Pandas apply returns multiple columns
Originally, I wanted to process the dataframe line by line through NP. Vectorize() and return several new fields. An error valueerror: setting an array element with a sequence
def test():
arr = np.random.randn(4,4)
cols = ['a', 'b', 'c']
df = pd.DataFrame(data=arr,columns=['e','f','g','h'])
def func(a,b,c):
output1 = a+1
output2 = b*2
output3 = c-4
return pd.Series([output1,output2,output3])
vfunc = np.vectorize(func)
df[cols] = vfunc(df['e'],df['f'],df['g'])
print(df)
test()
The reason for the error is that the assigned DF [cols] is inconsistent with the dimension returned by vffunc, and the shape between the returned data frame and the result does not match. Use apply to solve it, and the parameter result_ Type = “expand” means that the result will be converted into columns, and each returned value will be used as the value in the column of result dataframe. In apply (func), the number of results returned by func should be the same as the number of col columns in DF [col]
def test():
arr = np.random.randn(4,4)
cols = ['a', 'b', 'c']
df = pd.DataFrame(data=arr,columns=['e','f','g','h'])
def func(row):
a,b,c = row['e'],row['f'],row['g']
output1 = a+1
output2 = b*2
output3 = c-4
return output1,output2,output3
df[cols] = df.apply(func,axis=1, result_type="expand")
print(df)
test()
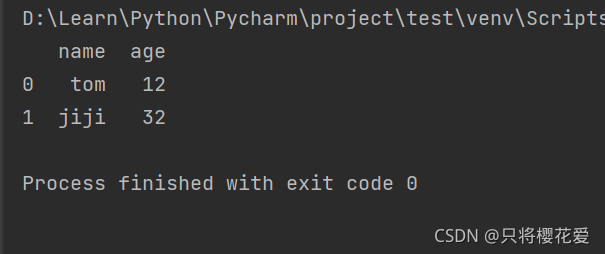
output
e f g h a b c
0 0.493280 -0.092513 -3.014135 -0.361842 1.493280 -0.185027 -7.014135
1 0.300695 -0.745392 0.591653 -1.752471 1.300695 -1.490785 -3.408347
2 -0.033944 -1.556307 -0.359979 1.808213 0.966056 -3.112615 -4.359979
3 0.701741 -0.272337 0.041114 0.150049 1.701741 -0.544674 -3.958886
For a single column
df['id']
And
ID = ['id']
df[ID]
The results obtained are different. The former is [1,2,3,4], and the latter is [[1], [2], [3], [4]
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html