Question 1Question 2Question 3Question 4Question 5
For more detail, see the html file here.
Question 1
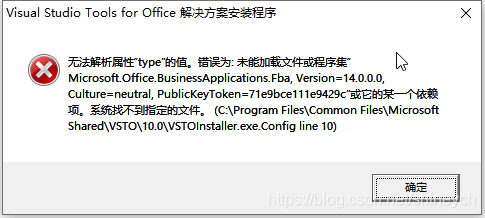
Register an application with the Github API here github application. Access the API to get information on your instructors repositories(target url) . Use this data to find the time that the datasharing repo was created. What time was it created? This tutorial may be useful help tutorial. You may also need to run the code in the base R package and not R studio.
2013-11-07T13:25:07Z2014-03-05T16:11:46Z2014-02-06T16:13:11Z2012-06-20T18:39:06Z
library(httr)
library(httpuv)
# 1.OAuth settings for github:
Client_ID <- '66fba4580b9b23531d6e'
Client_Secret <- '7fd8a4f7d72ab12b6c01b5c4880bc6da7723eec2'
myapp <- oauth_app("First APP", key = Client_ID, secret = Client_Secret)
# 2. Get OAuth credentials
github_token <- oauth2.0_token(oauth_endpoints("github"), myapp)
# 3. Use API
gtoken <- config(token = github_token)
req <- GET("https://api.github.com/users/jtleek/repos", gtoken)
stop_for_status(req)
# 4. Extract out the content from the request
json1 = content(req)
# 5. convert the list to json
json2 = jsonlite::fromJSON(jsonlite::toJSON(json1))
# 6. Result
json2[json2$full_name == "jtleek/datasharing", ]$created_at
Question 2
The sqldf package allows for execution of SQL commands on R data frames. We will use the sqldf package to practice the queries we might send with the dbSendQuery command in RMySQL. Download the American Community Survey data and load it into an R object called acs(data website), Which of the following commands will select only the data for the probability weights pwgtp1 with ages less than 50?
sqldf("select * from acs where AGEP < 50")sqldf("select * from acs")sqldf("select pwgtp1 from acs")sqldf("select pwgtp1 from acs where AGEP < 50")
# load package: sqldf is short for SQL select for data frame.
library(sqldf)
# 1. download data
download.file(url = "https://d396qusza40orc.cloudfront.net/getdata%2Fdata%2Fss06pid.csv", destfile = "./data/acs.csv")
# 2. read data
acs <- read.csv("./data/acs.csv")
# 3. select using sqldf
#sqldf("select pwgtp1 from acs where AGEP<50", drv='SQLite')
Question 3
Using the same data frame you created in the previous problem, what is the equivalent function to unique(acs$AGEP)
sqldf("select unique AGEP from acs")sqldf("select distinct pwgtp1 from acs")sqldf("select AGEP where unique from acs")sqldf("select distinct AGEP from acs")
result <- sqldf("select distinct AGEP from acs", drv = "SQLite")
nrow(result)
length(unique(acs$AGEP))
Question 4
How many characters are in the 10th, 20th, 30th and 100th lines of HTML from this page: target page.(Hint: the nchar() function in R may be helpful)
45 31 2 2543 99 8 643 99 7 2545 0 2 245 31 7 2545 92 7 245 31 7 31
# 1. set url
url <- url("http://biostat.jhsph.edu/~jleek/contact.html")
# 2. read content from url
content <- readLines(url)
# 3. result
nchar(content[c(10, 20, 30, 100)])
Question 5
Read this data set into R and report the sum of the numbers in the fourth column data web. Original source of the data: original data web
(Hint this is a fixed width file format)
35824.9101.8336.5222243.128893.332426.7
# 1. read data
data <- read.fwf(file = "https://d396qusza40orc.cloudfront.net/getdata%2Fwksst8110.for",
skip = 4,
widths = c(12, 7,4, 9,4, 9,4, 9,4))
# 2. result
sum(as.numeric(data[,4]))