Refer to the official website:
http://scikit-learn.org/dev/developers/advanced_installation.html#install-bleeding-edge
The screenshot is as follows:
Under the CMD window, enter:
PIP install -u scikit-learn PIP install -u scikit-learn
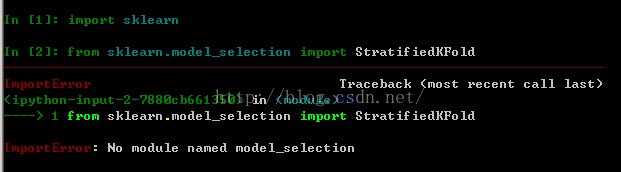
Since I installed Anaconda first, I installed version 0.17 of Scikit-Learn by default, but in IPython interactive mode type:
Error from sklearn.model_selection import KFold No module named model_selection
The diagram below:
StratifiedKfold and other classes must be import from sklearn.cross_validation. For example:
from sklearn.cross_validation import KFold
The parameters of this version of KFold etc. are different from those of 0.18. See the documentation on the website for details.
preface
The official series of Computer Vision Daily organized the large-scale inventory work of ECCV 2020
See above for details:
2020 target detection ECCV paper large inventory (49 papers) ECCV 2020 semantic segmentation large inventory (article 37) [ECCV paper 2020 instance segmentation paper inventory (12 paper) (https://blog.csdn.net/amusi1994/article/details/108999316)
This paper mainly includes: panoramic segmentation and other directions. Two papers have been sorted out, and the PDF of all papers have been packaged. Baidu cloud resources are as follows:
The article directories
Preface Panoramic Segmentation Paper Download PDF
Panoramic segmentation
Joint Semantic Instance Segmentation on Graphs with the Semantic Mutex Watershed
Author units: Heidelberg university paper: https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/5393_ECCV_2020_paper.php code: no Chinese reading: no
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Author unit: Johns Hopkins university, Google paper: https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/1564_ECCV_2020_paper.php code: https://github.com/csrhddlam/axial-deeplab in Chinese reading: no
Paper PDF Download
The PDF of the above 14 papers has all been packaged, Baidu Cloud link:
This part of the content is in accordance with the experience of baidu on the operation of the article records, in accordance with the steps of the operation can be, there is no problem. The article addresses is: https://jingyan.baidu.com/article/9c69d48f5bb44552c8024e65.html
The steps are as follows:
first close the running jupyter notebook plug-in package:
is equipped, we launch jupyter; at that moment, we see the nbexlogo appearing on the menu bar, that is, the installation is successful; and then, we click on the configuration to enter nbexschematic; and we see that there are many items; after the modification, click on TableOfContents to update the webpage or restart jupyter; that is,
Random forest algorithm learning
When I was doing Kaggle recently, I found that the random forest algorithm had a very good effect on classification problems. In most cases, the effect was far better than that of SVM, log regression, KNN and other algorithms. So I want to think about how this algorithm works.
To learn random forest, we first briefly introduce the integrated learning method and decision tree algorithm. The following is only a brief introduction of these two methods (see Chapter 5 and Chapter 8 of statistical learning Methods for specific learning recommendations).
Bagging and Boosting concepts and differences
This part is mainly to study the: http://www.cnblogs.com/liuwu265/p/4690486.html
Random forest belongs to Bagging algorithm in Ensemble Learning. In ensemble learning, the algorithms are mainly divided into Bagging algorithm and Boosting algorithm. Let’s first look at the characteristics and differences between the two approaches.
