = {http://www.test.org/doe/}
}
and the LaTeX file
\documentclass{article}
\usepackage{biblatex}
\bibliography{test. bib}
\title{BibTeX Website citatations with the \textsf{biblatex}~package}
\date{}
\begin{document}
\maketitle
\nocite{Doe:2009:Online}
\printbibliography
\end{document}
one gets a nicely typeset list of references.

Note that there are plenty of more options and entry types in the biblatex package, such as (the currently unused)
@AUDIO and
@VIDEO.
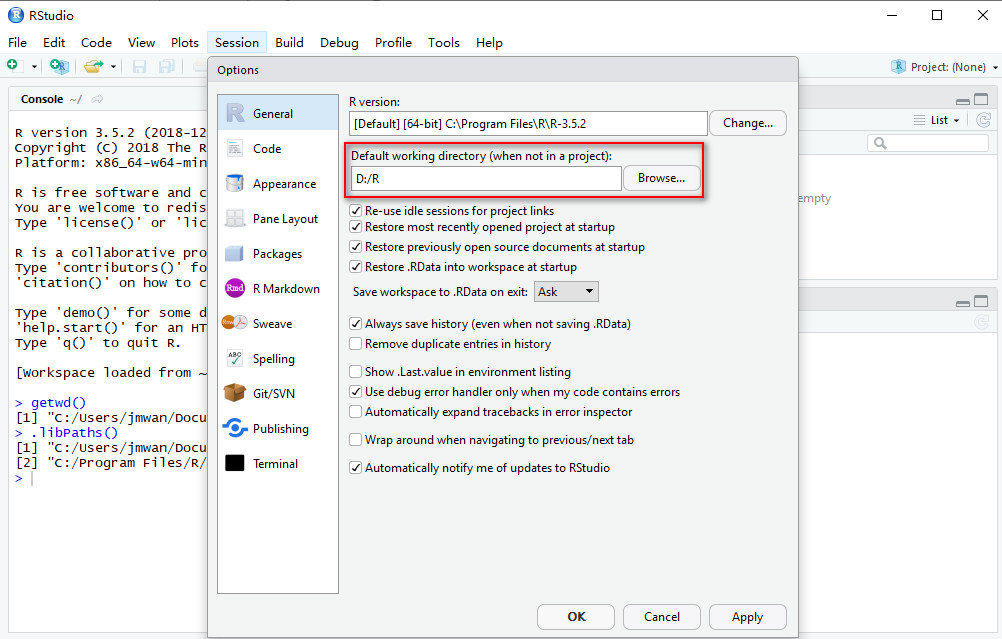
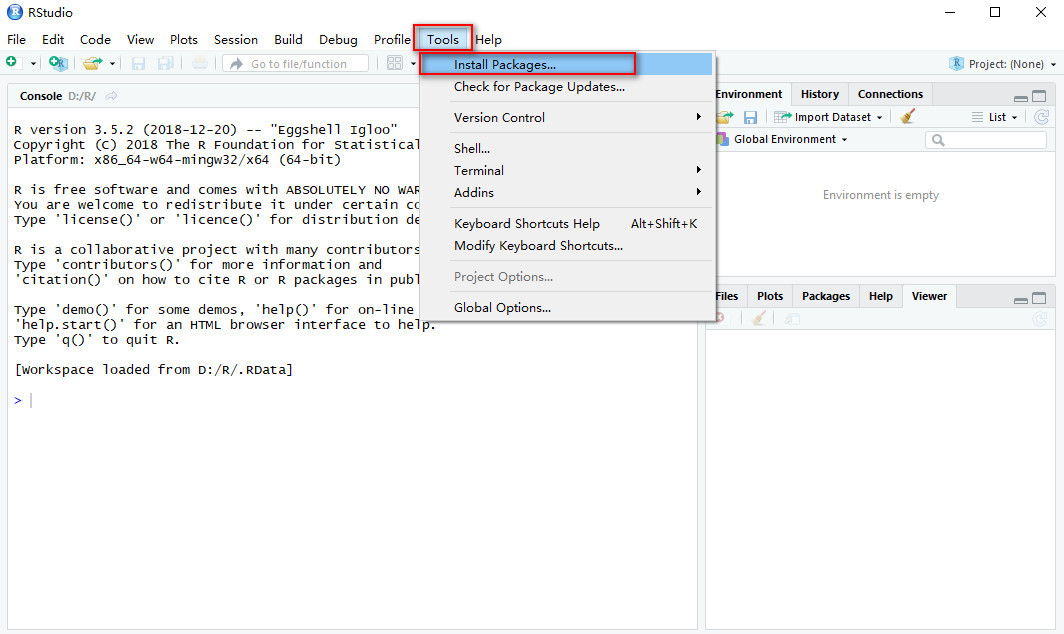
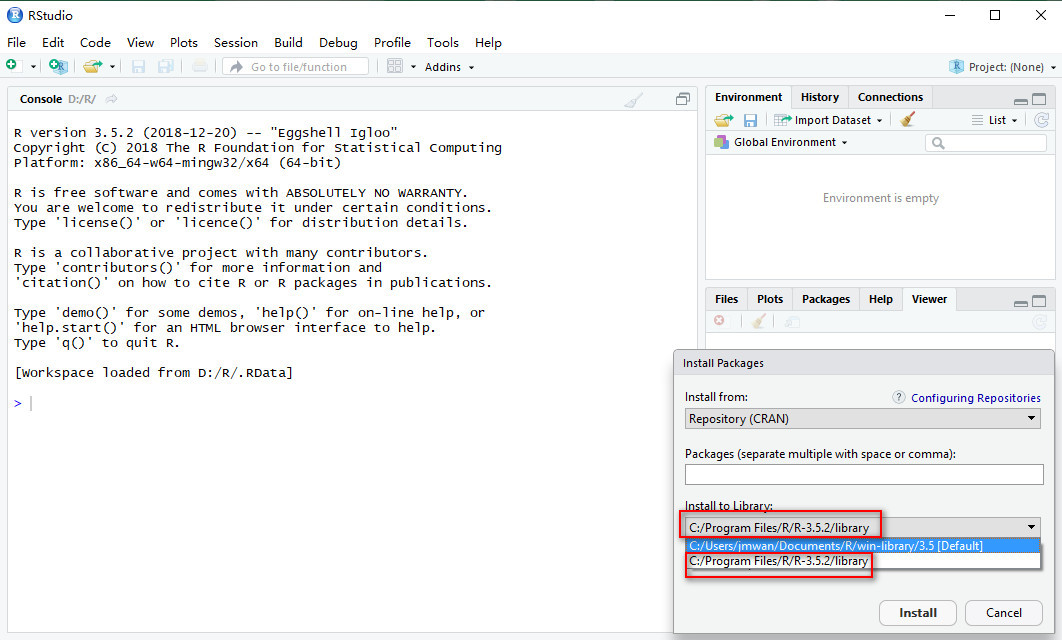
Because of its supposedly large impact on the (La)TeX community, the author of biblatex still declares the package as ‘beta’ which is why it is not included in TeXlive, for example. Should you for this or some other reason be unable to install biblatex, there are (inferior) alternatives to use for URL citations in a reference list.
Alternatives
Using the natbib package The natbib package extends the functionality of regular bibtex to a certain degree, and allows for website citations as well. There is no specific entry type for online resources, but
@MISC,
@OTHER, and
@BOOKLET work quite well.
@BOOKLET{Doe:2009:Booklet,
title = {This is a test entry of type {@BOOKLET}},
author = {Doe, John},
