Error Messages:
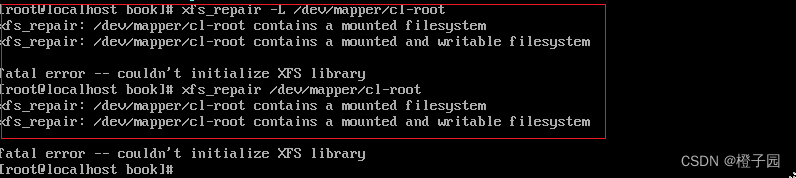
Internal error XFS_WANT_CORRUPTED_GOTO at line 1635 of file fs/xfs/libxfs/xfs_alloc.c. Caller xfs_free_extent Internal error xfs_trans_cancel at line 990 of flie fs/xfs/xfs_trans.c. xfs_repair: /dev/mapper/cl-root contains a mounted filesystem xfs_repair: /dev/mapper/cl-root contains a mounted writable filesystem fatal error – couldn’t initialize XFS library
Reason description:
I found that most of the solutions found on the Internet do not explain why, so we don’t know why, but just follow them. Some people may actually solve the problem of the partition of the system directory mount, while some people can’t solve the problem because it’s not the directory of the system mount.
The above error is mainly due to the problem of the file in the disk partition, so it needs to be repaired. But please check which partition of the attached directory has a problem first, and then repair the corresponding disk partition.
Solution:
1. First, after reporting the following errors, please check the information in the red box
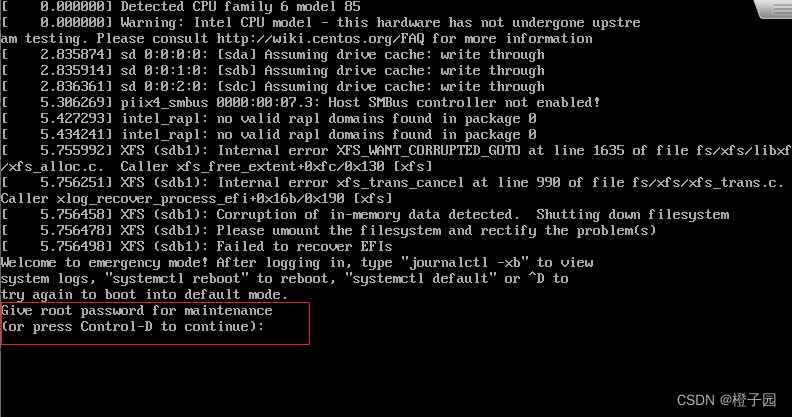
You can see that you are asked to enter the root password, and then press enter to see that you have entered the root user, and you can enter the command

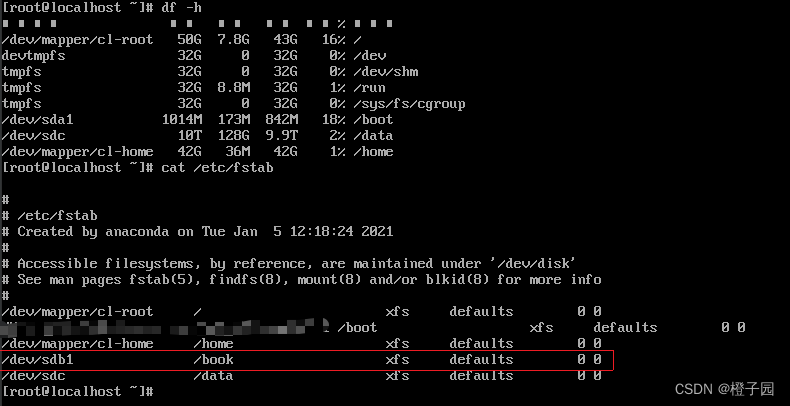
First, enter the following command first. df is to view the partition of the mounted directory, and cat /etc/fstab is to view the directory information of the previously persistent mounted partition. It can be seen (in the red box) that the directory attached to /book is gone, so it can be inferred that the partition /dev/sdb1 has a problem and needs to be repaired.
df -h
cat /etc/fstab
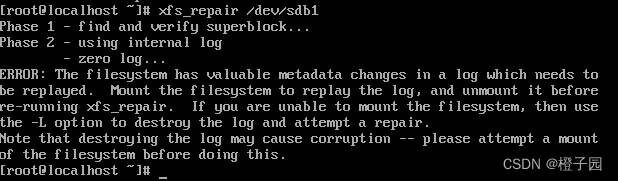
2. Next, you can repair it. Use the following command to repair it. If you do not add the L parameter, the following error will be reported:
Function of L parameter:
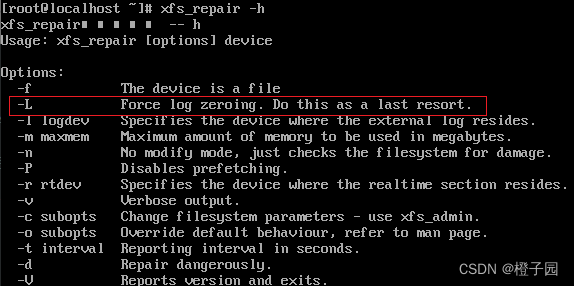
Add the L parameter to complete the execution
xfs_repair -L /dev/sdb1

Finally, restart with the following command to solve the problem
init 6
Note: if you repair some partitions that are not damaged, the following error will be reported, so be sure to find the damaged partition that you need to repair, and then go to XFS_ repair