Bagging (Bagging)
The algorithm process of Bagging is as follows:
randomly draw n training samples from the original sample set using the Bootstraping method, conduct a total of k rounds of drawing, and obtain k training sets. (K training sets are independent of each other, and elements can be repeated.) For k training sets, we train k models (these models can be determined according to specific problems, such as decision tree, KNN, etc.) for classification problems: classification results are generated by voting; For the regression problem, the mean value of the predicted results of k models is taken as the final prediction result. (all models are equally important)
Boosting, Boosting
Boosting algorithm process is as follows:
establishes weight wi for each sample in the training set, indicating the attention paid to each sample. When the probability of a sample being misclassified is high, it is necessary to increase the weight of the sample. Each iteration is a weak classifier during the iteration process. We need some kind of strategy to combine them as the final model. (For example, AdaBoost gives each weak classifier a weight and combines them linearly as the final classifier. The weaker classifier with smaller error has larger weight)
Bagging, Boosting the main difference
sample selection: Bagging adopts Bootstrap randomly put back sampling; But Boosting the training set of each round is unchanged, changing only the weight of each sample. Sample weight: Bagging uses uniform sampling with equal weight for each sample. Boosting adjust the sample weight according to the error rate, the greater the error rate, the greater the sample weight. Prediction function: Bagging all prediction functions have equal weight; Boosting the prediction function with lower error has greater weight. Parallel computing: Bagging each prediction function can be generated in parallel; Boosting each prediction function must be generated iteratively in sequence.
The following is the new algorithm obtained by combining the decision tree with these algorithm frameworks:
1) Bagging + decision tree = random forest
2) AdaBoost + decision tree = lifting tree
3) Gradient Boosting + decision tree = GBDT
The decision tree
Common decision tree algorithms include ID3, C4.5 and CART. The model building ideas of the three algorithms are very similar, but different indexes are adopted. The process of building the decision tree model is roughly as follows:
ID3, Generation of C4.5 decision tree
Input: training set D, feature set A, threshold EPS output: decision tree T
If
D in all samples belong to the same kind of Ck, it is single node tree T, the class Ck as A symbol of the class of the nodes, T if returns A null set, namely no characteristics as the basis, it is single node tree T, and D in implementing cases the largest class Ck as A symbol of the class of the node, return T otherwise, calculating the feature of D information gain in A (ID3)/information gain ratio (C4.5), choose the greatest feature of the information gain if Ag Ag information gain (than) is less than the threshold value of eps, is T for single node tree, and will be the biggest in implementing occuring D class Ck as A symbol of the class of the node, Otherwise, D is divided into several non-empty subsets Di according to the feature Ag, and the class with the largest number of real cases in Di is taken as the marker to construct the child node, and the tree T is formed by the node and its child nodes. T is returned to the ith child node, with Di as the training set and a-{Ag} as the feature set. Recursively, 1~5 is called to obtain the subtree Ti, and Ti
is returned
Generation of CART decision tree
Here is a brief introduction to the differences between CART and ID3 and C4.5.
CART tree is a binary tree, while ID3 and C4.5 can be multi-partite trees. When generating subtrees, CART selects one feature and one value as the segmentation point. The basis for generating two subtrees is gini index, and the feature with the minimum gini index and the segmentation point are selected to generate subtrees
Pruning of a decision tree
The pruning of decision tree is mainly to prevent overfitting, but the process is not described in detail.
The main idea is to trace back upward from the leaf node and try to prune a node to compare the loss function value of the decision tree before and after pruning. Finally, we can get the global optimal pruning scheme through dynamic programming (tree DP, acMER should know).
Random Forests
Random forest is an important integrated learning method based on Bagging, which can be used for classification, regression and other problems.
Random forests have many advantages:
Has a very high accuracy the introduction of randomness, it is not easy to make random forests after fitting of the randomness of introduction, makes the random forest has a good ability to resist noise can deal with high dimension data, and don’t have to do feature selection can not only deal with discrete data, also can deal with continuous data, data set without standardized training speed, can be variable importance easy parallelization
Disadvantages of random forest:
When the number of decision trees in the random forest is large, the space and time required for training will be large. The random forest model has a lot of problems to explain. It is a black box model
Similar to Bagging process described above, the construction process of random forest is roughly as follows:
from the original training focus Bootstraping method is used to back the sampling random select m sample, sampling conducted n_tree time, generate n_tree a training set for n_tree a training set, we respectively training n_tree a decision tree model for a single decision tree model, assuming that the number of training sample characteristics of n, so every time divided according to the information gain/information gain ratio/gini index, choose the best characteristics of split each tree has been divided like this, until all the training sample in the node belong to the same class. In the process of decision tree splitting, the random forest is composed of multiple decision trees generated without pruning. For the classification problem, the final classification result is decided by voting according to multiple tree classifiers. For regression problems, the mean of predicted values of multiple trees determines the final prediction result
Tensorflow study notes
tf.one_hot
This paper only serves as a personal learning record, please refer to tensorFlow Chinese official website TF Chinese official website
Call format
tf.one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None)
Parameters that
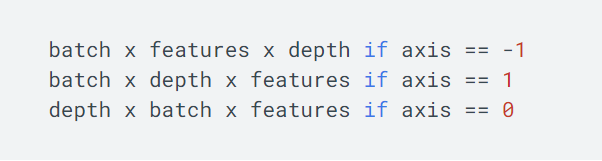
Indices: Tensors of an index. · depth: a scalar quantity defined in one_hot dimension · on_value: a set of indices[j] = I (default: 1) · off_value: a set of indices[j]! = I (default: 0) · axis: axis to be filled (default: -1, a new innermost axis) · dtype: the data type of the output tensor. · name: the name of the operation (optional).