month = jun,
year = {2009},
url = {http://www.test.org/doe/}
}
@MISC{Doe:2009:Misc,
author = {Doe, Paul},
title = {This is a test test entry of type {@MISC}},
month = jun,
year = {2009},
url = {http://www.test.org/doe/}
}
@OTHER{Doe:2009:Other,
author = {Doe, Brian},
title = {This is a test entry of type {@OTHER}},
month = jun,
year = {2009},
url = {http://www.test.org/doe/}
}
Note that standard bibstyles (such as
plain) will not typeset the
url key contents of the individual entries; it is required to use one of natbib’s own entries, e.g.
plainnat.
\documentclass{article}
\usepackage{natbib}
\bibliographystyle{plainnat}
\usepackage{url}
\title{BibTeX Website citations with the \textsf{natbib} package}
\date{}
\begin{document}
\maketitle
\nocite{Doe:2009:Other,
Doe:2009:Misc,
Doe:2009:Booklet}
\bibliography{test}
\end{document}

Using the url package The most elemental way to include web references is via the
howpublished key of the
@MISC entry. Use
@MISC{Doe:2009:Misc,
author = {Doe, George},
title = {This is a test test entry of type {@MISC} and `howpublished'},
month = jun,
year = {2009},
howpublished={\url{http://www.test.org/doe/}}
}
and
\documentclass{article}
\bibliographystyle{plain}
\usepackage{url}
\begin{document}
\nocite{Doe:2009:Misc}
\bibliography{mybib}
\end{document}