pytorch 1.9 Error:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [4, 512, 16, 16]], which is output 0 of ConstantPadNdBackward, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True). #23
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [4, 512, 16, 16]], which is output 0 of ConstantPadNdBackward, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True). #23
At first I thought it was the input z = torch.randn(batch_size, 128,1,1).to(device).
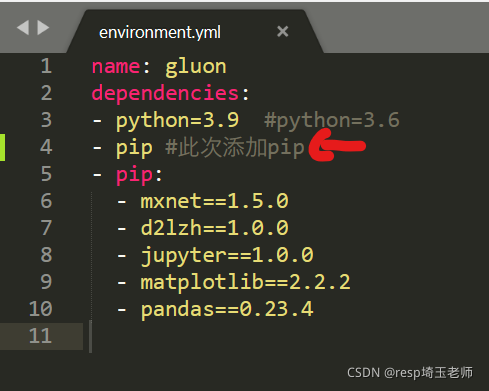
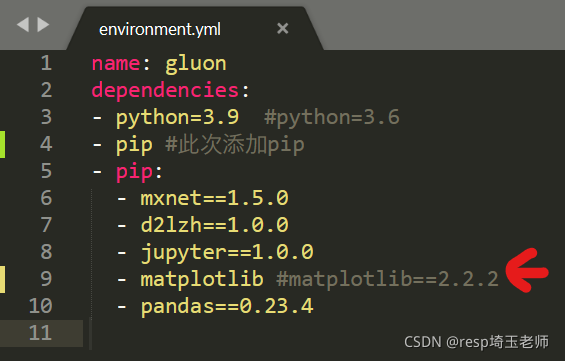
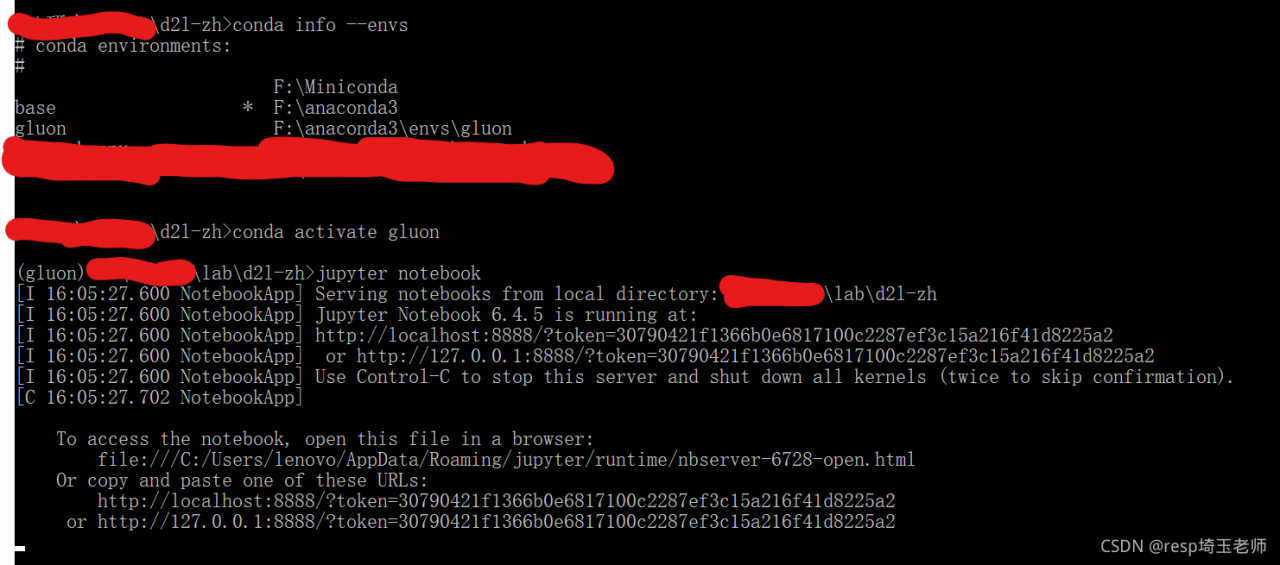
Solution:
pip install torch == 1.4 torchvision = 0.05
pip install torch == 1.4 torchvision = 0.05