Eureka Startup Error: Root name (‘timestamp‘) does not match expected type EurekaApplications
1. Eureka startup error
Recently, I was learning that Eureka started the client to report errors, and checked a bunch of fucking answers on the Internet
- Some people say that the spring security csrf authentication control is turned on, you have to add a configuration to cancel the csrf authentication
I see that my configuration does not introduce spring security package ah, where to open the login authentication, bullshit it - Some people say it is eureka url to add userName:password My eureka does not have a username password, should not be the problem here either
If you have introduced spring security and set login authentication to be added, the fundamental problem is not here
the error message is
Root name (‘timestamp’) does not match expected (‘applications’) for type EurekaApplications Caused by: com.fasterxml.jackson.databind.exc.MismatchedInputException: Root name (‘timestamp’) does not match expected (‘applications’) for type org.springframework.cloud.netflix.eureka.http.EurekaApplications at [Source: (org.springframework.util.StreamUtils$NonClosingInputStream); line: 1, column: 2] (through reference chain: org.springframework.cloud.netflix.eureka.http.EurekaApplications[“timestamp”])
Caused by: com.fasterxml.jackson.databind.exc.MismatchedInputException: Root name ('timestamp') does not match expected ('applications') for type `org.springframework.cloud.netflix.eureka.http.EurekaApplications`
at [Source: (org.springframework.util.StreamUtils$NonClosingInputStream); line: 1, column: 2] (through reference chain: org.springframework.cloud.netflix.eureka.http.EurekaApplications["timestamp"])
2. Solutions
Eureka requires that the suffix end of your serviceurl must be Eureka
if you write something else, the above error will appear
what I write is http://localhost:${server.port}/eurekajzj is wrong
The server is consistent with the client http://localhost: ${server. Port}/Eureka will do
Otherwise, the above error will appear
3. Eureka server configuration
First, start the class eurekaserver
to see the configuration of the server
spring.application.name=eureka-server
server.port=8761
#eureka auto-preservation off
eureka.server.enable-self-preservation=false
eureka.instance.hostname=eureka-hostname-jzj
# Cannot call self
eureka.client.fetch-registry=false
#Does not register itself
eureka.client.register-with-eureka=false
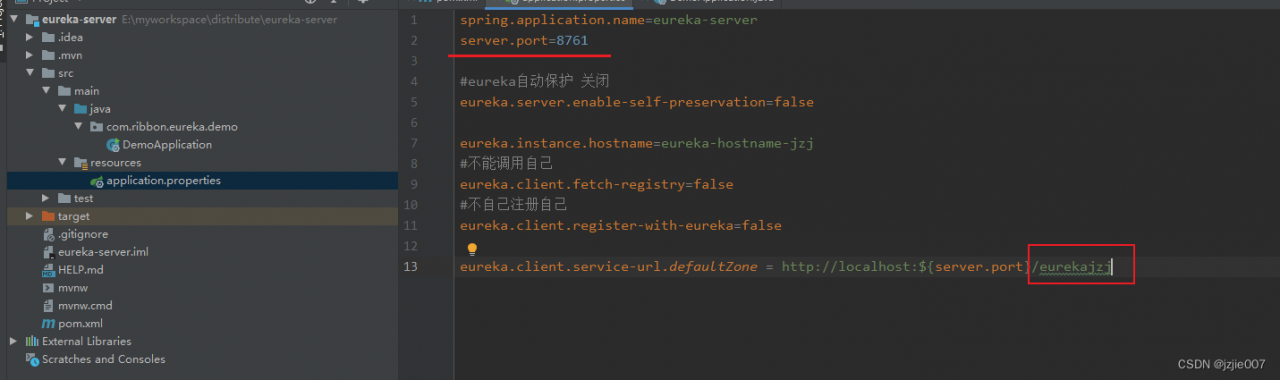
eureka.client.service-url.defaultZone = http://localhost:${server.port}/eurekajzj
4. Eureka client configuration
server.port=8088
#user service
spring.application.name=user-client
#eureka
eureka.client.serviceUrl.defaultZone=http://localhost:8761/eurekajzj
5. Problems
The problem is the eurekajzj suffix
The serviceUrl address of my Eureka Server configuration
eureka.client.service-url.defaultZone = http://localhost:${server.port}/eurekajzj
My client’s configured eureka address
eureka.client.serviceUrl.defaultZone = http://localhost:8761/eurekajzj
The suffix ending is not eureka
After modification, all Eureka services and clients are working fine

 2. Solution
2. Solution