Cannot find /usr/local/tomcat/bin/setclasspath.sh
This file is needed to run this program
After trying, use the add command packaged with dockerfile
RUN unset CATALINA_HOME
Invalid after attempt
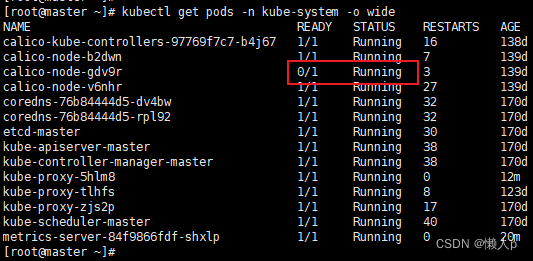
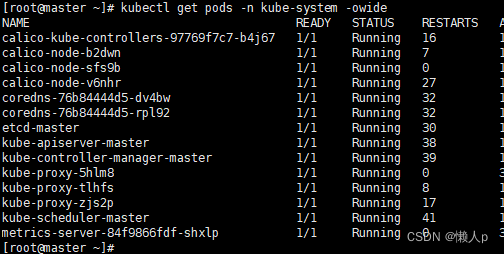
The prompt is that setclasspath.sh cannot be found, because this Tomcat restarts repeatedly
So use the command to copy a bin directory to the current folder
docker cp Docker_id:/usr/local/tomcat/bin ./
The result shows that setclasspath.sh exists, so where is the problem? Look for the error reporting code
In the catalina.sh script, the part causing the problem is as follows:
if [ -r "$CATALINA_HOME"/bin/setclasspath.sh ]; then
. "$CATALINA_HOME"/bin/setclasspath.sh
else
echo "Cannot find $CATALINA_HOME/bin/setclasspath.sh"
echo "This file is needed to run this program"
fi
The square brackets plus the -r command means to test whether the file is read-only. Similarly, – x tests whether the file is executable
In the problematic system, the – R command call in the container is abnormal.
Try to start a temporary tomcat8 authentication,
docker run -it --rm --entrypoint=/bin/bash tomcat:8
Note: executing the docker run command with the –rm command option is equivalent to executing docker rm -v after the container exits
execute command
root@f338debf92f6:/usr/local/tomcat# [[ -r /bin/bash ]]
root@f338debf92f6:/usr/local/tomcat# echo $?
1
Executed on a normal system
root@0083a80a9ec2:/usr/local/tomcat# [[ -r /bin/bash ]]
root@0083a80a9ec2:/usr/local/tomcat# echo $?
0
The command ‘$?’ indicates the exit status of the previous command or the return value of the function
for exit status, 0 indicates no error, and any other value indicates an error. In general, most commands return 0 upon successful execution and 1 upon failure. Some commands return other values, indicating different types of errors.
How to solve it
this is related to the faccessat2 system call. Due to the bug in runc, if your kernel does not support faccessat2, it will fail. There is an article saying that upgrading the kernel to 5.8 or above may work well, but I have tried it hard, because the kernel with the problem is 5.10
Method 1: update runc >= 1.0.0-rc93
Method 2: — privileged switch to run the container
Specific implementation of method 1:
View the original runc version
runc -v
Download version 1.0.0-rc95 of runc.amd64
Download address: releases · opencontainers/runc · GitHub
Name change and Execution Authority
mv runc.amd64 runc && chmod +x runc
View and back up the original runc
whereis runc
Some systems are in the /usr/bin/ directory, some systems are in the /usr/local/bin/ directory, the following commands are in the /usr/local/bin/ directory, the following commands are in the /usr/bin/ directory, change the directory yourself
mv /usr/local/bin/runc /usr/local/bin/runcbak
Overwrite the original runc
cp runc /usr/local/bin/runc
View the new version of runc
runc -v
Restart docker
systemctl restart docker
Method 2: concrete implementation
Docker run execution
docker run --privileged=true -p 8080:8080 tomcat:8
Add in docker-compose.yml
version: '2'
services:
tomcat:
container_name: tomcat
image: tomcat:8
ports:
- '8080:8080'
environment:
- TZ=Asia/Shanghai
privileged: true
restart: always