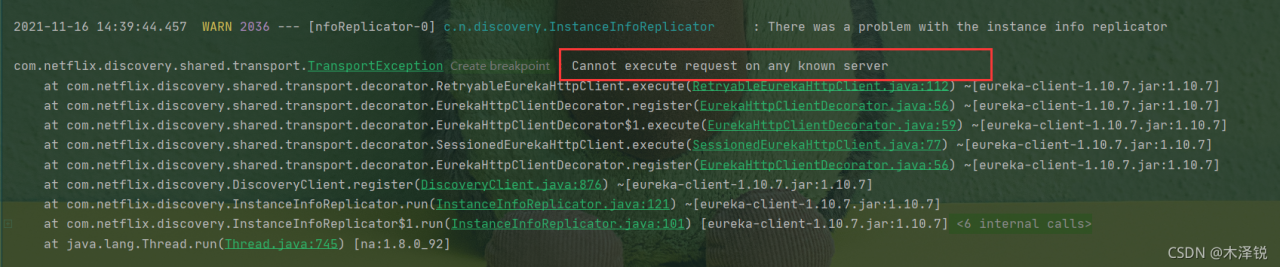
While installing a Kubernetes local cluster, I happened to encounter the following problem:
E0514 07:30:58.627632 1 cacher.go:424] cacher (*core.Secret): unexpected ListAndWatch error: failed to list *core.Secret: unable to transform key “/registry/secrets/default/default-token-nk77g”: invalid padding on input; reinitializing…
W0514 07:30:59.631509 1 reflector.go:324] storage/cacher.go:/secrets: failed to list *core.Secret: unable to transform key “/registry/secrets/default/default-token-nk77g”: invalid padding on input
E0514 07:30:59.631563 1 cacher.go:424] cacher (*core.Secret): unexpected ListAndWatch error: failed to list *core.Secret: unable to transform key “/registry/secrets/default/default-token-nk77g”: invalid padding on input; reinitializing…
W0514 07:31:00.633540 1 reflector.go:324] storage/cacher.go:/secrets: failed to list *core.Secret: unable to transform key “/registry/secrets/default/default-token-nk77g”: invalid padding on input
E0514 07:31:00.633575 1 cacher.go:424] cacher (*core.Secret): unexpected ListAndWatch error: failed to list *core.Secret: unable to transform key “/registry/secrets/default/default-token-nk77g”: invalid padding on input; reinitializing…
Reason:
We know that after running the cluster master, we need to create the TLS Bootstrap Secret to provide an automatic visa using.
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-${TOKEN_ID}
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
token-id: "${TOKEN_ID}"
token-secret: "${TOKEN_SECRET}"
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token
EOF
secret "bootstrap-token-65a3a9" created
where BOOTSTRAP_TOKEN=T O K E N I D . {TOKEN_ID}.TOKEN
I
D.{TOKEN_SECRET} can be found in bootstrap-kubelet.conf.
One of the reasons for the problem shown in the title is that the command may have been run multiple times and multiple secrets exist, e.g. the node side was found to be not working properly and a bootstrap-kubelet.conf was regenerated for it, etc.
Then when installing the kubernetes cluster manually, we will find that the online information is backward after all, so we will use the kubeadm post-installation information for comparison and verification, and then I accidentally added the following codes:
spec:
hostNetwork: true
priorityClassName: system-cluster-critical
securityContext:
seccompProfile:
type: RuntimeDefault
spec.securityContext.seccompProfile.type=RuntimeDefault, this setting will automatically generate a self-signed secret when the cluster is running, which will lead to a contradiction with the manual generation and the problem in the title.
Solution:
1) First clear the cluster cache, delete all files under /var/lib/etcd/ and /var/lib/kubelet/, and keep the config.xml file in the latter.
2) Delete the spec.securityContext.type=”seccompProfile” in /etc/kubernetes/manifests under kube-apiserver.yml, kube-controller-manager.yml and kube-scheduler.yml. seccompProfile.type=RuntimeDefault.
3) Re-run the kubelet: systemctl start kubelet and you are done.