spark read and write odps exception
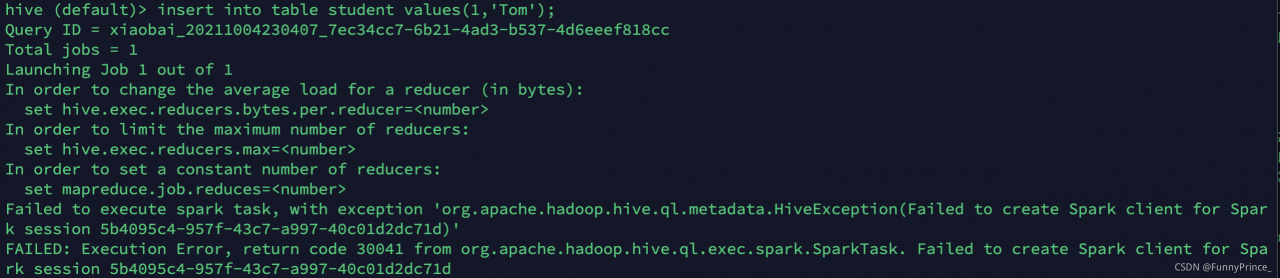
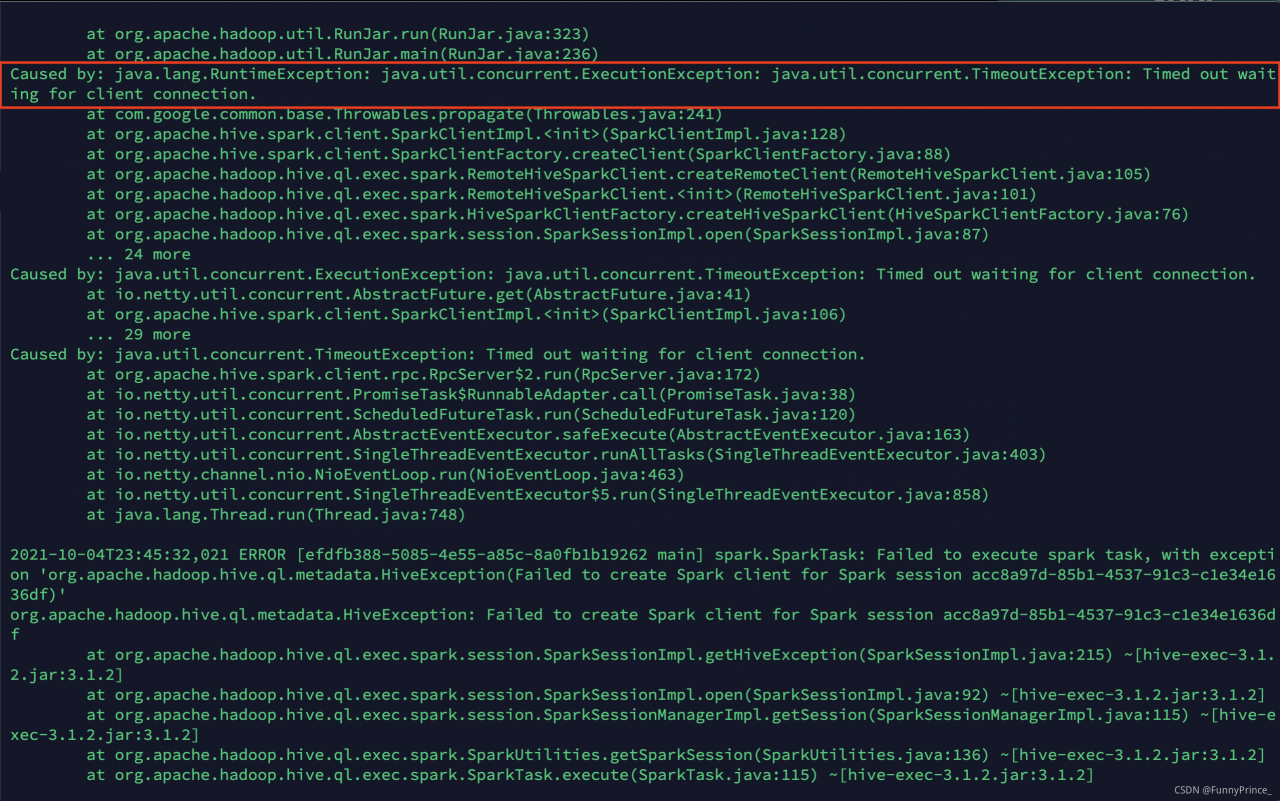
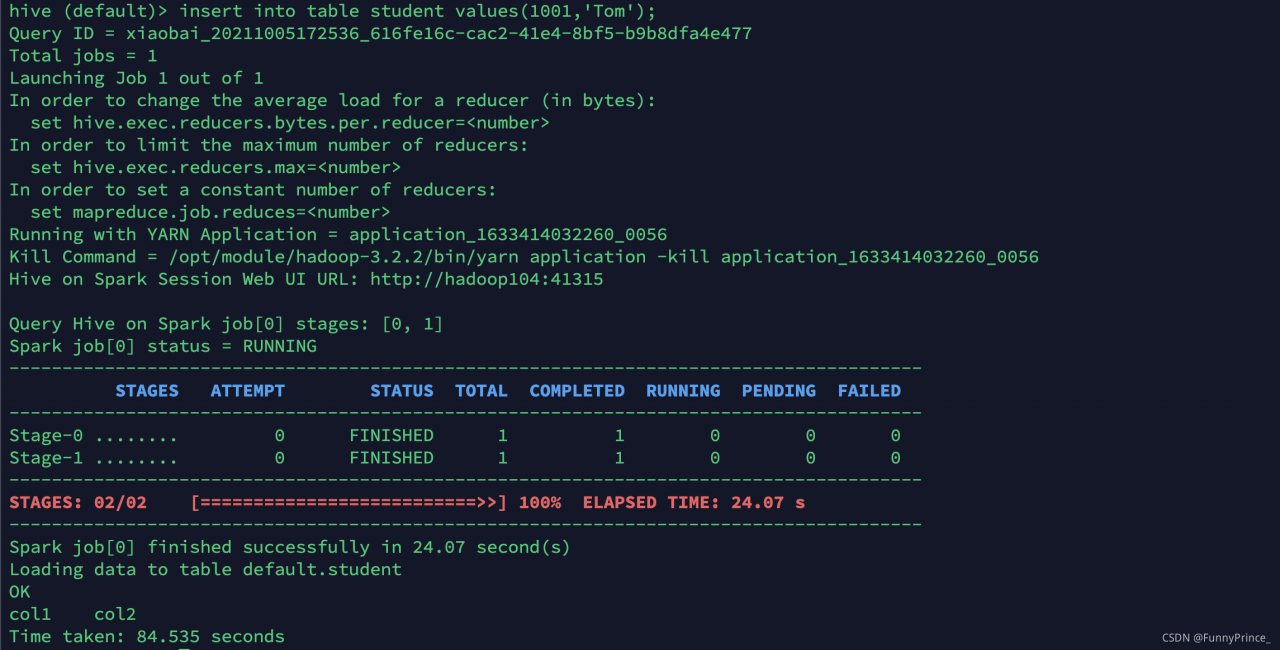
Error message [Summary of different error reports submitted multiple times].
ERROR ApplicationMaster: User class threw exception: java.io.IOException: GetFileMeta PANGU_CAPABILITY_NO_PERMISSION PANGU_CAPABILITY_NO_PERMISSION PanguPermissionException When GetFileMeta
Exception in thread “main” org.apache.hadoop.yarn.exceptions.YarnException: com.aliyun.odps.cupid.CupidException: subprocess exit: 512, stderr content: ERROR: ld.so: object ‘KaTeX parse error: Expected '}', got 'EOF' at end of input: …ld.so: object '{LD_PRELOAD’ from LD_PRELOAD cannot be preloaded: ignored.
