Error message
Start Triton server
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v /full_path/deploy/models/:/models nvcr.io/nvidia/tritonserver:21.03-py3 tritonserver --model-repository=/models
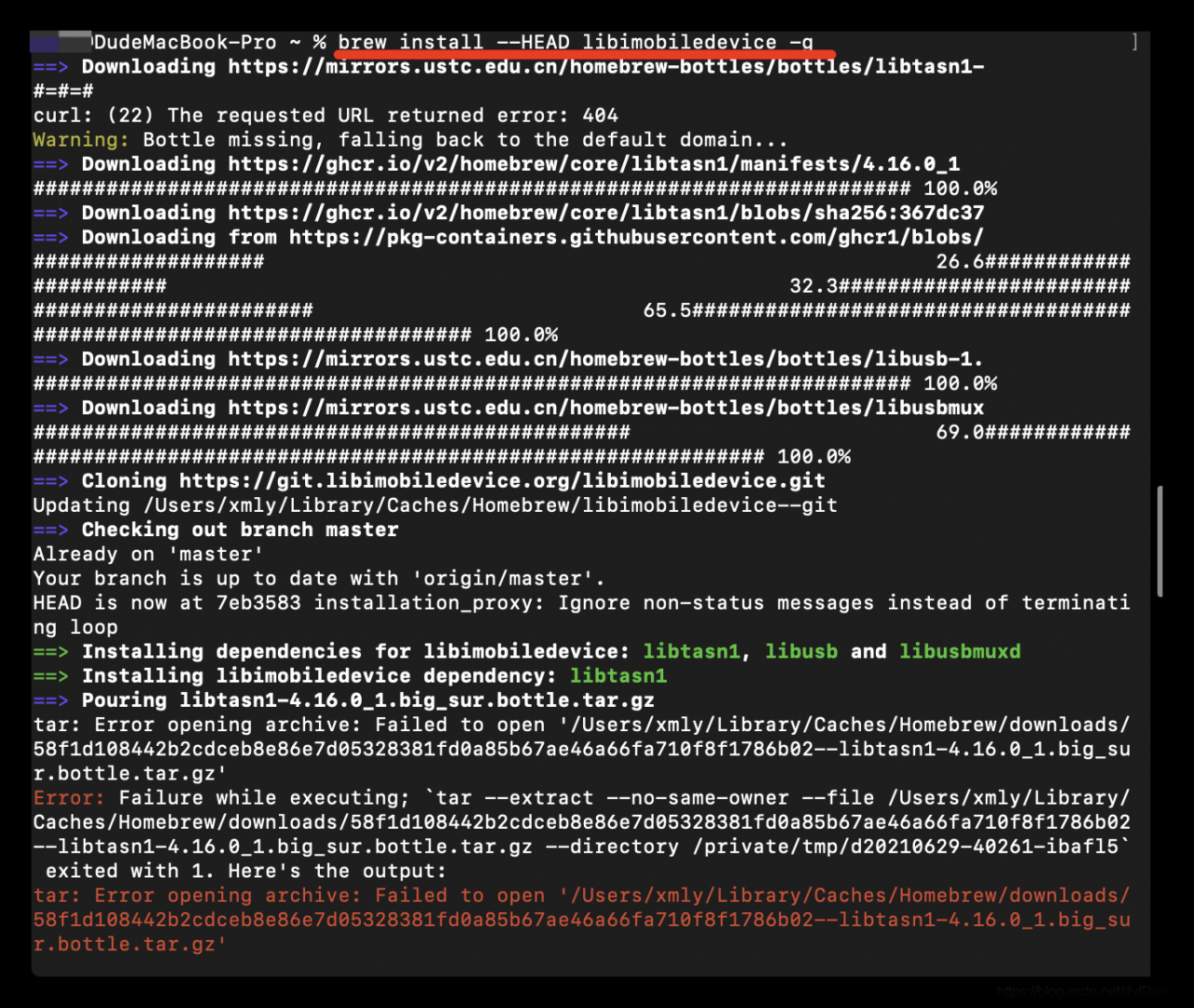
When starting tritonserver , internal – failed to load all models </ mark> error is reported. The error message is as follows
+-----------+---------+----------------------------------------------------------------------------------------------------+
| Model | Version | Status |
+-----------+---------+----------------------------------------------------------------------------------------------------+
| resnet152 | 1 | UNAVAILABLE: Internal - failed to load all models features |
+-----------+---------+----------------------------------------------------------------------------------------------------+
I0420 16:14:07.481496 1 server.cc:280] Waiting for in-flight requests to complete.