The output
A one_hot tensor
A possible mistake
TypeError whether on_value or off_value does not match dtype. TypeError whether on_value and off_value do not match each other
prompt
indices location value is on_value, while the other location is off_value. The on_value and OFF_value data types must match. If dType has a value, they must take the same value as the type displayed by DTYPE. if on_value has no value, the default value is 1, and the output is dtype. if off_value has no value, the default value is 0, and the output is dtype. if the indices have N dimensions, the output is N+1. If the indices are scalars, the output is a vector with a length of depth. If the indices are tensor with features, the output will be: . If the indices are indices with batch size [batch, features], the output will be: . If the indices are RaggedTensor, the axis must be positive and form an axis which is hard to form. The output is equivalent to the output of one_hot applied with a value of an irregular shape, and a new irregular shape is generated from the result. if dtype has no value, it will try to assume that the data type is on_value or off_value if one or both pass. If on_value, off_value, dtype have no value, dtpye will default to be tf.float32. ** note: if output of non-numeric types (such as tf.string, tf.bool, etc), on_value, off_value all need to have a value.
Calling reindex will reorder the missing values and fill them with NaN.
se2=se1.reindex(['a','b','c','d','e','f'])
se2
Code results:
a 3.0
b NaN
c 7.0
d 1.0
e NaN
f 9.0
dtype: float64
When passing in method= “” select interpolation processing mode when reindexing:
Method = ‘ffill’ or ‘pad forward filling
Method = ‘bfill’ or ‘backfill’
TensorFlow Installation and Uninstallation (Anaconda version)
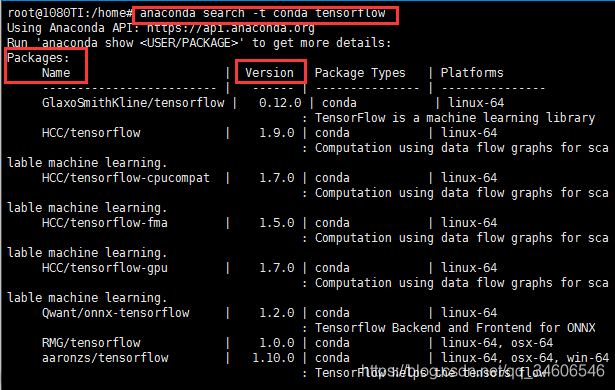
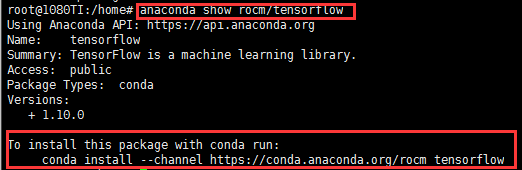
Anaconda can easily configure and set up the virtual environment. Generally, we can choose PIP Install or Conda Install to download and install the package. Here are the steps of Anaconda installation: 1, anaconda search-t conda tensorflow looks for the available tensorflow source. After this command is run, the terminal will output all available sources 2, anaconda show name . Here the name is the name of the tensorflow column of the output source in 1, and the show command will output the specific information of the source and download the required instructions at the terminal. such as:
1.6 Is the version number, which can be set according to its own requirements.
In addition, you can choose the available channel channel without so much trouble to search package name, and you can directly use the conda command:
Conda install tensorflow – gpu = 1.6
Conda automatically selects the available channels.
