Background description:
I just started to contact crawlers, read online tutorials and began to learn a little bit. All the knowledge points are relatively shallow. If there are better methods, please comment and share.
The initial crawler is very simple: crawl the data list in a web page, and the format returned by the web page is also very simple. It is in the form of a dictionary, which can be directly accessed by saving it as a dictionary with . Json() .
At the beginning of contact with asynchronous collaborative process, after completing the exercise, try to transform the original crawler, resulting in an error.
Initial code:
async def download_page(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
await result = resp.text()
async def main(urls):
tasks = []
for url in urls:
tasks.append(asyncio.create_task(download_page(url))) # 我的python版本为3.9.6
await asyncio.await(tasks)
if __name__ == '__main__':
urls = [ url1, url2, …… ]
asyncio.run(main(urls))
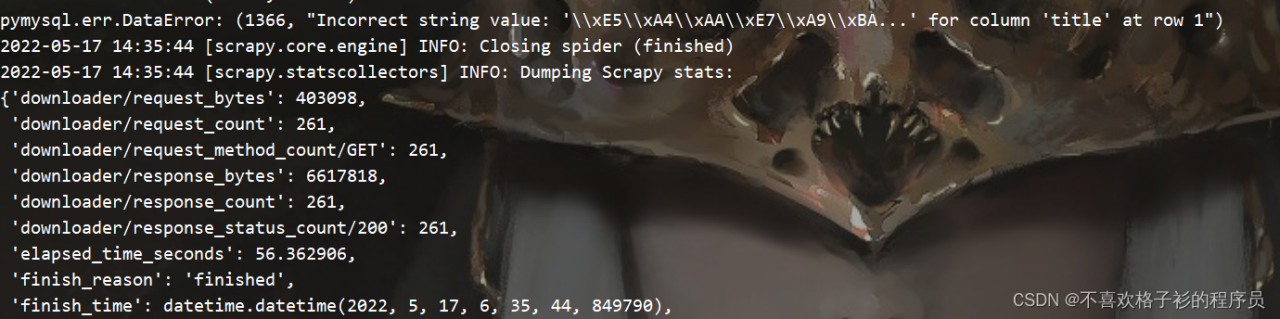
This is the most basic asynchronous collaborative process framework. When the amount of data is small, it can basically meet the requirements. However, if the amount of data is slightly large, it will report errors. The error information I collected is as follows:
aiohttp.client_exceptions.ClientOSError: [WinError 64] The specified network name is no longer available.
Task exception was never retrieved
aiohttp.client_exceptions.ClientOSError: [WinError 121] The signal timeout has expired
Task exception was never retrieved
aiohttp.client_exceptions.ServerDisconnectedError: Server disconnected
Task exception was never retrieved
The general error message is that there is a problem with the network request and connection
as a beginner, I didn’t have more in-depth understanding of network connection, nor did I learn more in-depth asynchronous co process operation. Therefore, it is difficult to solve the problem of error reporting.
Solution:
The big problem with the above error reports is that each task creates a session. When too many sessions are created, an error will be reported.
Solution:
Try to create only one session
async def download_page(url,session):
async with session.get(url) as resp:
await result = resp.text()
async def main(urls):
tasks = []
async with aiohttp.ClientSession() as session: # The session will be created in the main function, and the session will be passed to the download_page function as a variable.
for url in urls:
tasks.append(asyncio.create_task(download_page(url,session)))
#My python version is 3.9.6, python version 3.8 and above, if you need to create asynchronous tasks, you need to create them via asyncio.create_task(), otherwise it will run normally but will give a warning message await asyncio.await(tasks)
if __name__ == '__main__':
urls = [ url1, url2, …… ]
asyncio.run(main(urls))
In this way, the problem of connection error can be solved to a certain extent when crawling a large amount of data.
Sentiment: in the process of programming, thinking should be more flexible. A little change may improve the efficiency a lot.