I0420 16:14:07.481506 1 model_repository_manager.cc:435] LiveBackendStates()
I0420 16:14:07.481512 1 server.cc:295] Timeout 30: Found 0 live models and 0 in-flight non-inference requests
error: creating server: Internal - failed to load all models
Error analysis
This error is usually caused by the inconsistency of the version of tensorrt . The inconsistency here refers to the inconsistency between the version of tensorrt and the version of tensorrt in the docker image Triton server when we convert the model from (onnx) to tensorrt, We only need to use tensorrt which is consistent with the version in tritonserver to re transform the model to solve the problem
Solution:
Enter the image
docker run --gpus all -it --rm -v /full_path/deploy/models/:/models nvcr.io/nvidia/tensorrt:21.03-py3
#Go to the installation directory of tensorrt, there is a trtexec executable file inside
The #trition-server relies on this to load the model
cd /workspace/tensorrt/bin
The purpose of the - V parameter is to map a directory so that we don’t want to copy the model file
Test whether tensorrt can load the model successfully
trtexec --loadEngine=resnet152.engine
#output
[06/25/2021-22:28:38] [I] Host Latency
[06/25/2021-22:28:38] [I] min: 3.96118 ms (end to end 3.97363 ms)
[06/25/2021-22:28:38] [I] max: 4.36243 ms (end to end 8.4928 ms)
[06/25/2021-22:28:38] [I] mean: 4.05112 ms (end to end 7.76932 ms)
[06/25/2021-22:28:38] [I] median: 4.02783 ms (end to end 7.79443 ms)
[06/25/2021-22:28:38] [I] percentile: 4.35217 ms at 99% (end to end 8.46191 ms at 99%)
[06/25/2021-22:28:38] [I] throughput: 250.151 qps
[06/25/2021-22:28:38] [I] walltime: 1.75494 s
[06/25/2021-22:28:38] [I] Enqueue Time
[06/25/2021-22:28:38] [I] min: 2.37549 ms
[06/25/2021-22:28:38] [I] max: 3.47607 ms
[06/25/2021-22:28:38] [I] median: 2.49707 ms
[06/25/2021-22:28:38] [I] GPU Compute
[06/25/2021-22:28:38] [I] min: 3.90149 ms
[06/25/2021-22:28:38] [I] max: 4.29773 ms
[06/25/2021-22:28:38] [I] mean: 3.98691 ms
[06/25/2021-22:28:38] [I] median: 3.96387 ms
[06/25/2021-22:28:38] [I] percentile: 4.28748 ms at 99%
[06/25/2021-22:28:38] [I] total compute time: 1.75025 s
&&&& PASSED TensorRT.trtexec
If the final output passed </ mark> indicates that the model is loaded successfully, let’s take a look at a case of loading failure
[06/26/2021-22:09:27] [I] === Device Information ===
[06/26/2021-22:09:27] [I] Selected Device: GeForce RTX 3090
[06/26/2021-22:09:27] [I] Compute Capability: 8.6
[06/26/2021-22:09:27] [I] SMs: 82
[06/26/2021-22:09:27] [I] Compute Clock Rate: 1.725 GHz
[06/26/2021-22:09:27] [I] Device Global Memory: 24265 MiB
[06/26/2021-22:09:27] [I] Shared Memory per SM: 100 KiB
[06/26/2021-22:09:27] [I] Memory Bus Width: 384 bits (ECC disabled)
[06/26/2021-22:09:27] [I] Memory Clock Rate: 9.751 GHz
[06/26/2021-22:09:27] [I]
[06/26/2021-22:09:27] [I] TensorRT version: 8000
[06/26/2021-22:09:28] [I] [TRT] [MemUsageChange] Init CUDA: CPU +443, GPU +0, now: CPU 449, GPU 551 (MiB)
[06/26/2021-22:09:28] [I] [TRT] Loaded engine size: 222 MB
[06/26/2021-22:09:28] [I] [TRT] [MemUsageSnapshot] deserializeCudaEngine begin: CPU 449 MiB, GPU 551 MiB
[06/26/2021-22:09:28] [E] Error[1]: [stdArchiveReader.cpp::StdArchiveReader::34] Error Code 1: Serialization (Version tag does not match. Note: Current Version: 43, Serialized Engine Version: 96)
[06/26/2021-22:09:28] [E] Error[4]: [runtime.cpp::deserializeCudaEngine::74] Error Code 4: Internal Error (Engine deserialization failed.)
[06/26/2021-22:09:28] [E] Engine creation failed
[06/26/2021-22:09:28] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8000]
#or
[06/25/2021-19:08:23] [I] Memory Clock Rate: 9.751 GHz
[06/25/2021-19:08:23] [I]
[06/25/2021-19:08:25] [E] [TRT] INVALID_CONFIG: The engine plan file is not compatible with this version of TensorRT, expecting library version 7.2.3 got 7.2.2, please rebuild.
[06/25/2021-19:08:25] [E] [TRT] engine.cpp (1646) - Serialization Error in deserialize: 0 (Core engine deserialization failure)
[06/25/2021-19:08:25] [E] [TRT] INVALID_STATE: std::exception
[06/25/2021-19:08:25] [E] [TRT] INVALID_CONFIG: Deserialize the cuda engine failed.
[06/25/2021-19:08:25] [E] Engine creation failed
[06/25/2021-19:08:25] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec
The above error message is a typical problem caused by the version mismatch of tensorrt . There are two ways to solve this problem. the first one is to re export the engine file of the model with the matching tensorrt version , the second one is to modify the version of tritonserver to match the version of tensorrt used in the engine model file
The first method
To pull a tensorrt version that is consistent with the tritonserver version, for example
#pull tritonserver mirror
docker pull nvcr.io/nvidia/tritonserver:21.03-py3
#pull tensorrt mirror
docker pull nvcr.io/nvidia/tensorrt:21.03-py3
After the pull is completed, the model can be transformed again through the corresponding version of tensorrt image
The second method
You can go to the NVIDIA image website and pull the Triton server with the same version as tensorrt. Each version of Triton server: the list of Triton server images