1, conda list/ PIP list view package installation information in the environment 2, PIP uninstall ‘name’, name is the name of the specified package for example:
First, you need to find python27\Scripts with the CMD command, download and install PIP, and if you have, install pillow and image directly;
Next, we will find that the “from PIL import Image” in Pycharm still reports an error. Next, we will click file-& GT; settings-> Project Interpreter, double-click PIP, search Pillow, click Pillow, and there will be Install in the lower left corner, and the installation is successful.
As for pillow’s installation, please refer to the following one, but I personally think it can be installed directly in File -> settings-> Search the Pillow and Image installation in the Project Interpreter
PIL: Python Imaging Library is already the DE facto standard Library of image processing for the Python platform.
However, when we do image processing, we will report the exception of PIL in No Module Named. There is no library for image processing. Since Python2.7 doesn’t ship with the library, we’ll have to load and manipulate it ourselves. However, there is a lot of information on the Internet, no specific explanation. To save everyone time and not to be misled, I’ll write down the complete solution.
1. Install easy_install
Why install easy_install? normally, to install a third-party extension for Python, you download the package, unzip it to a directory, open it at the command line or terminal, and then execute Python setup.py install to install it. It’s very tedious. It’s convenient to wrap Twisted if we run easy_install Twisted directly from the command line. So easy_install is meant to make it easier for us to install third-party extensions.
Easy_install download path: https://github.com/ActiveState/ez_setup
Unzip the package, open the command line, and execute Python ez_setup.py
2. Install the PIP
Installing the Python package is indeed the most convenient and quick way to install PIP, because it downloads files directly from PyPI, ensures security and reliability, and is rich in resources. PIP is a tool for installing and managing Python packages.
Download path: https://github.com/pypa/pip
Unzip the package, open the command line, and execute Python Setup.py install
Normally, it should be unzipped in your Python installation path, just for the sake of illustration. After PIP is installed, there is a scripts folder under our Python installation path, and we need to configure PIP’s environment variable, which is too easy to configure, So I won’t show you.
3. The next step is to install PIL
Download path: http://www.lfd.uci.edu/~gohlk/Python libs
Before installing PIL, we need to install the wheel package. Wheel is essentially a compressed format package. Installation of python modules.
Execute PIP Install wheel from the command line, because I’ve already installed it and it doesn’t show up very well.
Next, we can install our PIL. Execute PIP Install Lion-4.1.0-cp27-cp27m-win_amd64.WHl
Because I’ve already installed it, I can’t show it well. When we install PIL successfully, it will prompt Successfully.
Let me show you how to install the WHL file:
If you add the D:\Python27\Scripts directory to your path, you can just open a CMD window with the administrator in the directory where the WHL file is located and execute the following statement directly. WHL
PIP install clip-4.1.0-cp27-cp27m-win_amd64. WHL
otherwise, you will need to run the PIP command in the D:\ pyth27 \Scripts directory with the administrator open CMD, The file name should be written to the full path)
PIP install C:\Users\ XXX \Downloads\ cites-4.1.0-cp27-cp27m-win_amd64. WHL
4. Installation is complete
So far, our PIL module has been successfully installed. We will be able to use it in python2.7.
To introduce PIL, the code is from PIL import Image.
5. At the end
Although python2.7 and python3.0 are not very different from each other, compatibility issues are unavoidable. For example, there is built-in PIP above 3.0, and not at 2.7. So we’re going to do the operation. But since I’m used to using python2.7, I need to download files and operations. Hopefully this article will help you who are still using python2.7.
Welcome to visit the personal homepage, the current traffic is too low, Baidu search can not say… Thank you for encouraging reading notes. Instead of translating the full text, I plan to share the important knowledge points in the book with my own understanding, and attach the application of R language related functions at the end, as a summary of my recent learning in machine learning. If you don’t understand correctly, please correct me.
preface
ISLR, fully known as An Introduction to Statistical Learning with Applications in R, is a basic version of the Elements of Statistical Learning. The formula derivation in ISLR is not much, but mainly explains some commonly used methods in Statistical Learning and the application of relevant methods in R language. The ISLR doesn’t officially have the answers to the problem sets, but someone has created one, and you can learn from the ISLR answers
Chapter 4 Understanding
This chapter explains three methods of classification. 1. Logistic Regression(Logistic Regression) 2. Linear Discriminant Analysis 3. Quadratic Discriminant Analysis
The four categories are analyzed and compared one by one. 1.Logistic Regression
Formula:
The log (1 – p (x) p (x) = 0 + beta beta 1 x1 + beta 2 x2 +…
among them,
p(x)
Is the probability of belonging to a certain anomaly, is the final output,
Beta.
