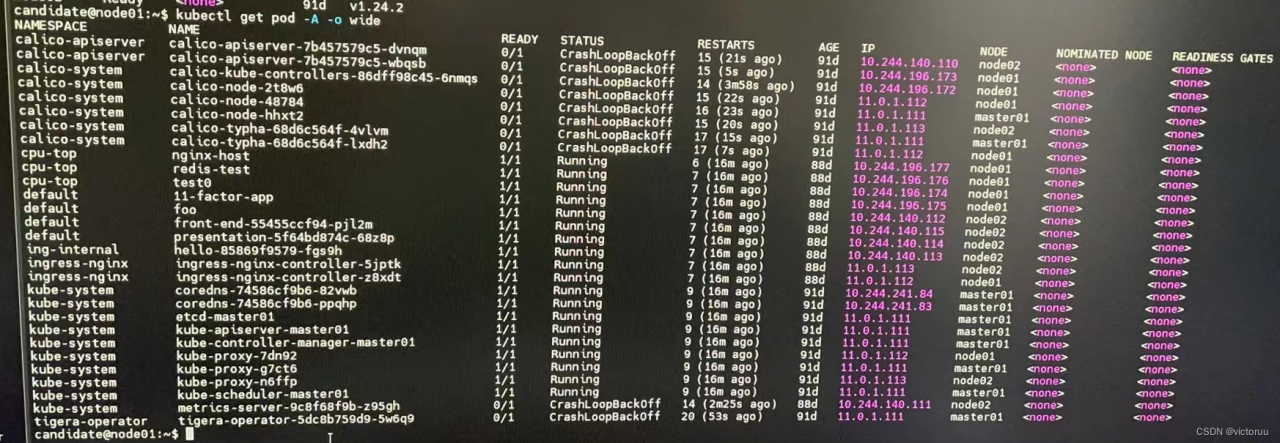
Installed calico using the tigera-operator method and reported an error after startup, all calico related pods show CrashLoopBackoff.
kubectl -n calico-system describe pod calico-node-2t8w6 and found the following error.
Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/ run/calico/ bird.ctl: connect: no such file or directory.
Cause of the problem:
We are experiencing this issue during a Kubernetes Cluster deployment. Since Calico automatically detects IP addresses by default using the first-found method and gets the wrong address, we need to specify the detection method manually.
1. Remove all the claico
kubectl -n tigera-operator get deployments.apps -o yaml > a.yaml
kubectl -n calico-system get daemonsets.apps calico-node -o yaml > b.yaml
kubectl -n calico-system get deployments.apps calico-kube-controllers -o yaml > c.yaml
kubectl -n calico-system get deployments.apps calico-typha -o yaml > d.yaml
kubectl -n calico-apiserver get deployments.apps calico-apiserver -o yaml > e.yaml
kubectl delete -f a.yaml
kubectl delete -f b.yaml
kubectl delete -f c.yaml
kubectl delete -f d.yaml
kubectl delete -f e.yaml
2. Remove custom-resources.yaml
kubectl delete -f tigera-operator.yaml
kubectl delete -f custom-resources.yaml
3. Remove vxlan.calico
ip link delete vxlan.calico
4. Modify custom-resources.yaml file and add nodeAddressAutodetectionV4:
# This section includes base Calico installation configuration.
# For more information, see: https://projectcalico.docs.tigera.io/v3.23/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
#bgp: Enabled
#hostPorts: Enabled
ipPools:
– blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
#linuxDataplane: Iptables
#multiInterfaceMode: None
nodeAddressAutodetectionV4:
interface: ens.*
—
# This section configures the Calico API server.
# For more information, see: https://projectcalico.docs.tigera.io/v3.23/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
5. Re-create
kubectl create -f tigera-operator.yaml
kubectl create -f custom-resources.yaml
check
kubectl -n calico-system get daemonsets.apps calico-node -o yaml|grep -A2 IP_AUTODETECTION_METHOD