ERROR: ld.so: object ‘${LD_PRELOAD’ from LD_PRELOAD cannot be preloaded: ignored.
Caused by: com.aliyun.odps.cupid.CupidException: subprocess exit: 512, stderr content: ERROR: ld.so: object ‘KaTeX parse error: Expected '}', got 'EOF' at end of input: …ld.so: object '{LD_PRELOAD’ from LD_PRELOAD cannot be preloaded: ignored.
ERROR: ld.so: object ‘${LD_PRELOAD’ from LD_PRELOAD cannot be preloaded: ignored
21/12/09 14:05:23 INFO ShutdownHookManager: Shutdown hook called , stdout content: at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(YarnClientImpl.java:180) at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:174) at org.apache.spark.deploy.yarn.Client.run(Client.scala:1170) at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1552) at org.apache.spark.deploy.SparkSubmit. o r g .org.orgapaches p a r k sparksparkdeployS p a r k S u b m i t SparkSubmitSparkSubmitr u n M a i n ( S p a r k S u b m i t . s c a l a : 879 ) a t o r g . a p a c h e . s p a r k . d e p l o y . S p a r k S u b m i t runMain(SparkSubmit.scala:879) at org.apache.spark.deploy.SparkSubmitrunMain(SparkSubmit.scala:879)atorg.apache.spark.deploy.SparkSubmit.doRunMain1 ( S p a r k S u b m i t . s c a l a : 197 ) a t o r g . a p a c h e . s p a r k . d e p l o y . S p a r k S u b m i t 1(SparkSubmit.scala:197) at org.apache.spark.deploy.SparkSubmit1(SparkSubmit.scala:197)atorg.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:227) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
21/12/09 14:19:11 INFO ShutdownHookManager: Shutdown hook called , stdout content: at com.aliyun.odps.cupid.CupidUtil.errMsg2SparkException(CupidUtil.java:43) at com.aliyun.odps.cupid.CupidUtil.getResult(CupidUtil.java:123) at com.aliyun.odps.cupid.requestcupid.YarnClientImplUtil.transformAppCtxAndStartAM(YarnClientImplUtil.java:287) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(YarnClientImpl.java:178) … 8 more
How to Solve:
he -class attribute was wrong when I submitted the jar package.
Incorrect:
-class should not be the separator “\” before, but the separator “.”
spark-submit --master yarn-cluster \
--conf spark.hadoop.odps.cupid.history.server.address='XX' \
--conf spark.hadoop.odps.cupid.proxy.domain.name='XX' \
--conf spark.hadoop.odps.moye.trackurl.host='XX' \
--conf spark.hadoop.odps.cupid.proxy.end.point='XX' \
--conf spark.hadoop.odps.cupid.volume.paths='Just store the address directory, no need to specify a specific file name' \
--class com/cctv/bigdata/recall/rank.video.LRRankModel \
/Users/keino/Desktop/recorecall-1.0-SNAPSHOT-shaded.jar 10 10 10 20210701
Correct writing:
spark-submit --master yarn-cluster \
--conf spark.hadoop.odps.cupid.history.server.address='XX' \
--conf spark.hadoop.odps.cupid.proxy.domain.name='XX' \
--conf spark.hadoop.odps.moye.trackurl.host='XX' \
--conf spark.hadoop.odps.cupid.proxy.end.point='XX' \
--conf spark.hadoop.odps.cupid.volume.paths='Just store the address directory, no need to specify a specific file name' \
--class com.cctv.bigdata.recall.rank.video.LRRankModel \
/Users/keino/Desktop/recorecall-1.0-SNAPSHOT-shaded.jar 10 10 10 20210701