Is a parameter in Logistic Regression, and the optimal solution is generally obtained by the method of maximum likelihood. The general fitting curve is as follows:
Generally speaking, LOGICAL regression is suitable for the classification of two kinds of problems, and Discriminant Analysis is generally used for the classification of more than two kinds of problems.
2.Linear Discriminant Analysis
In fact, the discriminant method is to add the assumption that the model distribution follows the normal distribution on the basis of the original Bayesian theory. In the linear discriminant, it is assumed that the covariance of different variables is the same
The ellipse in the left figure is the normal distribution curve, and the boundary line intersected by two sides forms the classification boundary, while the real line in the right figure is the Bayesian estimation, which is the actual boundary line. It can be found that the accuracy of the linear discriminant method is still very good.
3.Quadratic Discriminant Analysis(Quadratic Discriminant)
The only difference between a quadratic discriminant and a linear discriminant is that you assume that the covariances of different variables are different, and that causes the dividing line to be curved on the graph, and you take the degrees of freedom from
p(p+1)/2
Increased to
Kp(p+1)/2
K is the number of variables. The effect of increased freedom can be seen in reading Notes (1).
The purple dotted line represents the actual boundary, the black dotted line represents the linear discriminant boundary, and the green solid line represents the quadratic discriminant boundary. It can be seen that the linear discriminant performs better when the boundary is linear; When the dividing line is nonlinear, the opposite is true.
4. To summarize
When the actual dividing line is linear, the linear discriminant performs better if the data is close to the normal distribution hypothesis, and the logistic regression performs better if the data is not close to the normal distribution hypothesis. when the actual boundary line is nonlinear, the quadratic discriminant will be fitted. In other higher order or irregular cases, KNN performs well.
R language application
1. Import data and prepare
Since KNN is to be used later and distance is needed, the variables are normalized. The normalization program is just one sentence, and the normalization effect is shown in the following sentences.
> qda.fit = qda(Purchase~.,data = Caravan, subset = -test)
Error in qda.default(x, grouping, ...) : rank deficiency in group Yes
> qda.fit = qda(Purchase~ABYSTAND+AINBOED,data = Caravan, subset = -test)
Found that direct training can cause errors… The two variables have been tried successfully. It seems that the dimension is too high, so far no solution has been found. Other applications are similar to LDA
5.KNN parameter k can be selected by itself, and the input order of KNN function variables should be noted
Once the Python installation under Windows is complete, several exe files are generated under the Python installation directory scripts, including easy_install and PIP,
We add the above path to the system environment variable after normal conditions
You can use tools such as easy_install, but on 64-bit systems you will get errors like the following:
C:\Python27\Scripts> easy_install sqlalchemy Fatal error in launcher: Python27\python.exe “”C:\Python27\Scripts\easy_install. Exe” sqlalchemy is not consistent with the default python installation path in the tool when using tools such as easy_install, so we need to explicitly call python to install:
Python -m easy_install sqlalchemy — — — — — — — — — — — — — — — — — — — — — the author: HymanLiuTS source: CSDN: the original https://blog.csdn.net/hyman_c/article/details/52755628 copyright statement: this article original articles for bloggers, reproduced please attach link to blog!
Recently opened up The jupyter notebook found kernel error [kernal error] FileNotFoundError: [WinError 2] The system cannot find The file specified, turned out to be I used conda to delete some environment at noon, so involved in this jupyter, may be The path problem, resulting in The file cannot be found. Finally, a solution was found:
Run in CMD:
After data cleaning with packages like Numpy and Pandas, the corresponding columns in dataframe will be fed into models such as neural network or SVM as features or labels for model training. During this process, errors as shown in the question are likely to be encountered, such as:
X=data[features]
Y=data['6A']
The error was reported as follows: was modified as follows: